

Method and system for realizing voice age and/or gender recognition service, and medium
A gender recognition and speech recognition technology, applied in speech recognition, speech analysis, instruments, etc., can solve the problems of difficult deployment, poor scalability, and difficult to modify.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
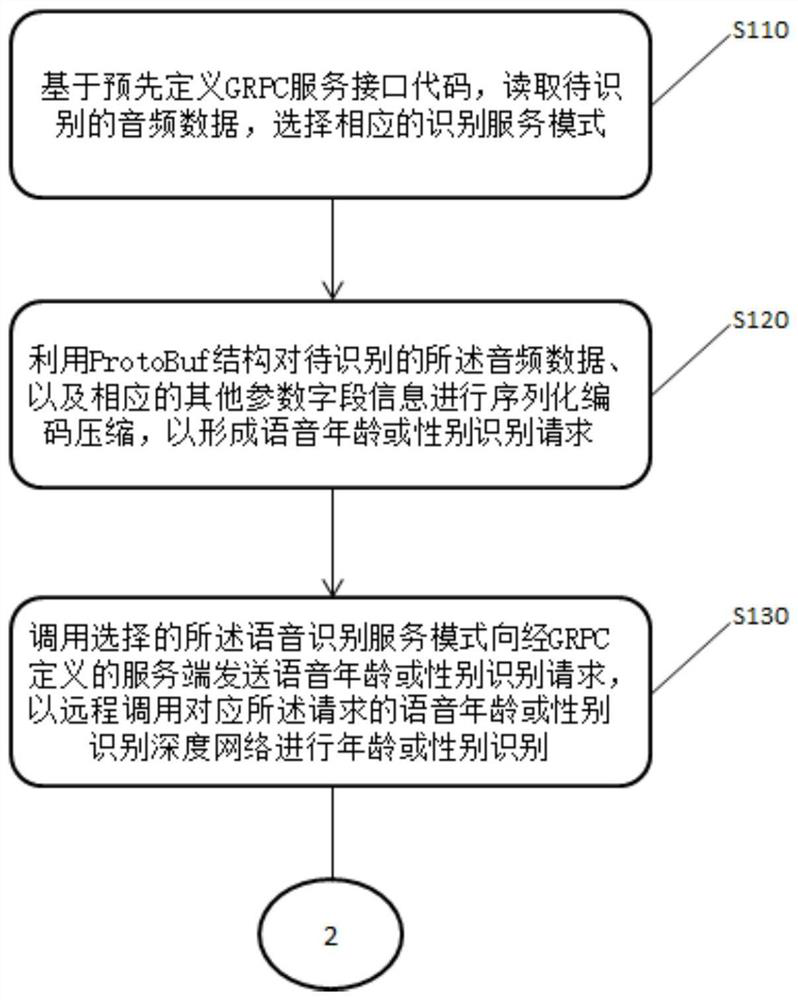
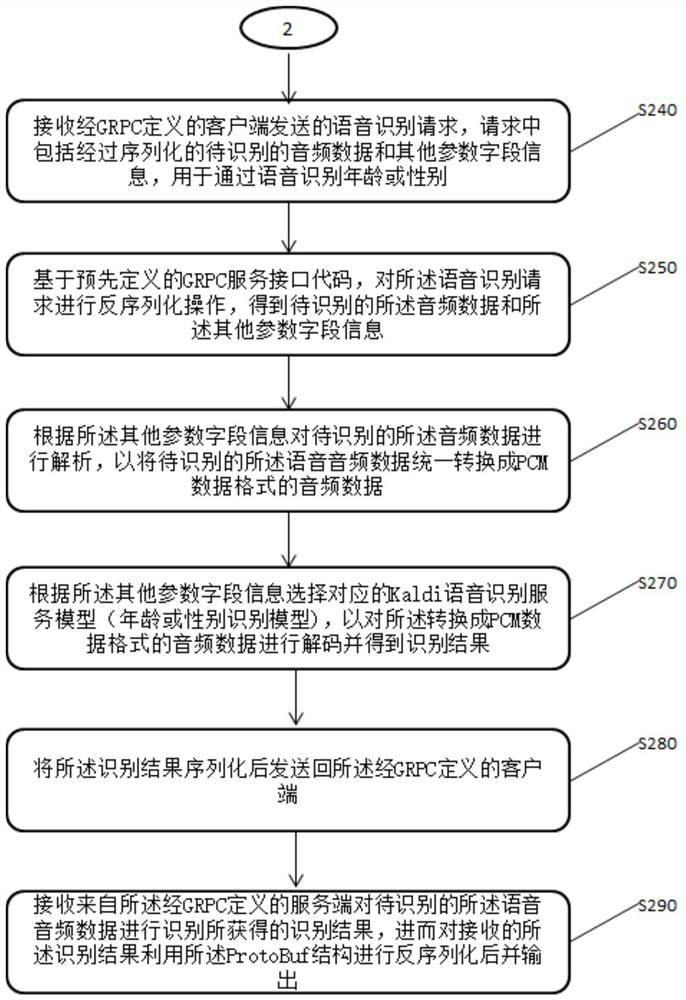
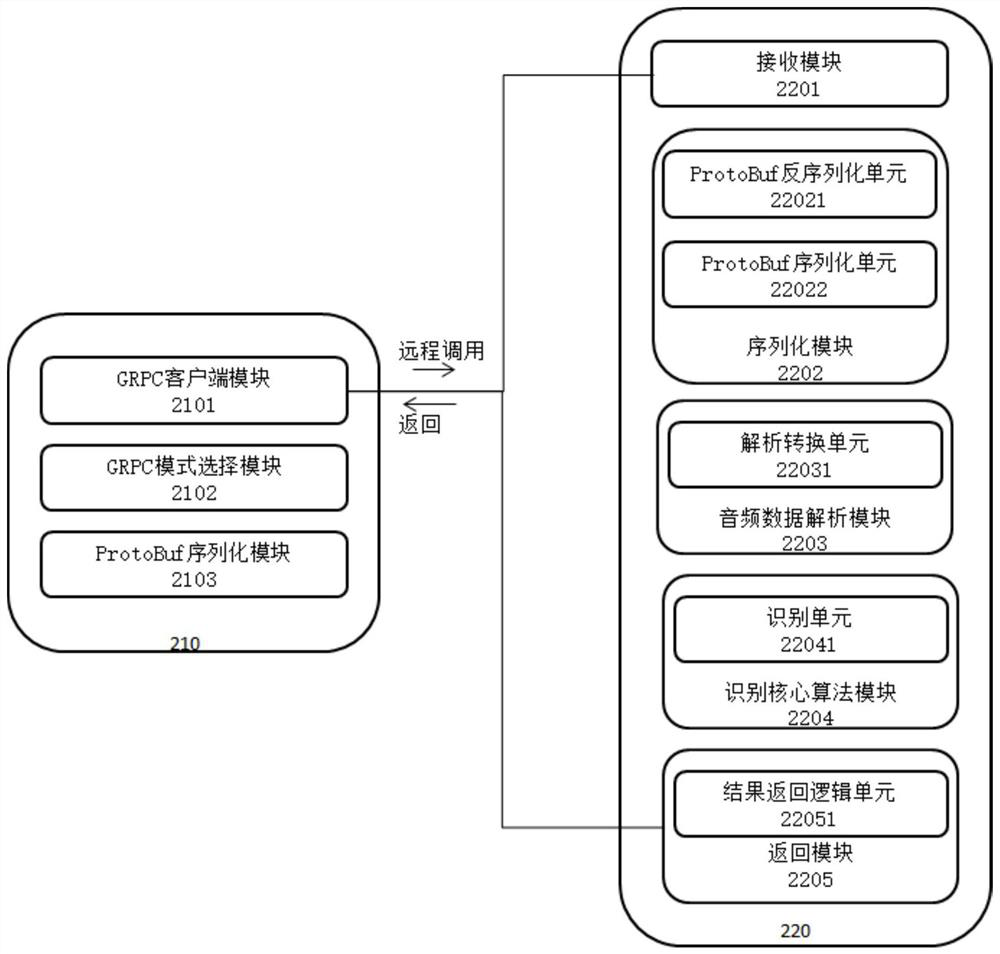
[0037] Some embodiments of the present invention are described below with reference to the accompanying drawings. Those skilled in the art should understand that these embodiments are only used to explain the technical principles of the present invention, and are not intended to limit the protection scope of the present invention.
[0038] In the description of the present invention, "module" and "processor" may include hardware, software or a combination of both. A module may include hardware circuits, various appropriate sensors, communication ports, and memory, and may also include software parts, such as program codes, or a combination of software and hardware. The processor may be a central processing unit, a microprocessor, an image processor, a digital signal processor or any other suitable processor. The processor has data and / or signal processing functions. The processor can be implemented in software, hardware or a combination of both. The non-transitory computer ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More