

Method, device, equipment and storage medium for extracting webpage information
An extraction method and web page information technology, applied in the field of computer networks, can solve the problems of long training time, consume a large amount of computing resources, increase labor costs, etc., and achieve the effect of reducing consumption and reducing node information
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
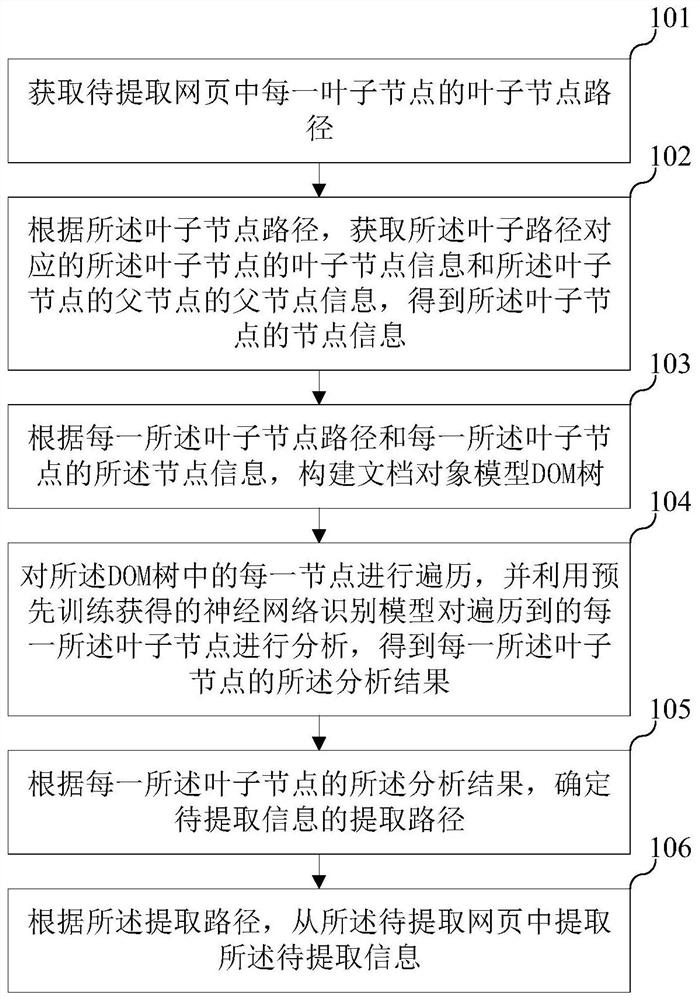
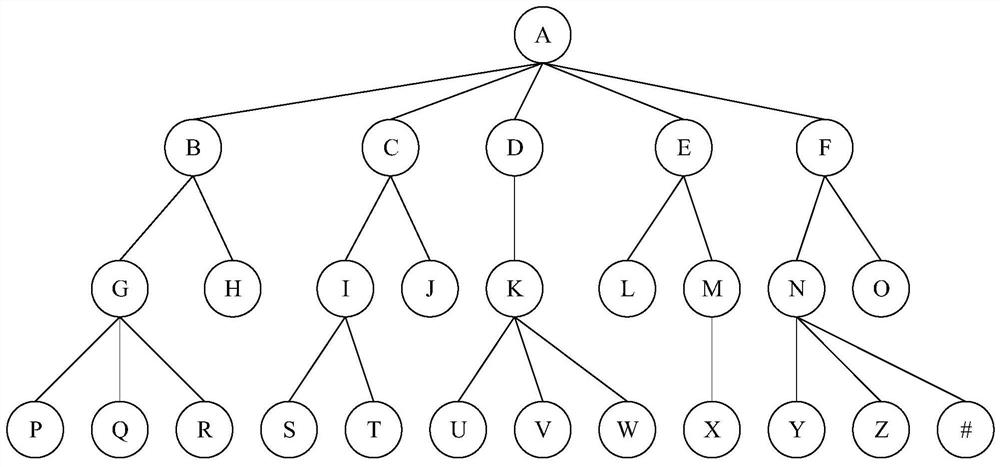
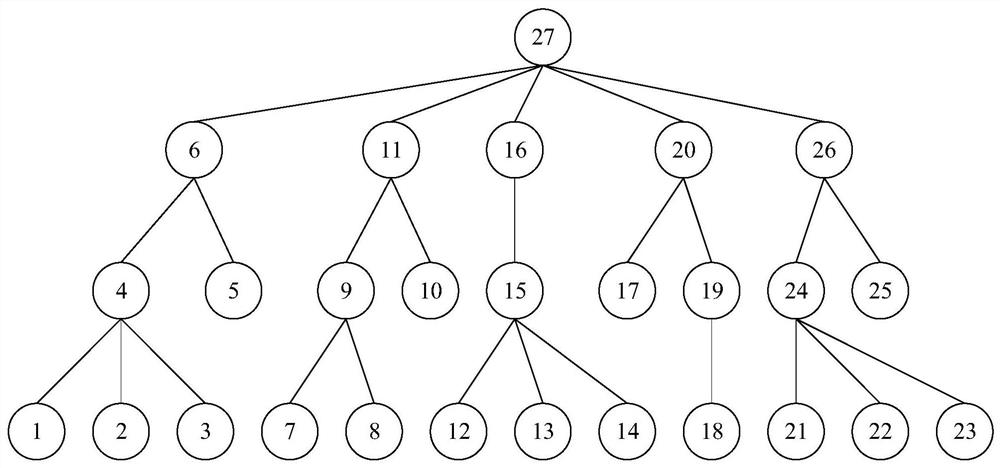
[0047] In order to make the purpose, technical solutions and advantages of the embodiments of the present invention clearer, the embodiments of the present invention will be described in detail below with reference to the accompanying drawings. However, those skilled in the art can understand that in each embodiment of the present invention, many technical details are provided for readers to better understand the present application. However, even without these technical details and various changes and modifications based on the following embodiments, the technical solutions claimed in this application can also be realized. The division of the following embodiments is for the convenience of description, and should not constitute any limitation to the specific implementation of the present invention, and the various embodiments can be combined and referred to each other on the premise of no contradiction.
[0048] The first embodiment of the present invention relates to a metho...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More