

Lightweight multi-speaker voice synthesis system and electronic equipment
A speech synthesis, lightweight technology, applied in the direction of speech synthesis, speech analysis, instruments, etc., can solve the problems of large amount of calculation, slow synthesis speed, etc., to achieve the effect of speeding up synthesis speed, improving speed, and reducing model parameters
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
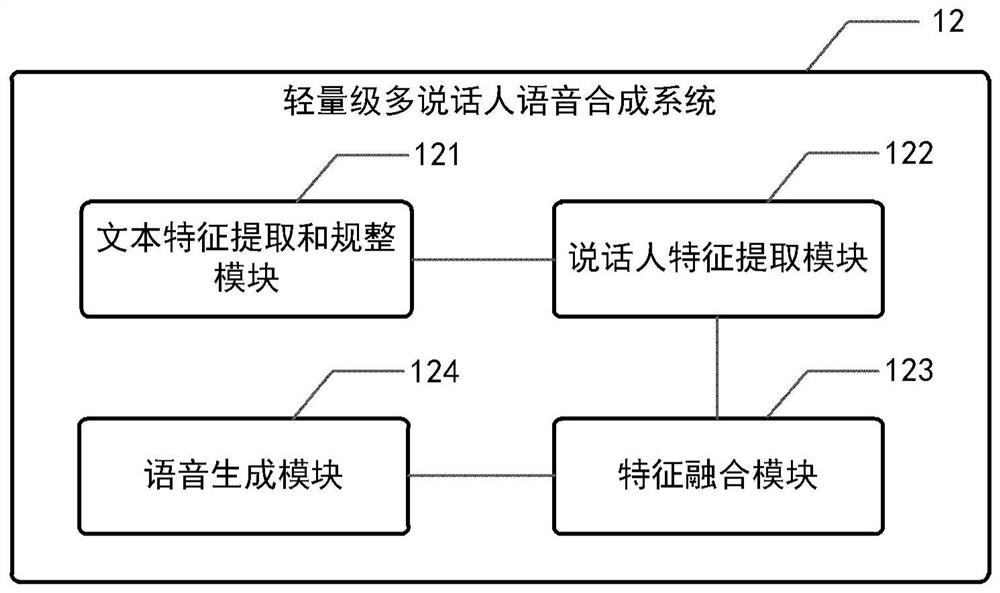
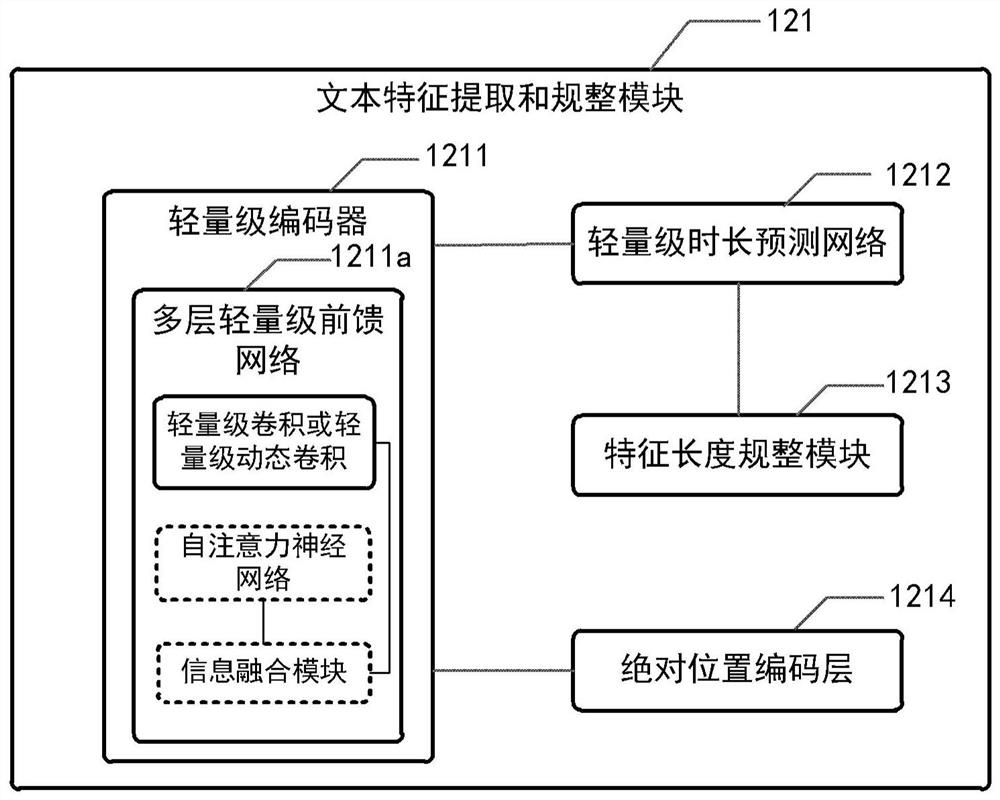
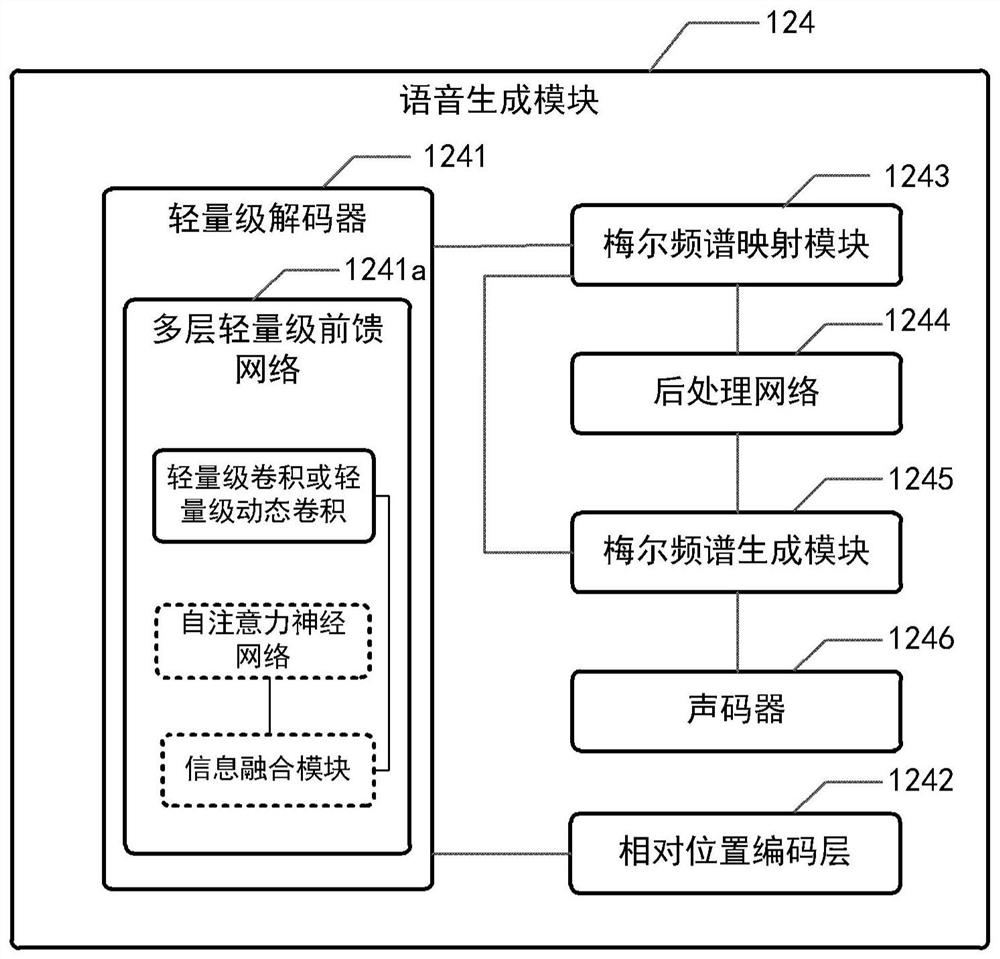
[0037] The inventor found the following technical problems in the prior art when implementing the technical concept of the present disclosure: (1) most of the existing end-to-end speech synthesis systems are autoregressive generative formulas that learn text-to-speech alignment relationships based on attention mechanisms The model and speech synthesis speed are slow, which affects the user experience of the actual landing product. (2) The non-autoregressive model FastSpeech extracts text features based on the self-attention mechanism. The computational complexity of this mechanism is the quadratic of the total length of the input text. The computational complexity is high and the memory resource consumption is large. (3) The non-autoregressive model FastSpeech currently can only synthesize the speech of a single speaker, and does not introduce any prosody-related speech information, which limits the personalized characteristics of the speech synthesis system and the expressiven...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More