

A method and system for distributed storage of gene variation data
A distributed storage and gene mutation technology, which is applied in chemical information database systems, chemical data mining, and chemical informatics data warehouses, etc., can solve problems such as high data maintenance costs, large data flow delays, and poor scalability, and achieve high The effect of batch processing efficiency, reduction of data redundancy, and good random read ability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0048] In order to make the object, technical solution and advantages of the present invention clearer, the present invention will be further described in detail below in conjunction with the accompanying drawings and embodiments. It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the present invention. In addition, the technical features involved in the various embodiments of the present invention described below can be combined with each other as long as they do not constitute a conflict with each other.
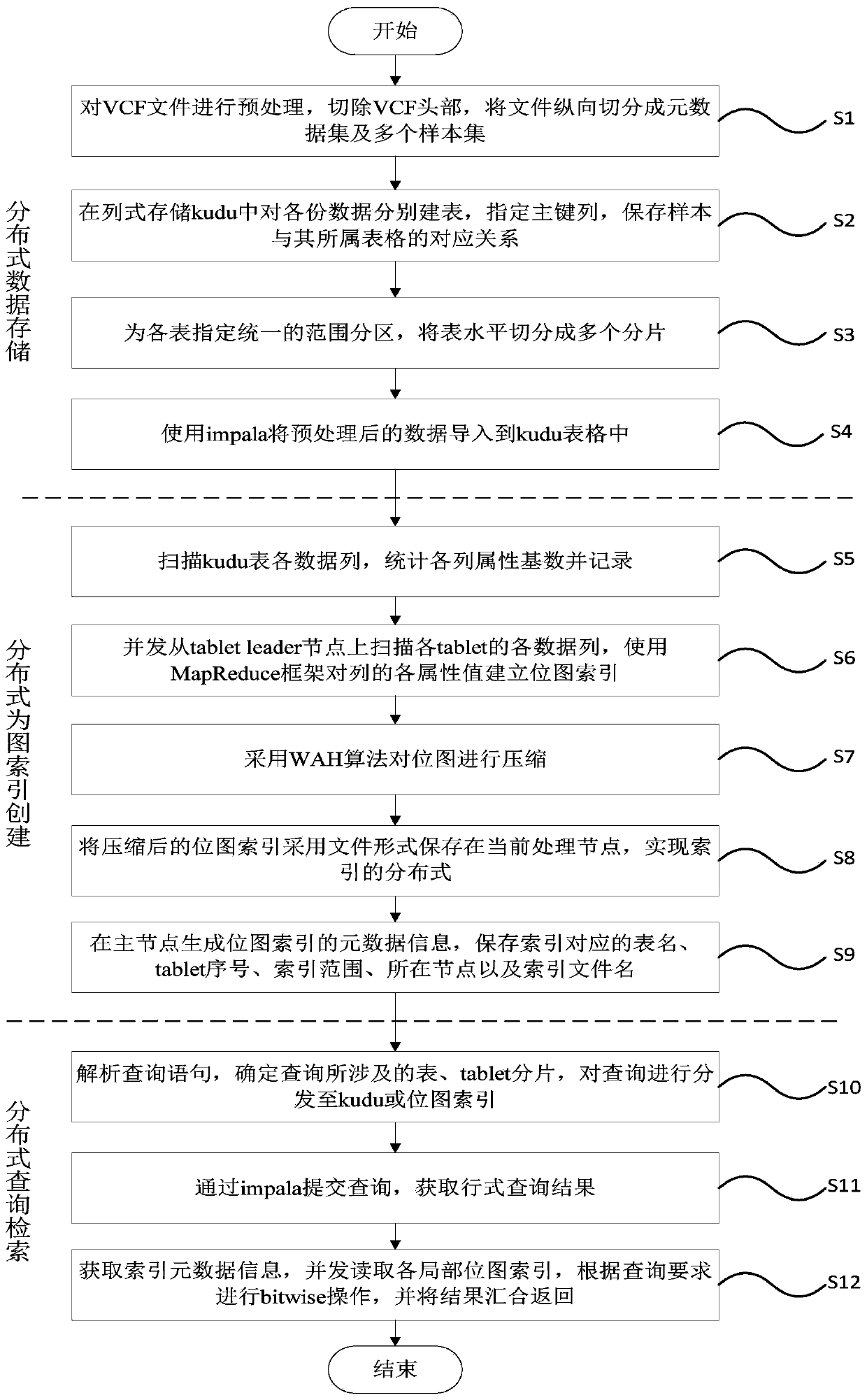
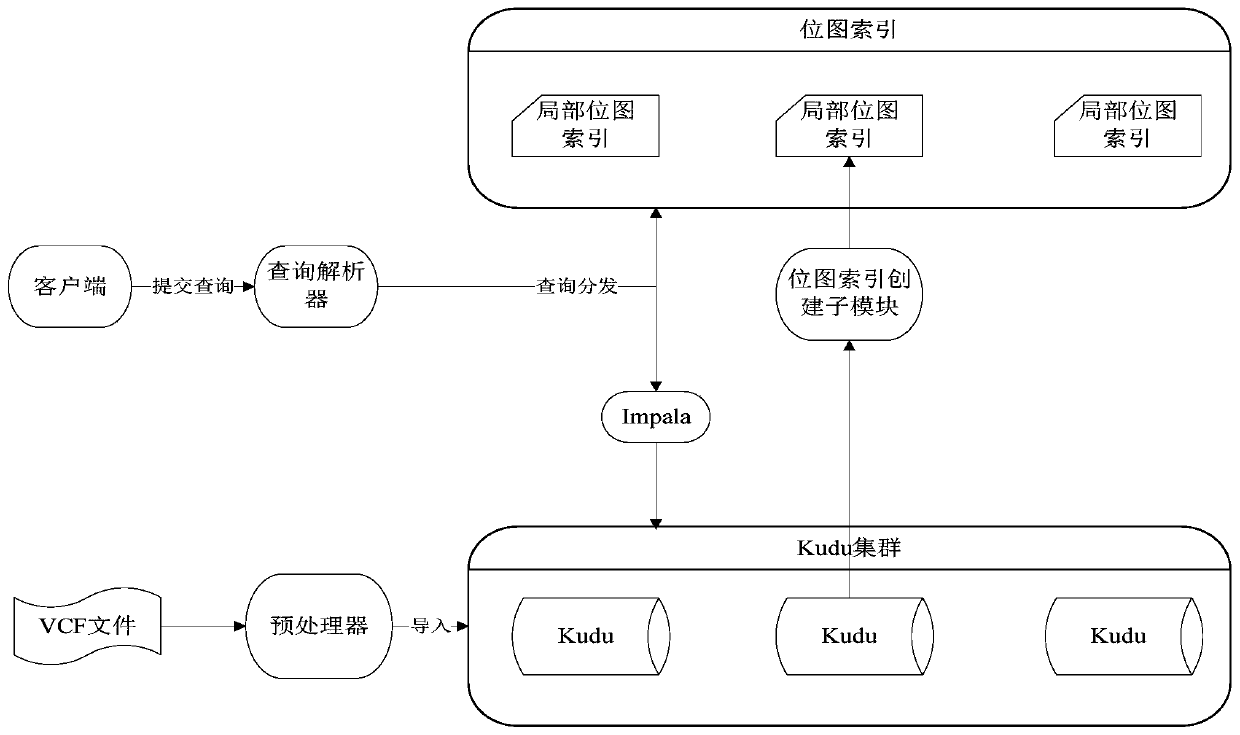
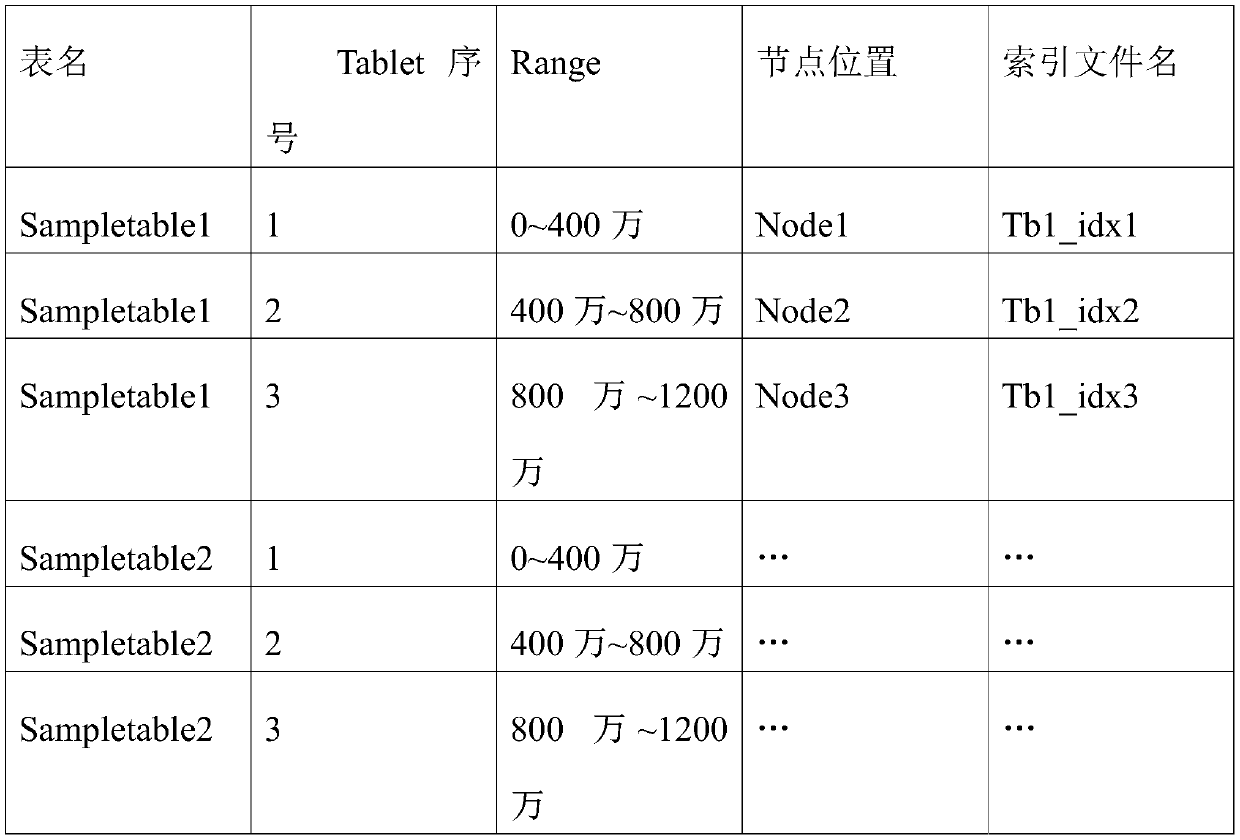
[0049] Such as figure 1 As shown, the genetic variation data distributed storage method provided by the present invention includes the following steps:
[0050] S1. Preprocess the VCF file, cut off the VCF head, vertically split the VCF file into two parts: metadata information and sample genotype information, and further vertically split the sample genotype data into more parts according to th...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More