

Textual Semantics-Based Text Structure Analysis Method
A technology of structural analysis and text, applied in the field of document semantic information analysis, to achieve the effect of general and widely used method framework
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
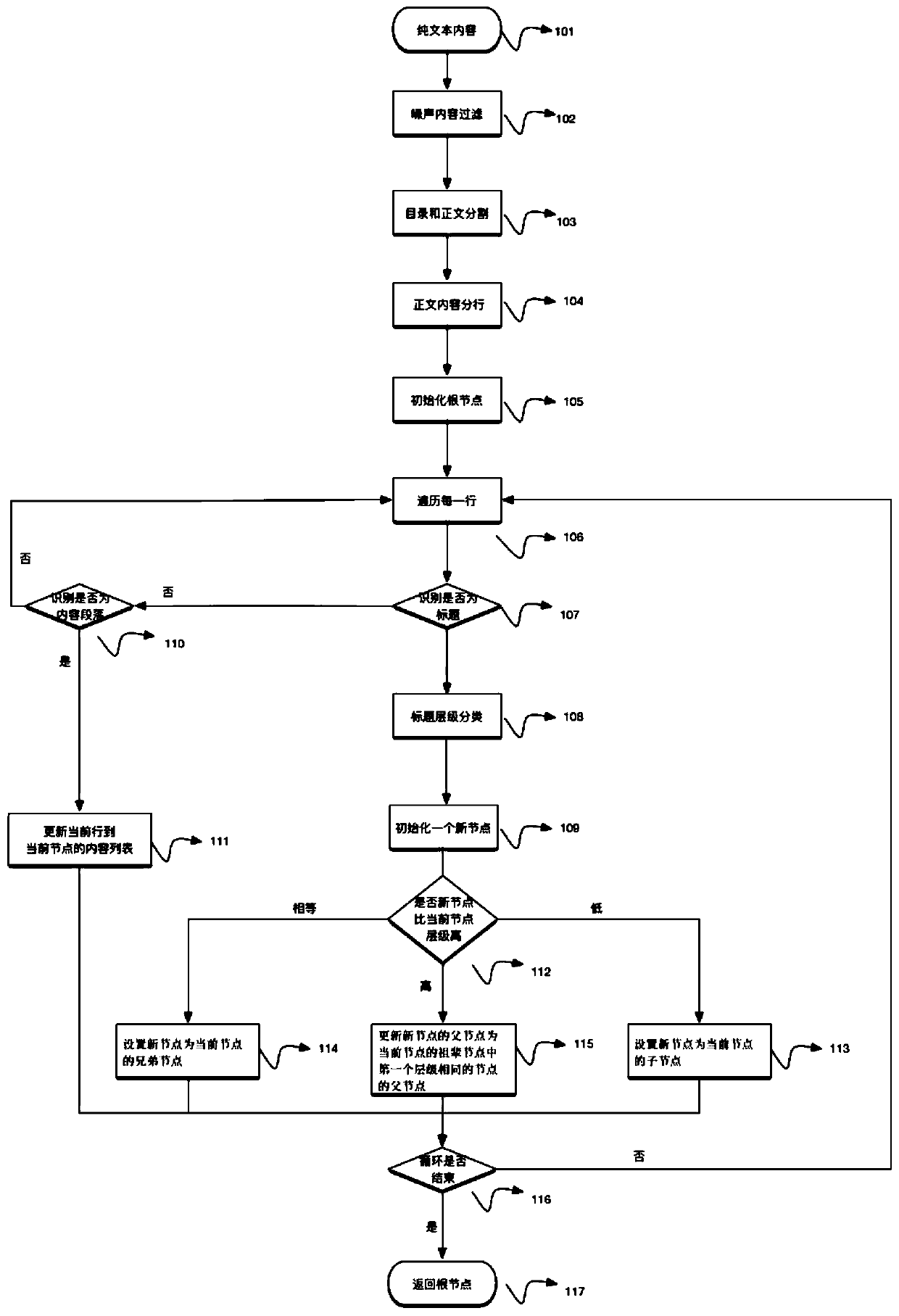
[0030] The present invention will be described in detail below in conjunction with embodiments.
[0031] One, data acquisition
[0032] 101 to obtain plain text data. Obtain plain text TXT data in machine-unreadable formats such as PDF, images, etc. Open source tools can be used to convert documents to be processed into machine-readable TXT format. For example, use PDFBOX to parse PDF documents into TXT documents, or use OCR technology to convert scanned files in JEPG format into TXT documents.
[0033] 2. Text extraction
[0034] 102 Noise content filtering. Filter noise content for structure extraction tasks, such as blank lines, headers and footers, table content, etc. The header and footer can be filtered based on the repeated information of each page, or the header and footer of specific types of documents can be filtered based on rules. The content of the table may affect the judgment of the hierarchical structure, and the table needs to be identified and eliminated.
[0035...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More