

Similarity evaluation method of approximately duplicate records
A similarity and near-duplication technology, applied in the field of near-duplicate record identification under big data, can solve problems such as poor processing effect, and achieve the effect of overcoming inaccurate calculation, avoiding cost, and improving accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


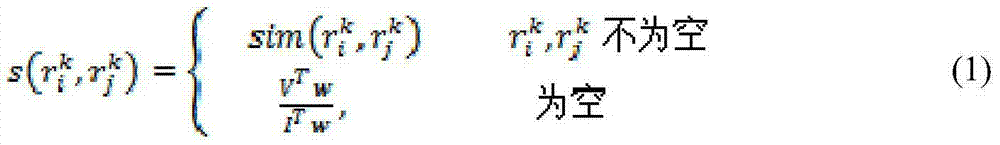
Examples
Embodiment Construction
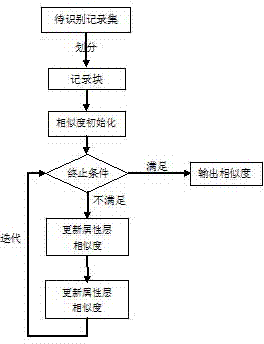
[0024] The present invention will be further described in detail in conjunction with the following specific embodiments and accompanying drawings. The process, conditions, experimental methods, etc. for implementing the present invention, except for the content specifically mentioned below, are common knowledge and common knowledge in this field, and the present invention has no special limitation content.
[0025] The definitions of the technical terms involved in the present invention are as follows:
[0026] A record is composed of some attributes to reflect an entity in nature, figure 2 An example graph showing a record containing a complex text type.
[0027] Attribute (attribute) is a part of the record, which is used to describe the inherent nature of the entity, and can also be called a field (field).
[0028] Deduplication refers to the operation of finding records pointing to the same entity in a record set.
[0029] Attribute level similarity refers to the simil...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More