

Chinese text classification method based on MPI (Message Passing Interface) and adaboost.MH
A text classification and Chinese technology, applied in character and pattern recognition, special data processing applications, instruments, etc., can solve the problems of long training set time and a lot of time, and achieve the effect of improving time efficiency and shortening time
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
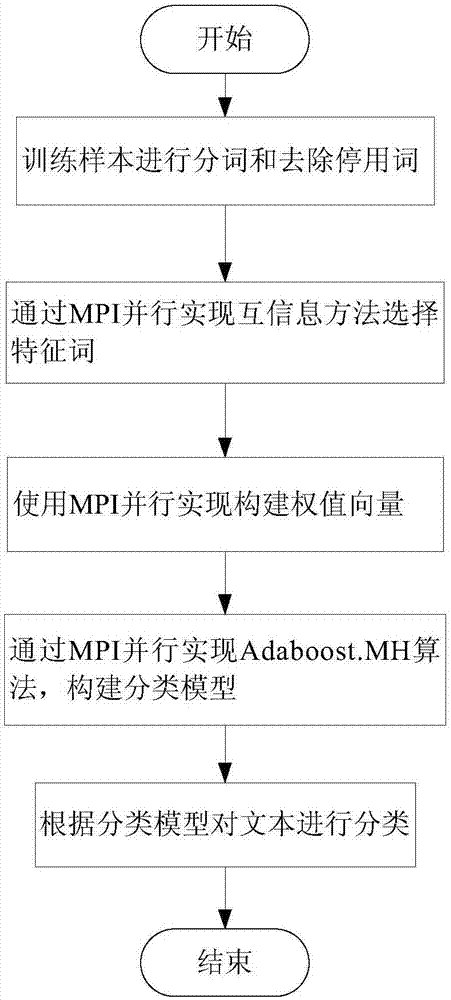
[0027] The present invention will be further described below in conjunction with the accompanying drawings.
[0028] Such as figure 1 As shown, the present invention includes the following 5 steps.
[0029] 1. Text preprocessing: collect Chinese text files in different fields through web crawlers and search network information, and perform word segmentation processing on the collected Chinese text files. You can use open source word segmentation packages such as IK and ICTCLAS to perform Chinese word segmentation on the collected texts, and then remove punctuation marks and stop words. Stop words are words that appear very frequently but have no practical meaning, such as "Le", " of", "and" and so on. The entry after word segmentation is separated and saved into the local training set data as a preliminary feature.
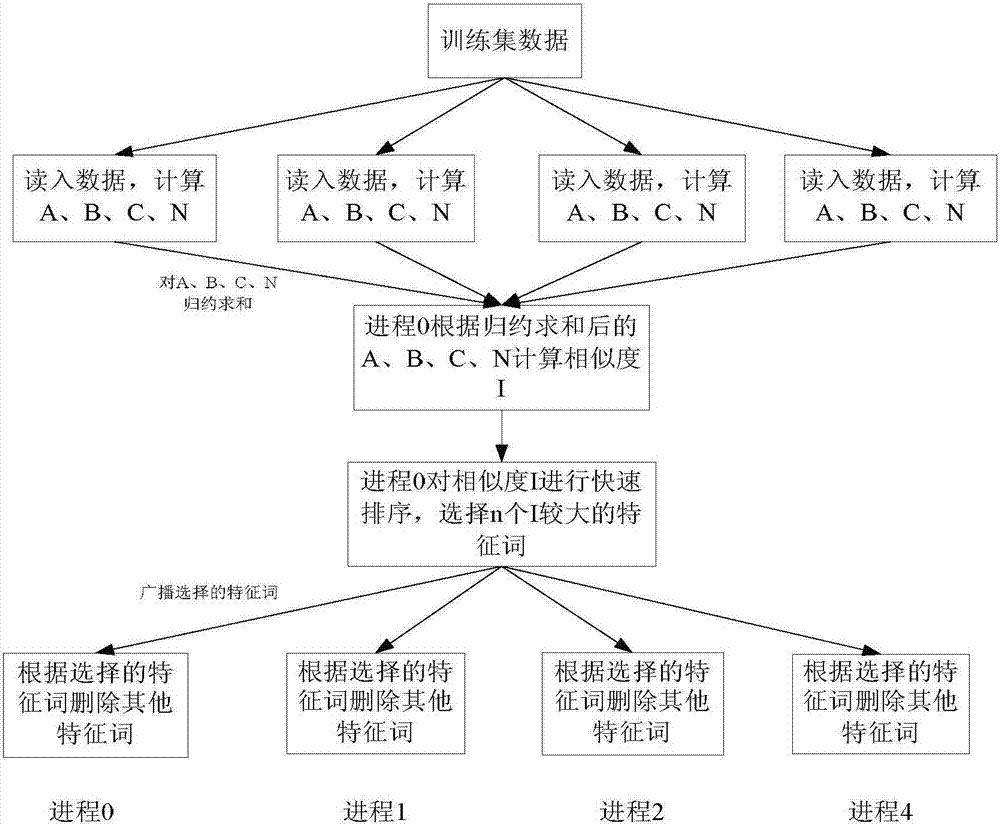
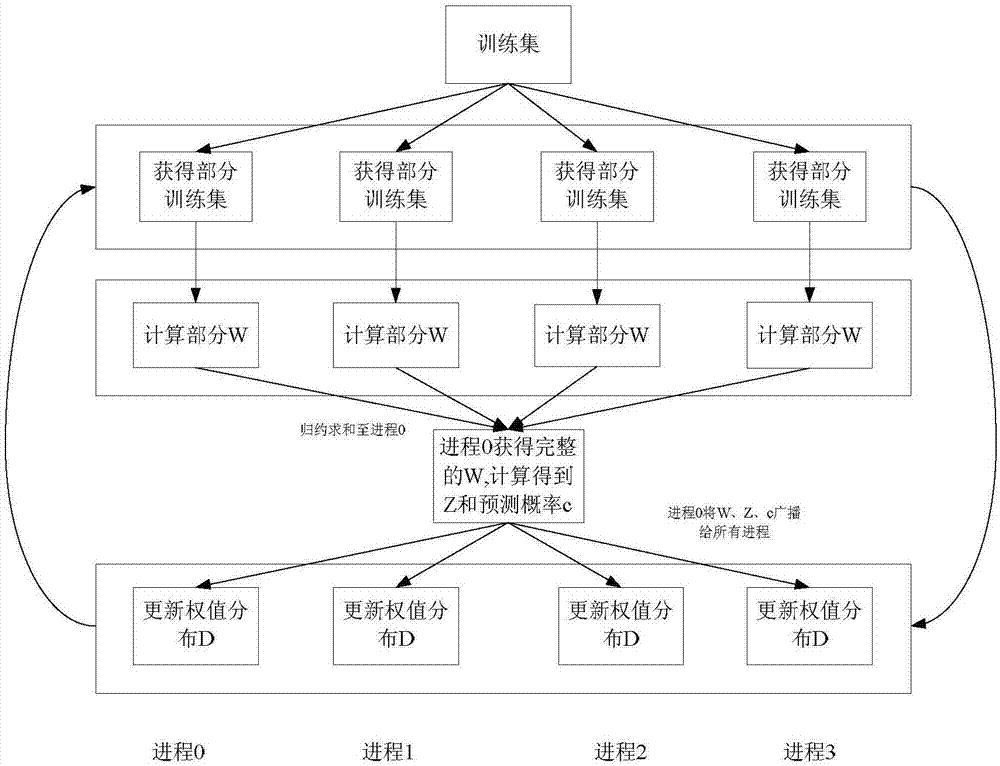
[0030]2. Feature selection: Preliminary features are selected by using the mutual information method. First use the MPI_Init function to start p processes, ob...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More