

Address text information correlation learning method based on data preprocessing
A technology of data preprocessing and text information, applied in the field of deep learning, can solve the problems of irregular address text, unbalanced number of training set samples, etc., so as to increase comprehension, alleviate the unbalanced number of samples, and improve generalization ability. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

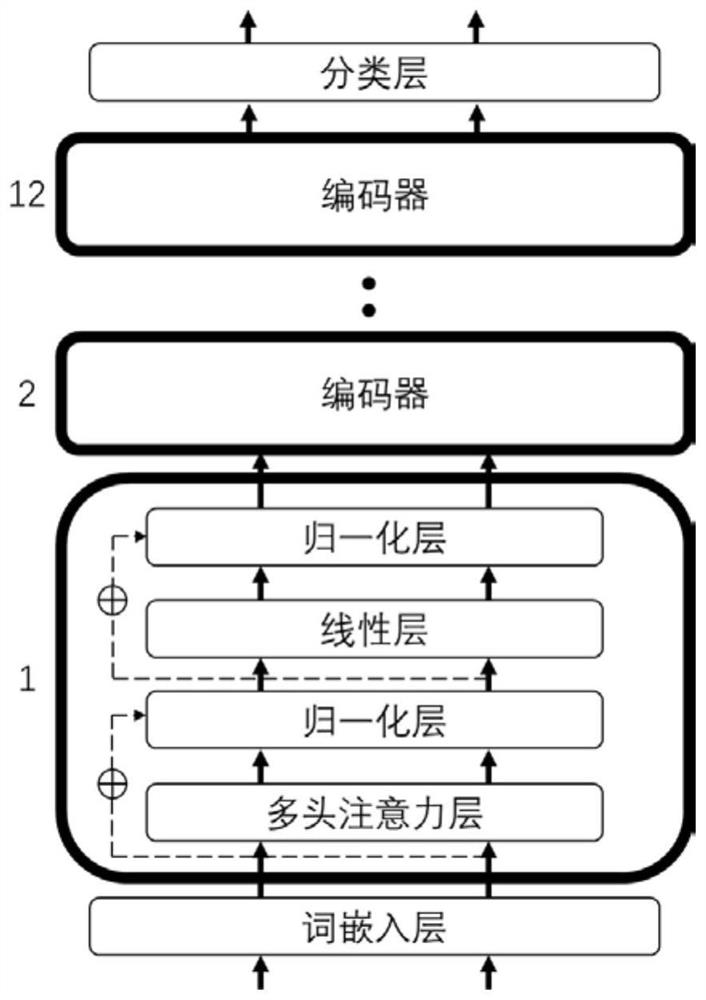
Examples
Embodiment Construction
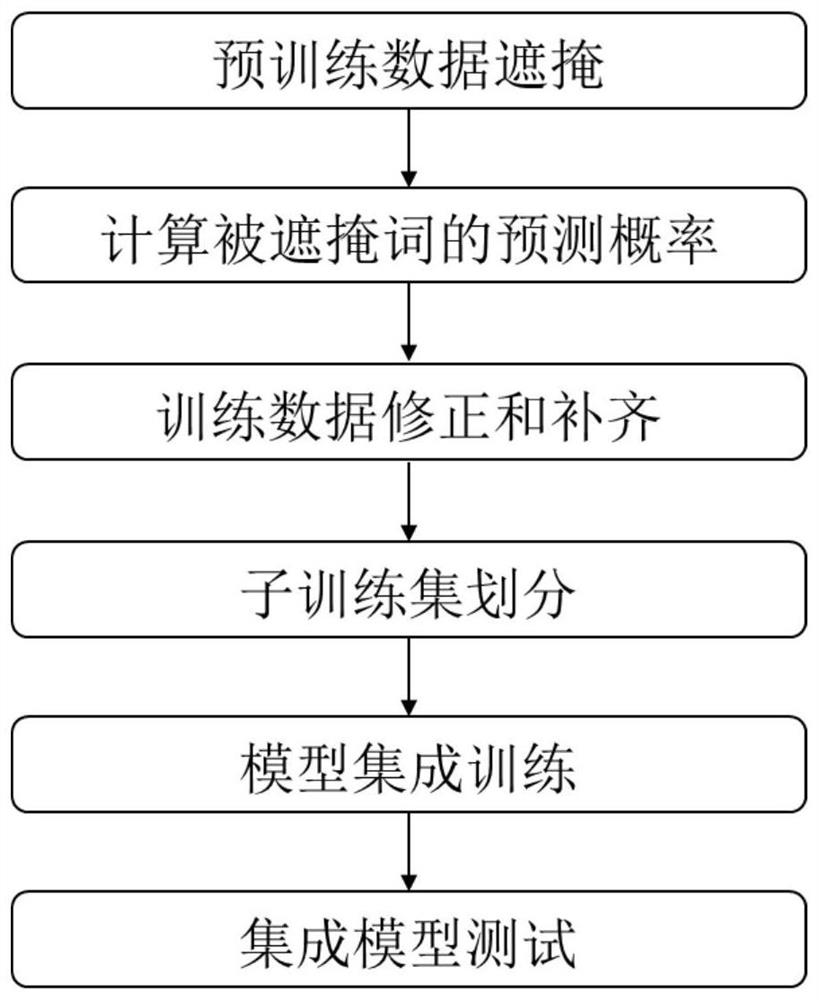
[0052] Below in conjunction with accompanying drawing, the present invention will be further explained;
[0053] Such as figure 1 As shown, a method for learning the relevance of address text information based on data preprocessing includes the following steps:
[0054] Step 1. Pre-training data masking
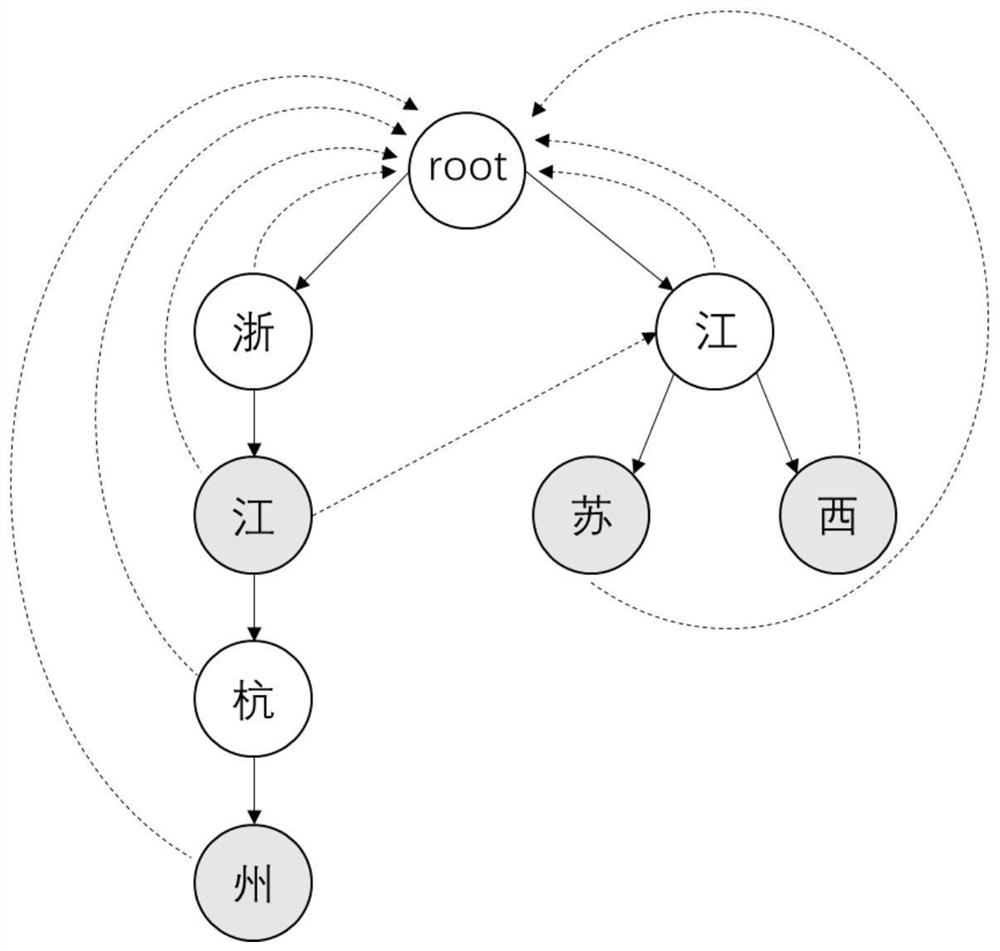
[0055] Collect all the individual addresses in the national statistical zoning code and urban-rural division database that contain complete address location information, and randomly cover up the address "Xiasha Street, Qiantang District, Hangzhou City, Zhejiang Province".
[0056] If random words are masked, the original address will cover any discontinuous word with a high probability, and the address information after masking is: "Xiasha[mask, Qiantang District, [mask] City, [mask] City, Zhejiang Province ]road". If it is masked with a special phrase representing location information, the masked words will represent the key elements of the address, such as randomly sele...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More