

Web page body text extraction method and apparatus
A text and webpage technology, applied in the field of webpage text extraction methods and devices, can solve the time-consuming and labor-intensive problems of webpage information extraction, and achieve the effect of good versatility, rapid and accurate extraction
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

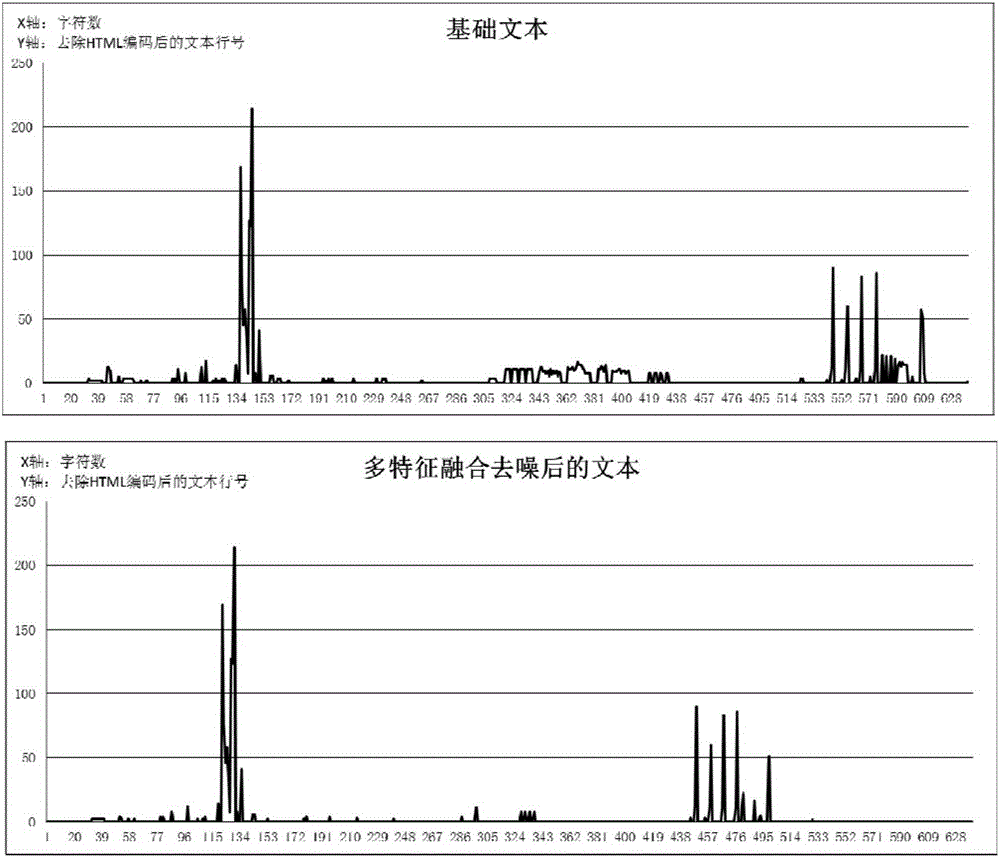
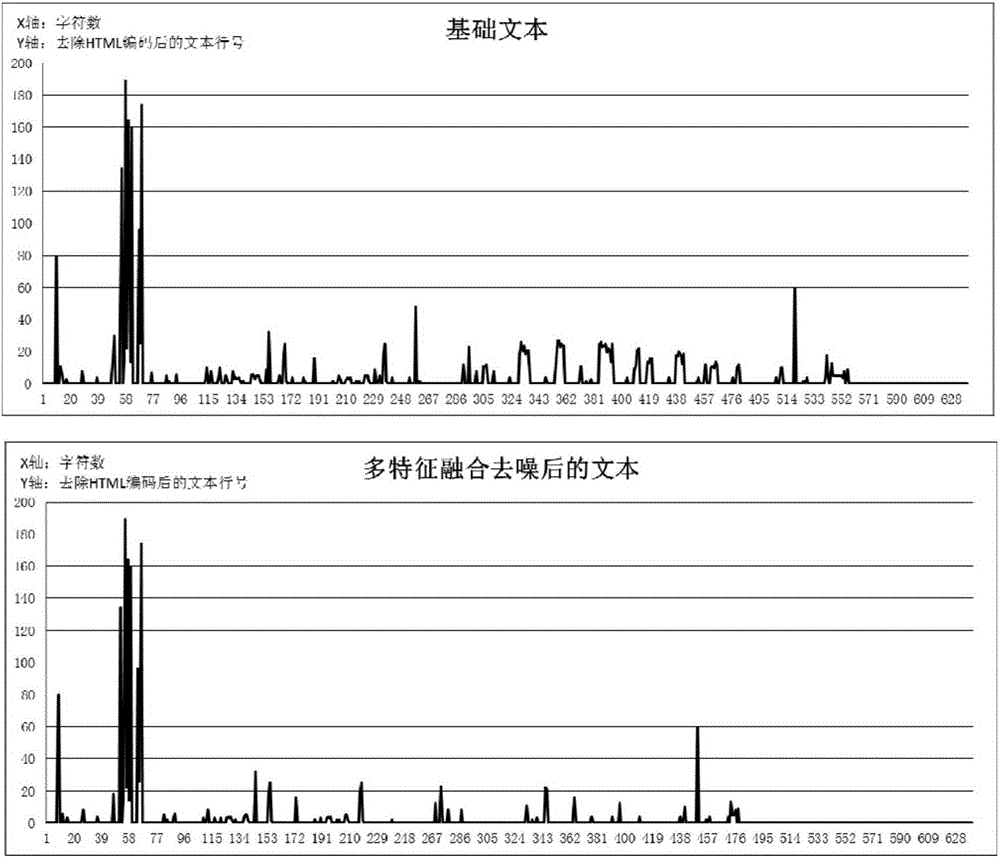
Examples
Embodiment Construction
[0034] Embodiments of the present invention will be described in detail below in conjunction with the accompanying drawings.
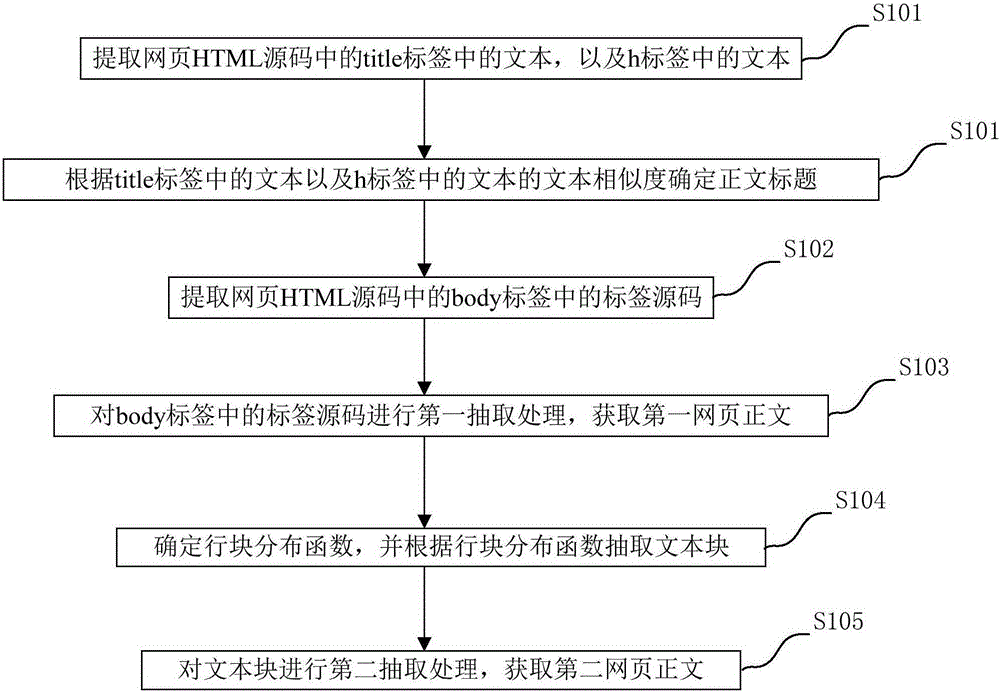
[0035] figure 1 It shows a flow chart of a web page text extraction method provided by an embodiment of the present invention, see figure 1 , a web page text extraction method provided by an embodiment of the present invention, comprising:
[0036] S101. Extract the text in the title tag and the text in the h tag in the HTML source code of the webpage.
[0037] Specifically, since the text in the title tag of some web pages is information describing the website and has nothing to do with the text, it is first necessary to determine whether the text in the title tag is related to the actual text. At this time, the text in the title tag can be extracted from the source code of the web page, for example, marked as title 1, and the text in the h tag can be extracted from the HTML source code of the web page, for example, marked as title 2.
[0038] S102...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More