

Personalized voice and video generation system based on phoneme posterior probability
A posteriori probability and generation system technology, applied in the field of voice and video, can solve problems such as weird lips, poor overall practicability, and difficulty in guaranteeing user-generated effects, and achieve the effect of reducing requirements
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0024] The following will clearly and completely describe the technical solutions in the embodiments of the present invention with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only some, not all, embodiments of the present invention. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
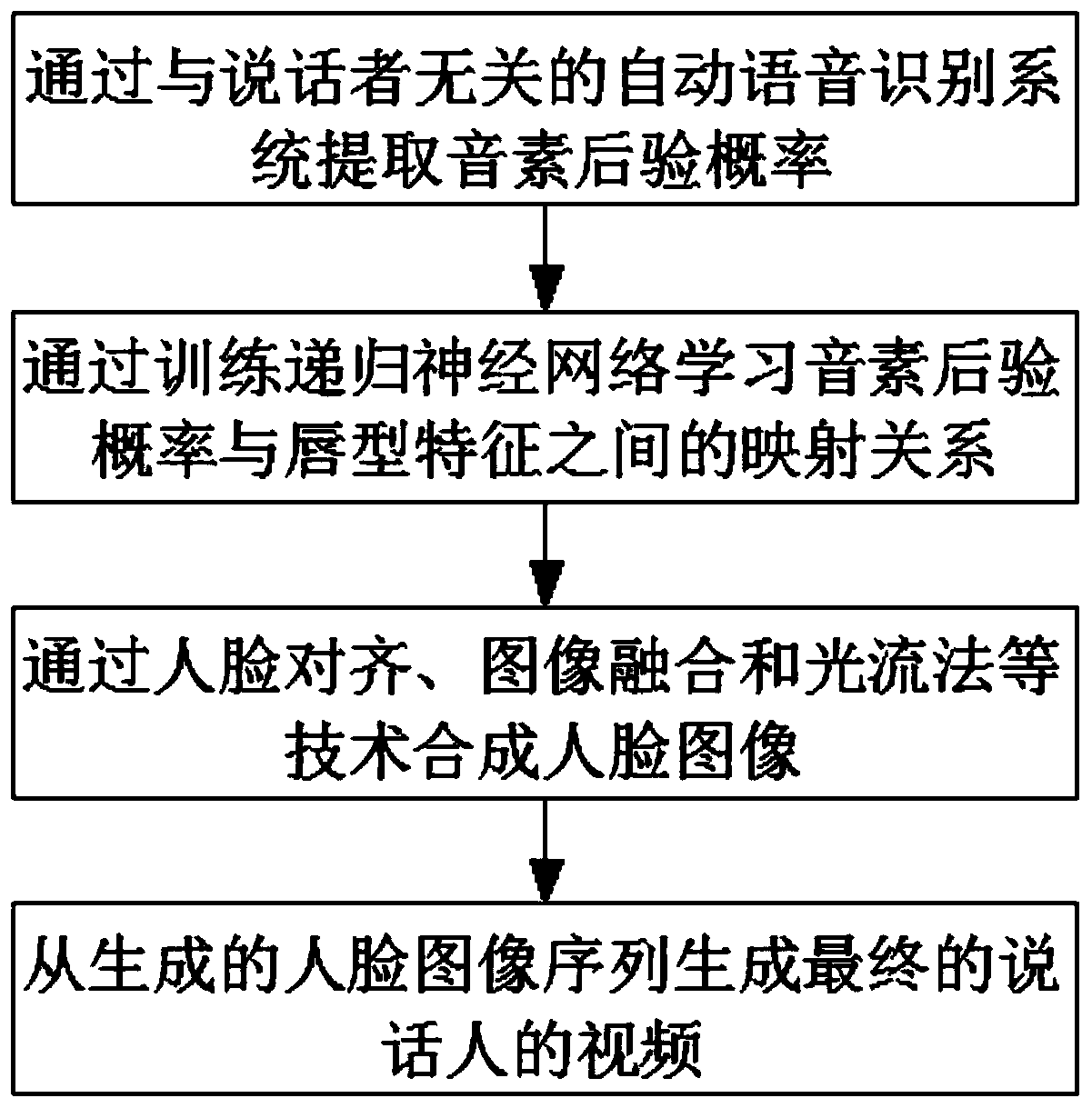
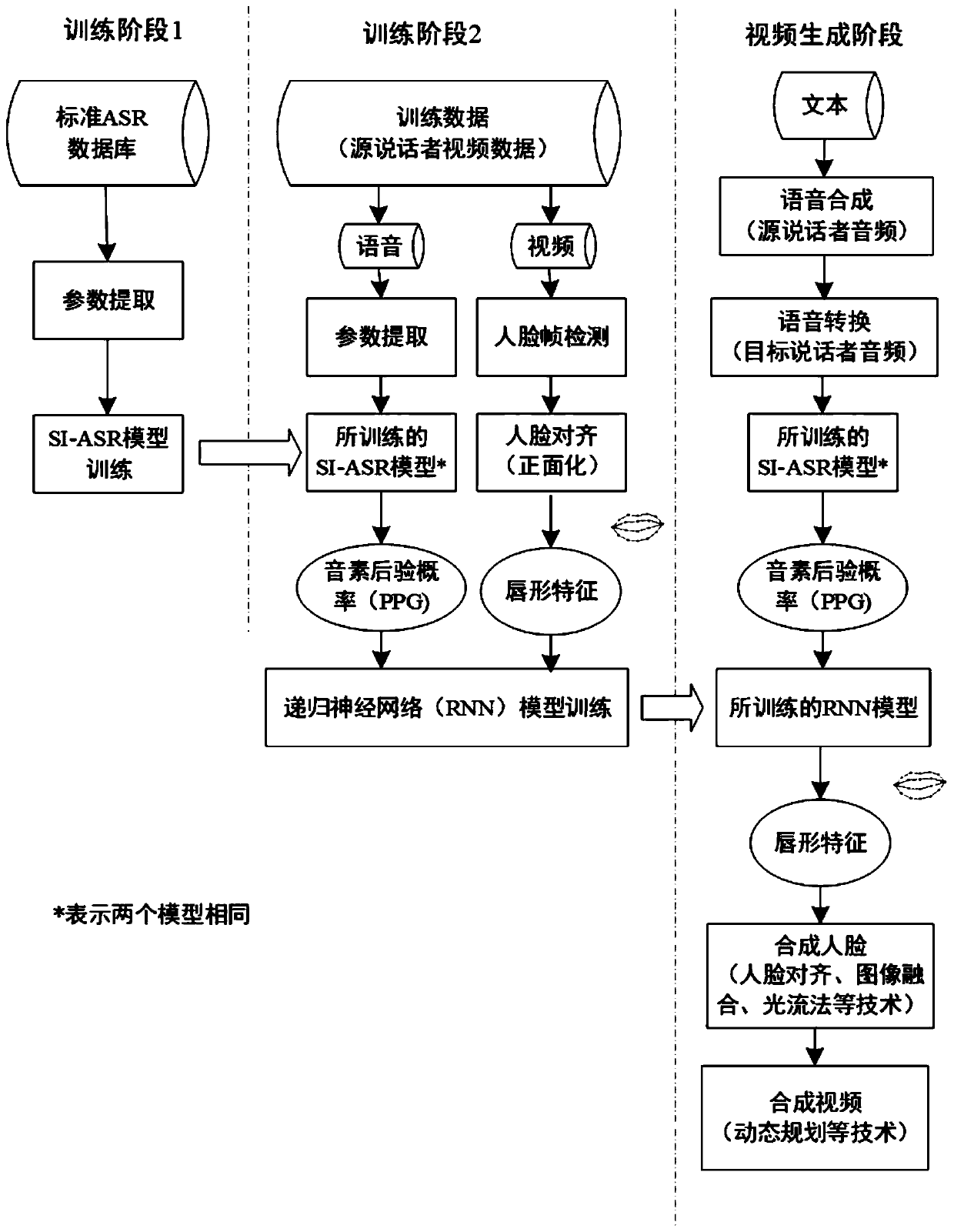
[0025] see Figure 1-3 , the embodiment of the present invention provides a technical solution: a personalized voice and video generation system based on the phoneme posterior probability, which mainly includes the following steps:
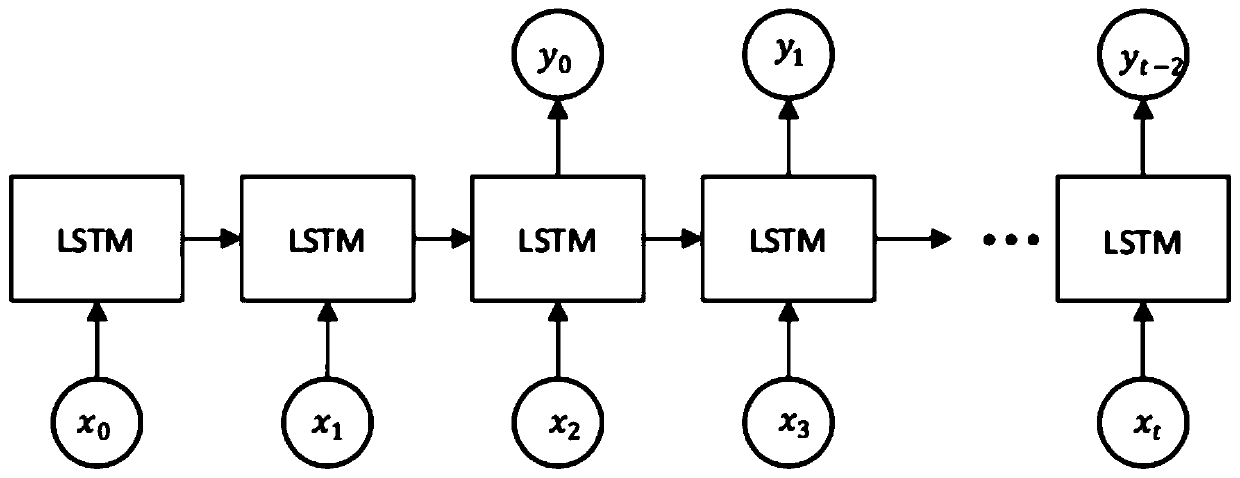
[0026] S1. First, from the speech of the source speaker, a speaker-independent automatic speech recognition (SI-ASR) system is used to extract phoneme posterior probabilities (PPGs). Posterior probability-based methods are partly ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More