

Chinese Web document online clustering method based on common substrings
A technology of common substring and clustering method, applied in the field of information processing, can solve the problem of poor Chinese information retrieval, and achieve the effect of retaining semantic components, avoiding the influence of thesaurus, and improving clustering performance.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

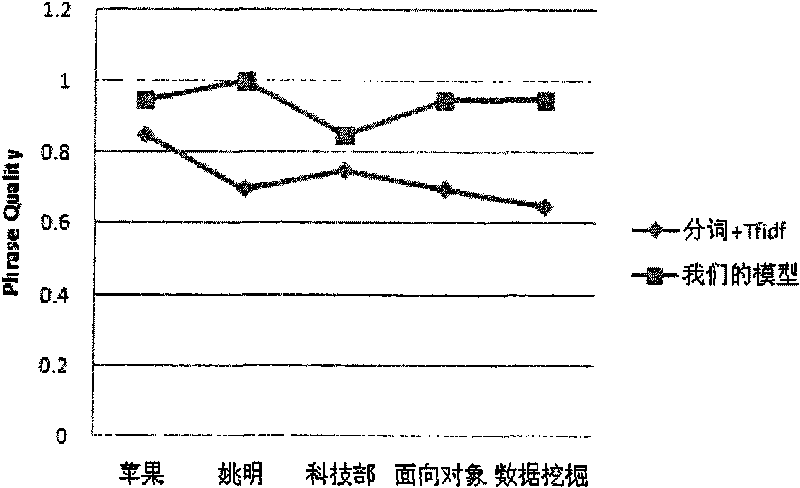

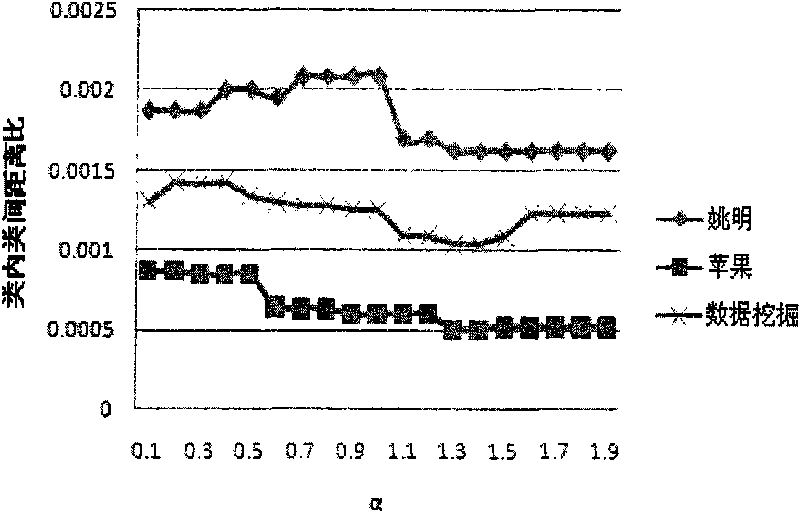
Examples
Embodiment Construction
[0039] 1. Web document preprocessing
[0040] In the returned results of Chinese search engines (such as Baidu, etc.), some non-Chinese characters are often contained, such as English characters, spaces, punctuation marks or garbled characters. Since the research focus of the present invention is the clustering of Chinese Web documents, it is necessary to replace the non-Chinese content in the search results before clustering.
[0041] The preprocessing stage mainly replaces these non-Chinese characters with the separators predefined by the system. The non-Chinese characters that need to be replaced mainly include: spaces, numbers, English uppercase and lowercase letters, Chinese and English punctuation marks (including full-width and half-width), and Chinese pause characters (for example: "ah", "de", "le", etc.). After preprocessing, search engine result items containing only Chinese characters will be obtained, which will be used as the input for common substring extraction...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More