

Voice signal processing method, device and system
A voice signal processing and voice signal technology, applied in the field of communication, can solve the problems of limited, inability to effectively improve the efficiency of voice coding and compression, and reduce the transmission delay, so as to reduce coding bits, improve the efficiency of voice coding and compression, and reduce the transmission delay. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

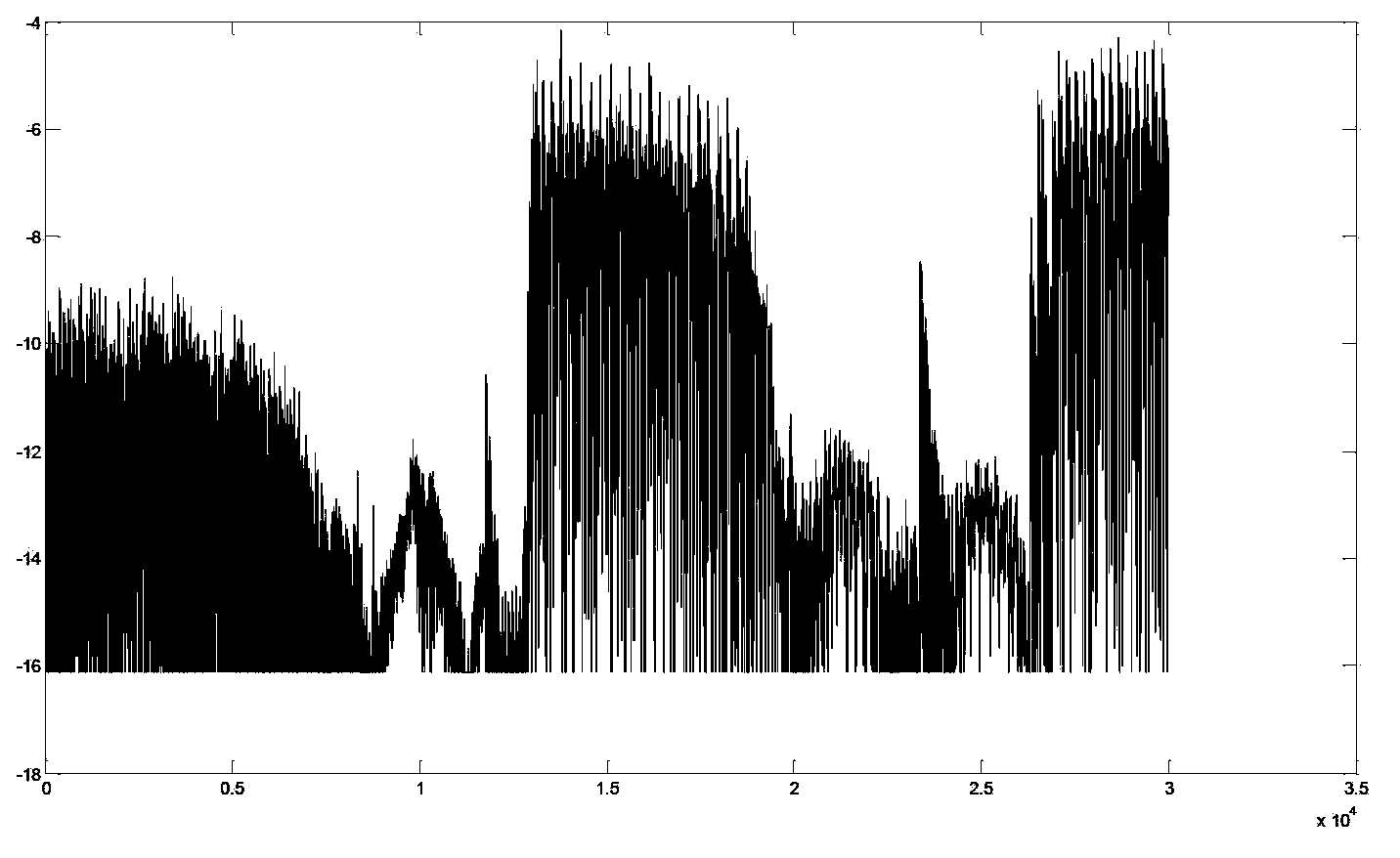
Examples
Embodiment 1
[0051] Embodiment 1 of the present invention provides a voice signal processing method, the step flow of the method can be as follows Figure 4 shown, including:
[0052] Step 101. Receive a speech signal to be encoded.
[0053] In this step, a speech signal to be encoded may be received, and the speech signal to be encoded includes at least two sampling signals.
[0054] Step 102, dividing sub-signals.
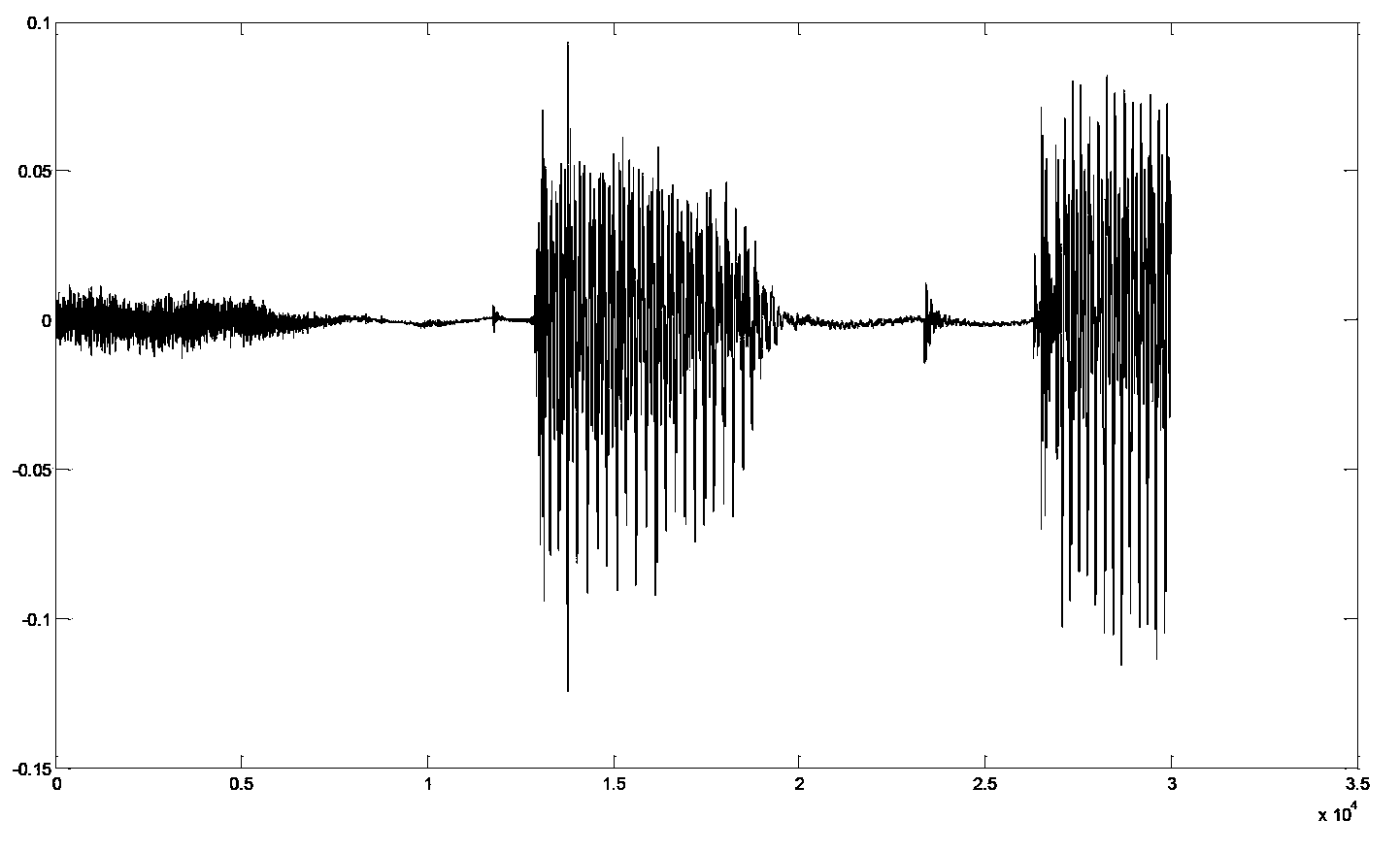
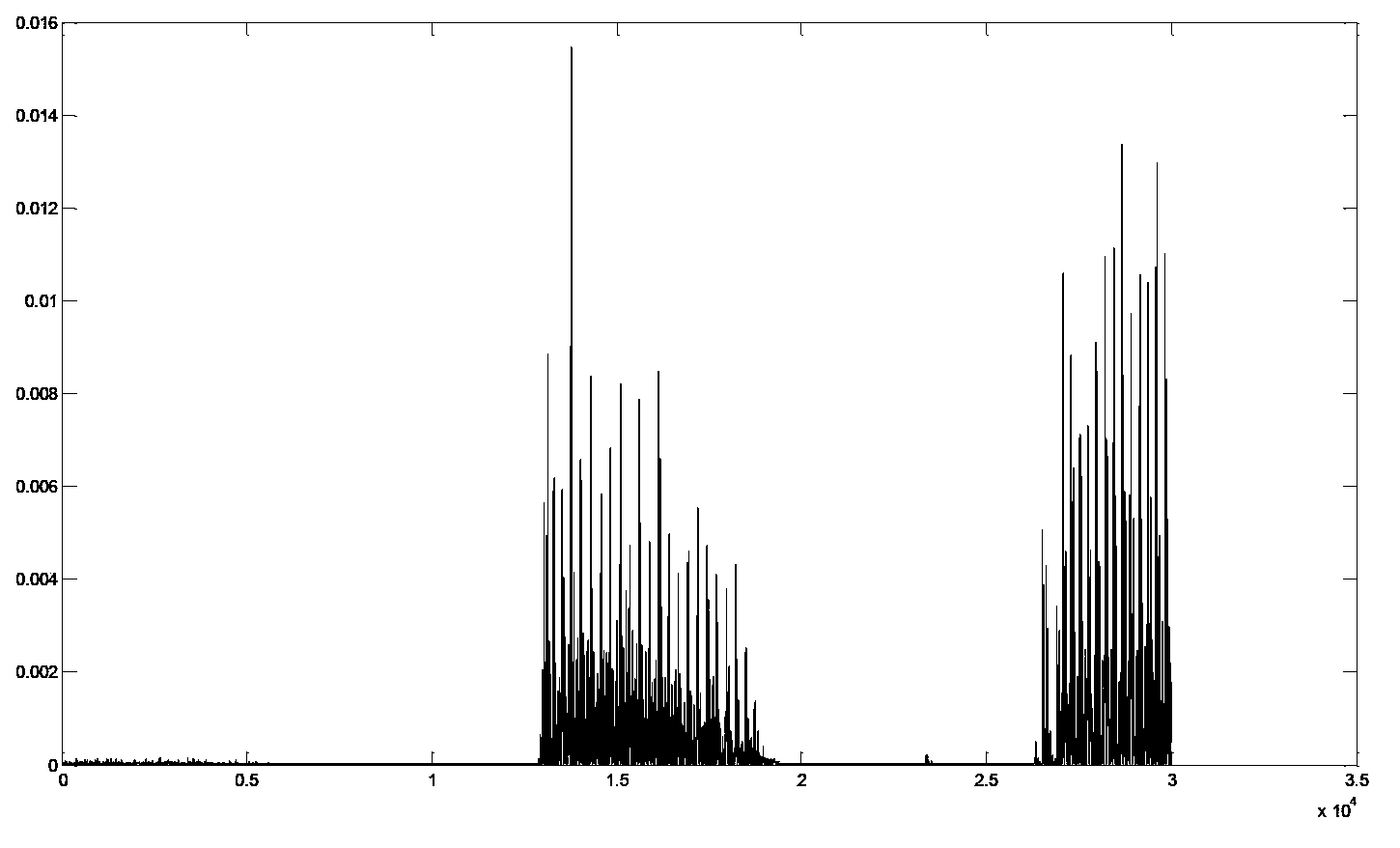
[0055] In this step, the speech signal to be encoded can be sequentially divided into sub-signals according to the number of sampling signals included in each sub-signal set, so that the speech energy of the divided sub-signals in the logarithmic domain can be used to characterize the speech The short-term energy of the signal. The number of sampled signals included in each of the set sub-signals may be determined according to training or empirical values.
[0056] Wherein, the number of sampling signals included in each sub-signal is set to be small enough to reflect cha...
Embodiment 2
[0089] The schematic diagram of the speech signal processing method provided by Embodiment 2 of the present invention can be as follows Figure 5 As shown, for the received speech signal to be encoded, the energy curve of the speech signal to be encoded in the logarithmic domain can be obtained, so as to obtain the energy envelope information of the speech signal to be encoded. In addition, the speech signal to be encoded can be divided into sub-signals, and the speech energy of each sub-signal in the logarithmic domain can be obtained, so that the frame length can be judged. After determining the sub-signals included in each speech frame (which can be interpreted as determining the sampling signal included in each speech frame) through the frame length determination, the speech signal to be encoded can be divided into frames and divided into multiple speech frames. And it can perform parameter / waveform / hybrid coding on each speech frame to obtain coding parameters. The final...
Embodiment 3
[0091] Embodiment 3 of the present invention provides a voice signal processing method, the step flow of the method can be as follows Image 6 shown, including:
[0092] Step 201, receiving information.
[0093] In this step, each speech frame encoded by the method as described in Embodiment 1 can be received, the sampling signal information included in each speech frame, and the energy envelope information (that is, the coded code stream in Embodiment 2) .
[0094] Step 202, perform decoding.
[0095] In this step, each encoded speech frame may be decoded according to the sampling signal information included in each speech frame.
[0096] Step 203, perform synthesis.
[0097] In this step, according to each decoded speech frame, the speech signal can be synthesized by using the energy envelope information. Thus, the speech signal to be encoded before encoding can be obtained.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More