

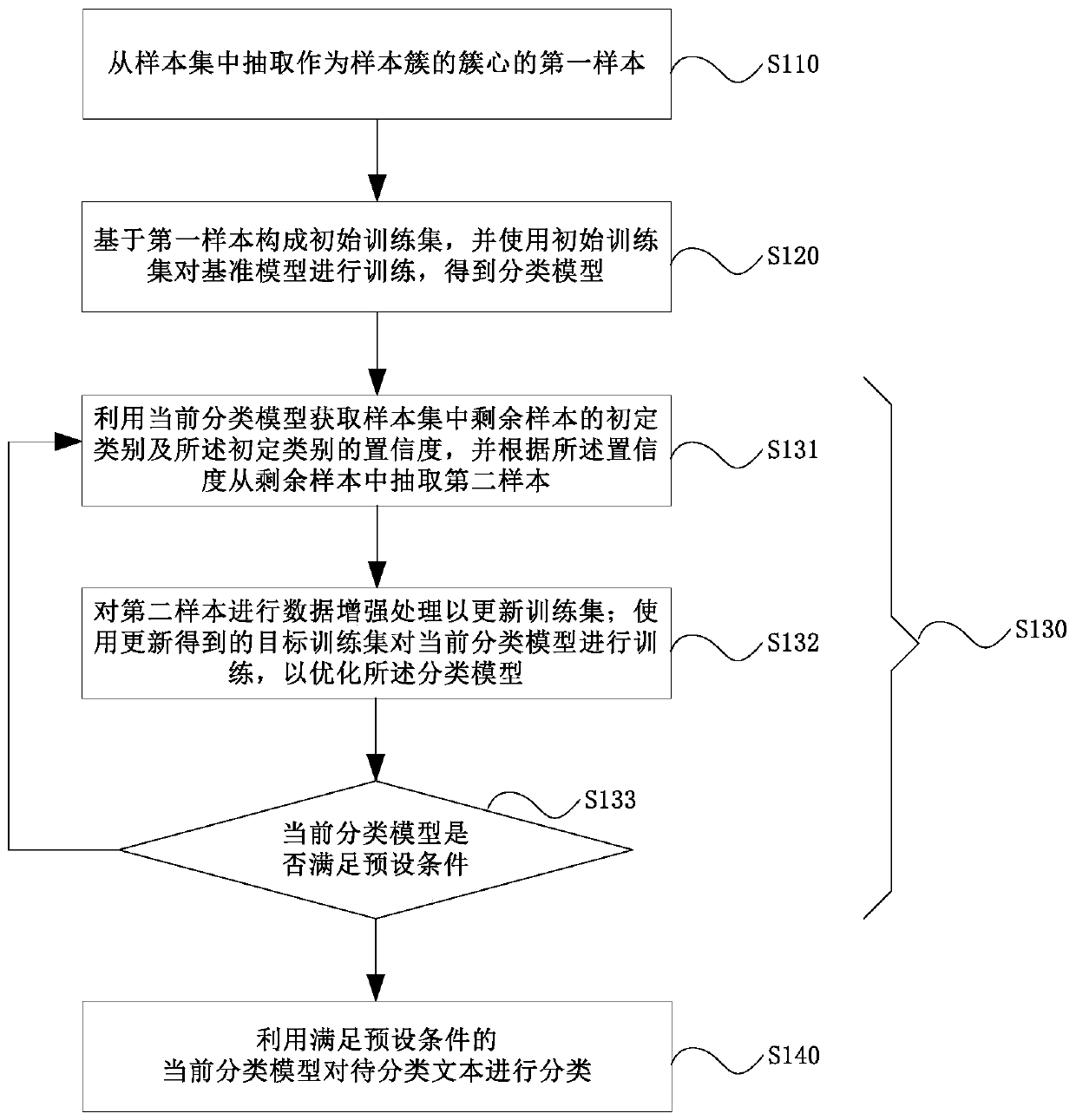
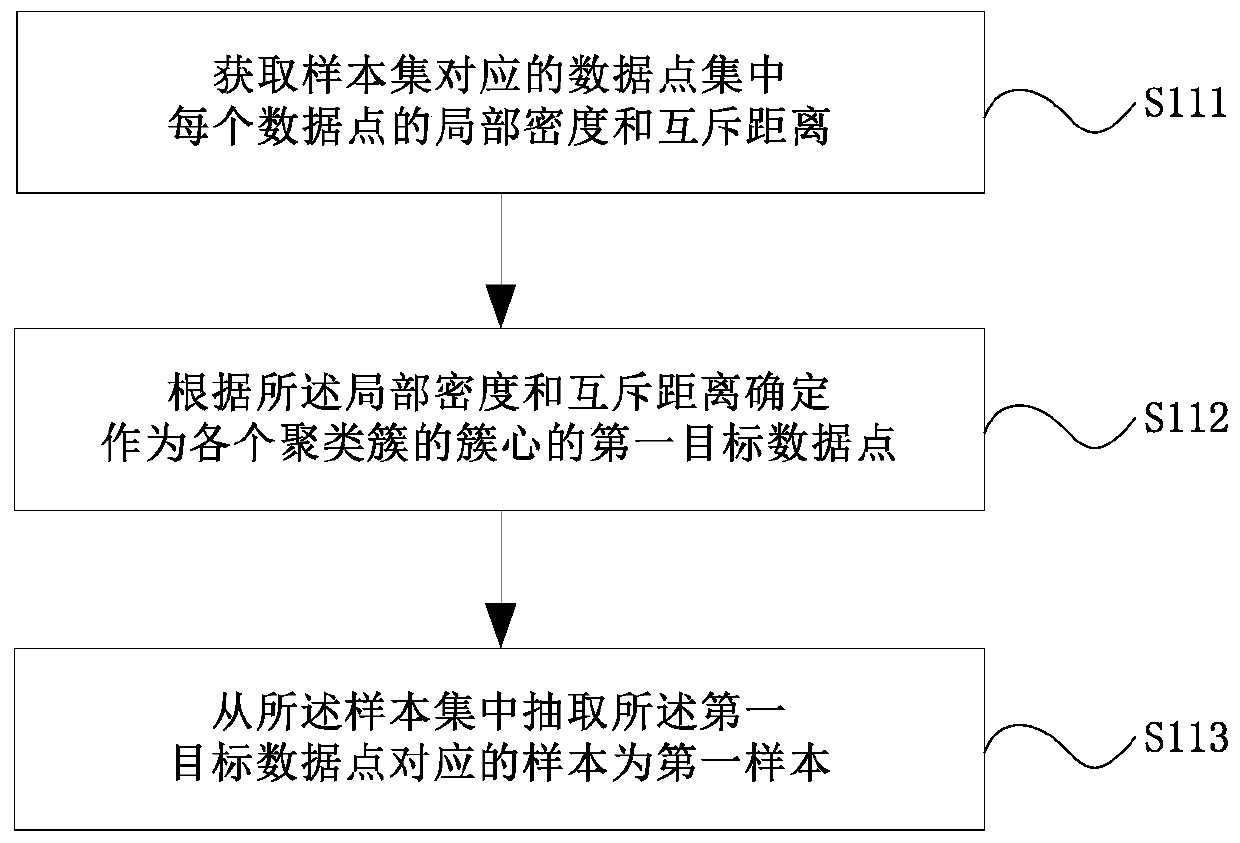
Weak supervised text classification method and device based on active learning
An active learning and text classification technology, applied in special data processing applications, instruments, electronic digital data processing, etc., can solve problems such as constraints on the efficiency and accuracy of text classification, difficulty in ensuring the quality of annotation, and low efficiency in the corpus annotation process. The effect of enriching sample semantic representation, expanding sample size, improving generalization ability and robustness
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
example 1
[0028] Example 1: I hope you keep this book, even if you grow up year after year, even if it sits on the shelf for a long time, gathering dust. As soon as you open it again, you'll be glad you didn't lose it.
[0029] In the field of natural language processing, corpus annotation is to add explanatory and symbolic annotation information to text corpus, such as category annotation, part-of-speech annotation, entity relationship annotation, word sense disambiguation, etc. Generally, annotated corpus carries annotation information, such as category tags, part-of-speech tags, etc., while unlabeled corpus does not contain such information. The samples in the sample set described in this application are unlabeled samples.
[0030] It should be noted that the embodiment of the present application uses category marking as an example to illustrate the idea and implementation of the technical solution of the present application, and the category marking does not constitute a limitation...
example 1-1
[0061] Example 1-1: I hope you keep this book, even if you grow up year after year, even if it sits on the shelf for a long time, gathering dust.
example 1-2
[0062] Example 1-2: As soon as you open it again, you'll be glad you didn't lose it.
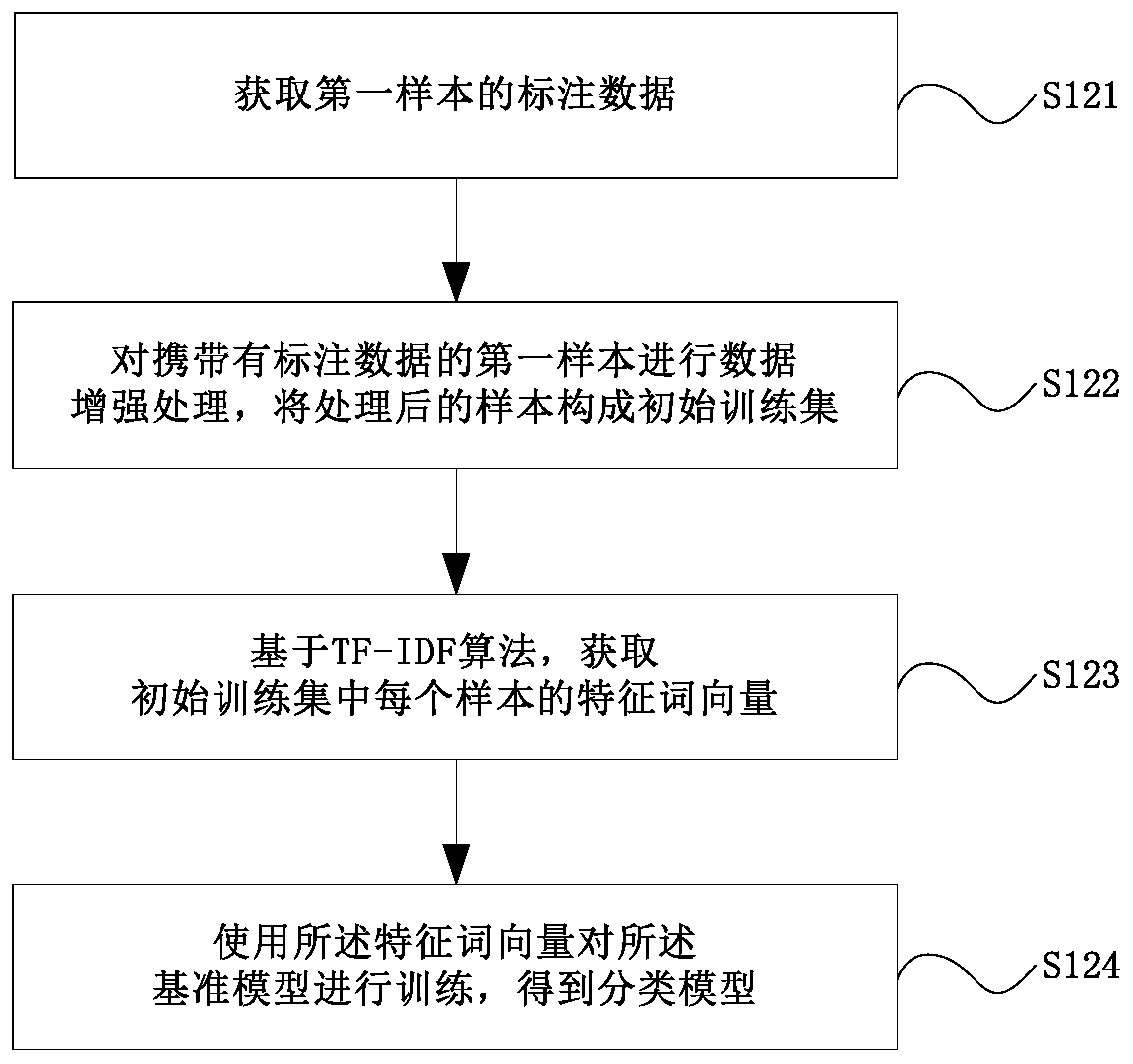
[0063] Then example 1-1 and example 1-2 will be used as two new samples to form the initial training set. Compared with Example 1, Example 1-1 and Example 1-2 are smaller in length, thus enriching the text granularity of the training set.
[0064] Step 123, based on the TF-IDF algorithm, obtain the feature word vector of each sample in the initial training set.
[0065] Based on the TF-IDF algorithm, calculate the category discrimination of each vocabulary in the sample relative to the sample to which at least one characteristic vocabulary is selected from all the vocabulary contained in the sample, and then use the pre-trained word vector model to obtain the vector representation of the characteristic vocabulary. That is, the feature word vector, which is a prior art well known to those skilled in the art, will not be described in detail in this embodiment.
[0066] Step 124, using the fe...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More