

Big data text deduplication technology based on improved Simhash algorithm
A big data and text technology, applied in the field of big data text deduplication, can solve the problems of duplication, data redundancy, etc., achieve the effect of accurate calculation, reduce the number of comparisons, and improve the efficiency of the algorithm
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

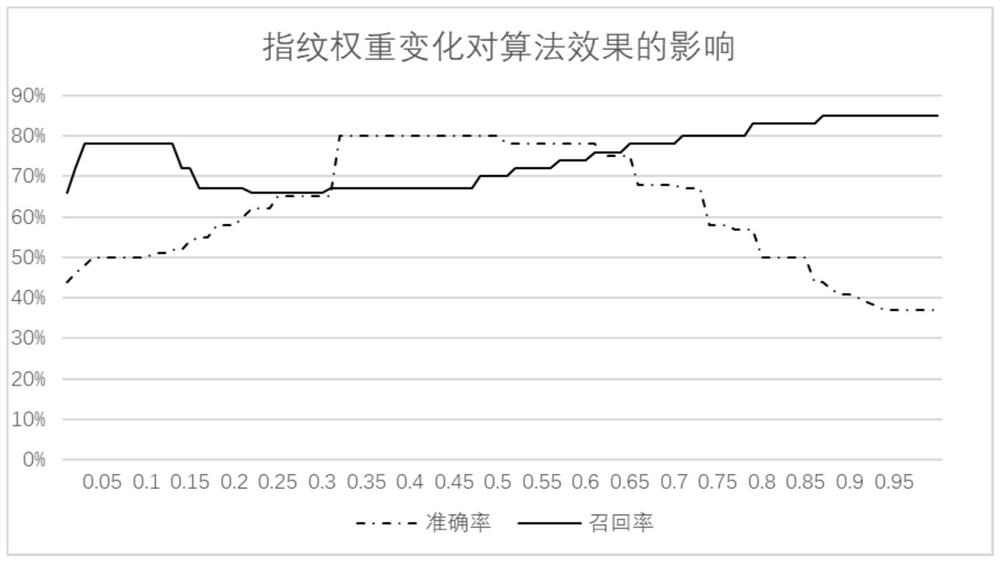
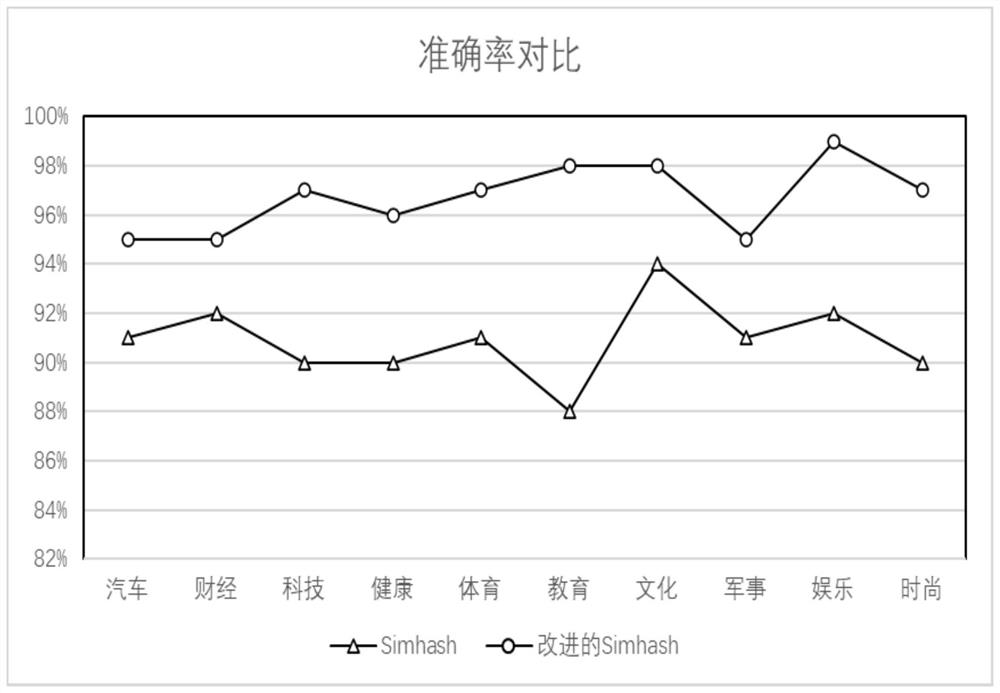
Examples
Embodiment Construction
[0024] In order to clearly and completely describe the technical solutions in the embodiments of the present invention, the present invention will be further described in detail below in conjunction with the drawings in the embodiments.
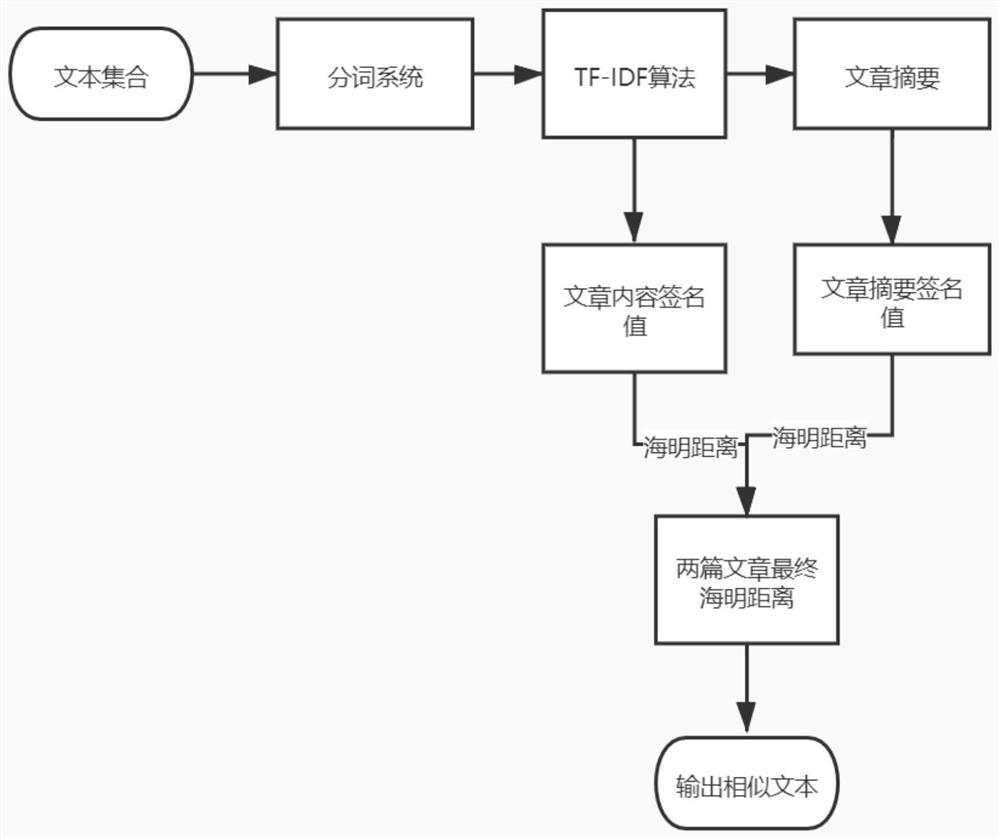
[0025] The embodiment of the present invention is based on the flow of the big data text deduplication technology of the improved Simhash algorithm, such as figure 1 shown, including the following steps.
[0026] Step 1 The process of obtaining the repeated text dataset is as follows:
[0027] Sogou news data: https: / / www.sogou.com / labs / resource / ca.php, data 5000 Chinese news text data, divided into ten categories: 'auto', 'finance', 'technology', 'health' ','Sports','Education','Culture','Military','Entertainment','Fashion', each with 500 similar data and mixed with 2000 irrelevant data.
[0028] Step 2 The process of word segmentation and feature weight calculation of the text set is as follows:
[0029] Step 2-1 uses the NLPIR-ICTCLAS w...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More