

Data de-duplication method based on combination of similarity and locality
A technology of deduplication and similarity, which is applied in digital data processing, special data processing applications, instruments, etc., can solve problems such as affecting the throughput rate of deduplication, avoid accessing disk indexes, reduce memory overhead, and duplicate data. Remove efficient effects
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
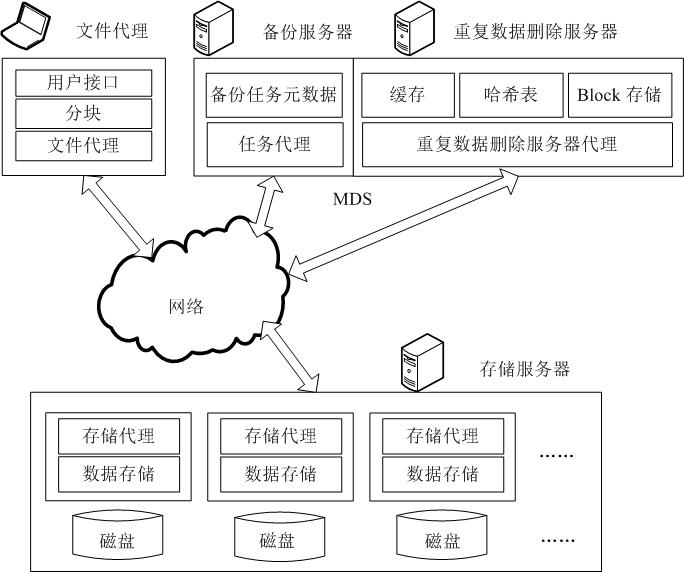
[0027] The deduplication method of the present invention will be further described below in conjunction with the accompanying drawings and embodiments.
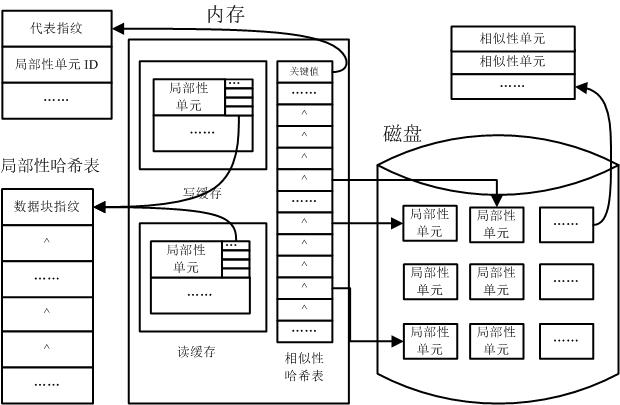
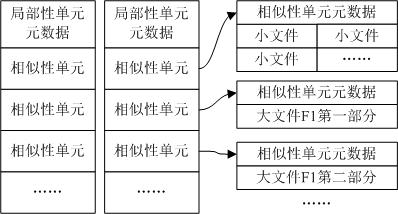
[0028] The data deletion method of the present invention divides the data stream to be backed up into blocks and groups, uses the fingerprint set of each group of data blocks to construct a similarity unit, and selects the representative fingerprint of the similarity unit, that is, selects the smallest prefix of the fingerprint value in the similarity unit Put the representative fingerprint into the memory and use it as the key value index for data deduplication to judge the similarity.
[0029] Because if the data block sets represented by two similarity units have a lot of repeated data blocks, the probability that their fingerprints are equal is equal to the ratio that they have a common fingerprint, so the similarity judging method described in the present invention is based on the similarity probability, The greater the ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More