

A method for removing compression noise in video call video based on voice cues
A technology for video compression and video calling, which is used in TV, image communication, color TV, etc., and can solve the problem of ignoring the role of voice.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
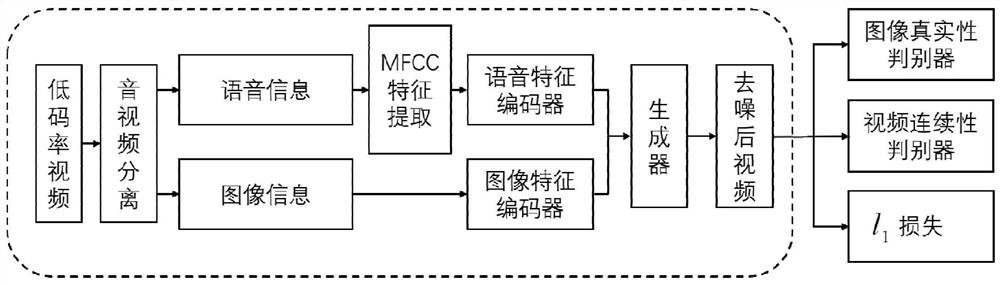
[0081] A method for removing compression noise from video calls based on voice cues, such as figure 1 shown, including the following steps:
[0082] A. Building datasets and data preprocessing
[0083] 1) Collect speech videos containing people's heads, and construct a video call video data set;
[0084] 2) the speech video of the people's head that step 1) collects is original video compresses, subframes successively, carries out feature extraction to the voice signal in described original video, constructs training set and test set;
[0085] B. Establish a video compression noise removal model based on voice cues
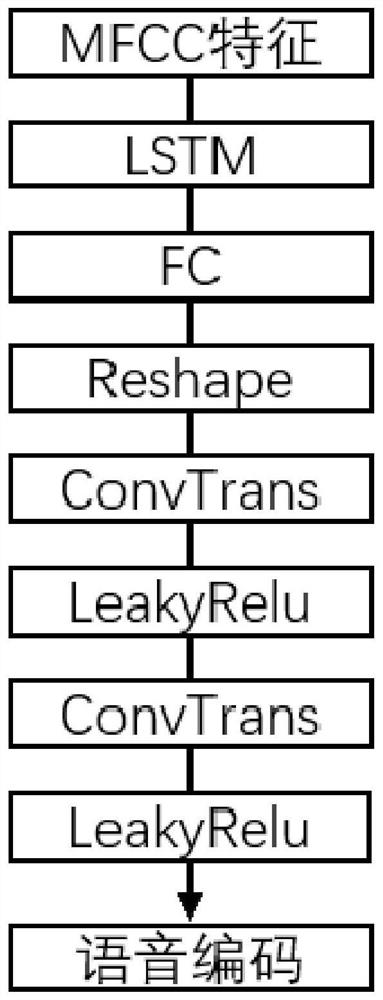
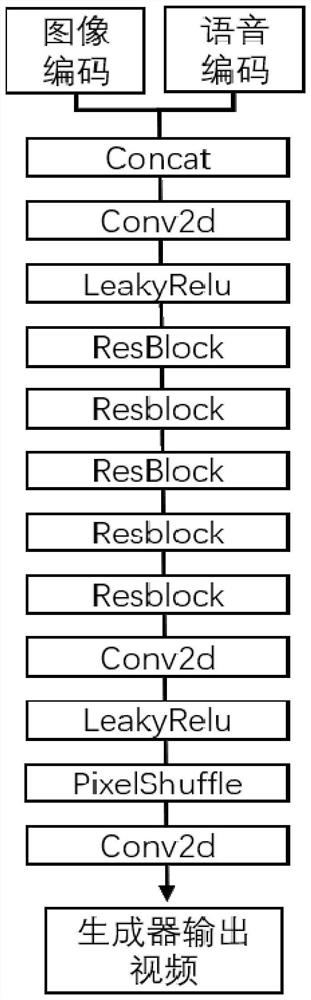
[0086] Such as Image 6 As shown, the video compression noise removal model based on speech cues includes a speech feature encoder model, an image feature encoder, a generator network model, an image authenticity discriminator, and a video continuity discriminator; the speech feature encoder model is used to encode speech features; the image feature encoder is...
Embodiment 2
[0098] According to a method for removing compression noise in a video call based on voice clues described in Embodiment 1, the difference is that:
[0099] Step A, building dataset and data preprocessing, video call video dataset is the original video Including selecting and downloading a large number of speech videos containing human heads from the Internet, setting a total of N segments, namely V i Represents the i-th video, including the following steps:
[0100] a. Read N segments of video, extract the voice signal, and standardize the voice signal into a monophonic voice file of the same frequency;
[0101] B, carry out MFCC feature extraction to the monophonic speech file after the processing that step a obtains, each sampling interval of each monophonic speech file is extracted to m dimension MFCC feature, and each monophonic speech file is correspondingly extracted to a MFCC feature matrix A with n columns and m rows, n refers to the number of sampling interval...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More