

Method for crawling webpage contents with paging
A web page content and paging technology, applied in the field of JAVA platform, can solve the problem that the paging part cannot be directly captured
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
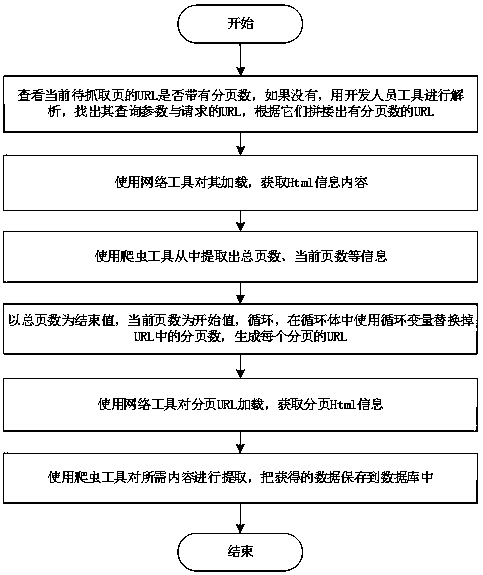
[0016] like figure 1 Shown, the present invention adopts following steps:
[0017] Step 1. Check whether the URL of the current page to be crawled has a page number. If not, use the developer tool to analyze it, find out its query parameters and the requested URL, and splice out a URL with a page number based on them;
[0018] 1) Open the webpage to be crawled through mainstream browsers such as 360 or Google;
[0019] 2) Open the developer tools;
[0020] 3) Find the Headers sub-tab in the Network tab;
[0021] 4) Find the requested main URL and request method in General;
[0022] 5) Obtain the content of the Request Headers request header;
[0023] 6) Find the parameter content of Query String Parameters, assemble it with the same main URL as above, and generate a URL with paging numbers;
[0024] Step 2, use a network tool to load it, and obtain the Html information content;
[0025] / / 1) Initialize the network tool according to the request header information
[0026...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More