

Virtual video customer service robot synthesis method and system based on generative adversarial network
A technology of virtual video and synthesis method, applied in the field of face video synthesis, which can solve the problems of artificial processing traces, inability to switch the speaker's language, and inability to achieve good alignment of lip shape and voice, etc., to achieve good authenticity, good expansibility effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

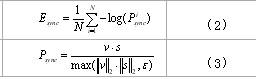
Examples
Embodiment 1
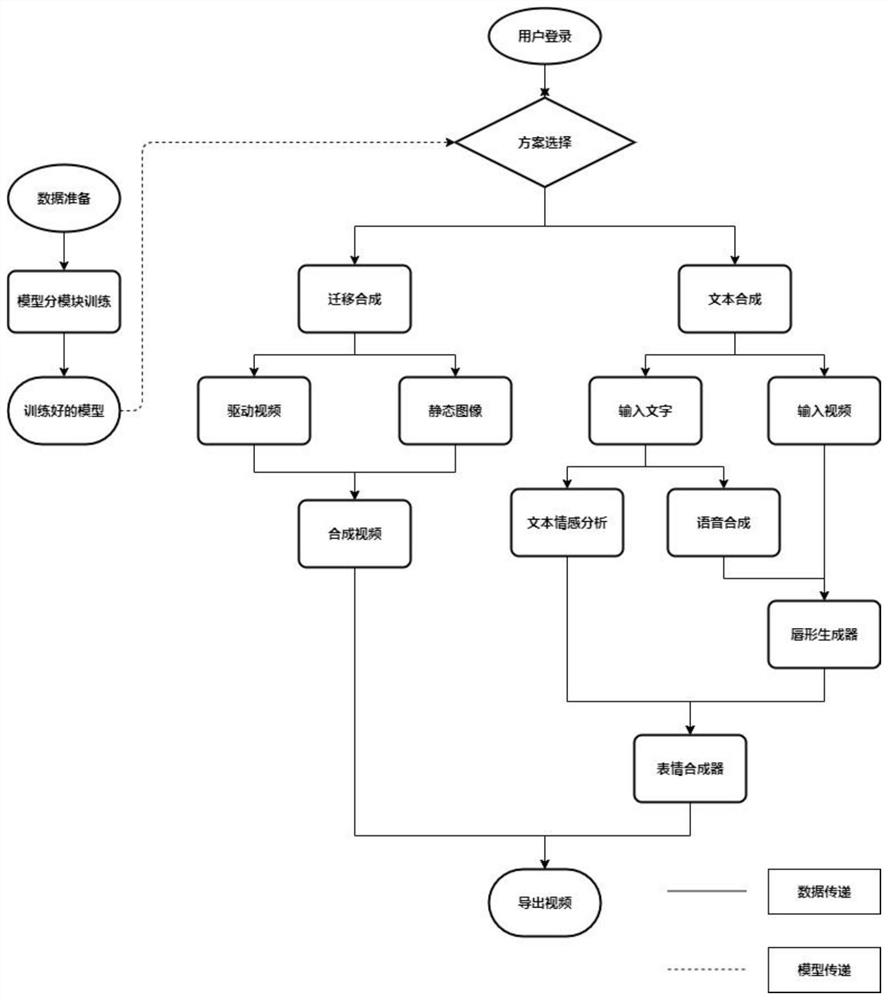
[0032] An embodiment of the present invention provides a method for synthesizing a virtual video customer service robot based on a generative adversarial network, the method comprising the following steps:
[0033] 101: Use the you-get tool to collect 1,000 CCTV news broadcast videos of different characters as the corresponding Chinese corpus-video dataset, and organize them in the format of the LRS2 dataset.
[0034] Further, extract the audio from the video with the ffmpeg tool, and convert the audio file into mel blocks for network reading through the python library librosa, and crop the video into MP4 format files with a resolution of 256*256 and a duration of 15 seconds to complete the data. Preprocessing of the set.
[0035] 102: Train the Wav2Lip network model on the collected Chinese dataset. The model can extract the mapping relationship between sound and lip shape through the face decoder and audio decoder, generate a synthetic lip shape, and pass the pre-trained li...
Embodiment 2
[0043] The scheme in Embodiment 1 is further introduced below in conjunction with specific examples and calculation formulas, and is described in detail below:
[0044] 1. Data preparation
[0045] The invention uses the you-get tool to collect 1000 CCTV news broadcast videos of different characters as the corresponding Chinese corpus-video data set, and organizes them according to the format of the LRS2 data set. Further, the dataset is preprocessed with ffmpeg and librosa tools.
[0046] The dataset consists of corresponding audio and video. The video part contains the broadcast content of 5 different male anchors and 5 different female anchors, the frame rate is 25 fps, the resolution is cropped to 256*256, the duration is 25 seconds, and the format is MP4; the audio part is from the video The extracted Mel block is used for the network to obtain sound information directly.
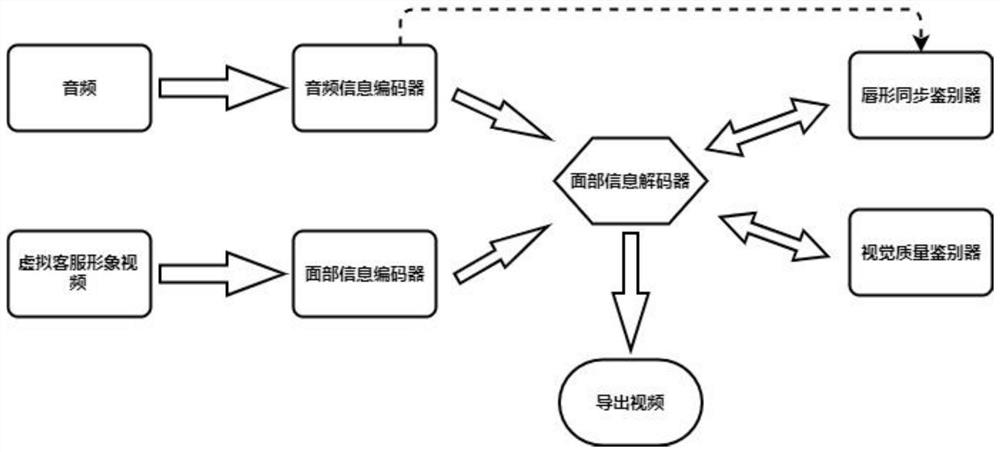
[0047] 2. Model training
[0048] The present invention includes four modules: a lip shape gene...
Embodiment 3
[0079] The embodiments of the present invention can be used not only in the generation of virtual video customer service, but also in the following application scenarios.
[0080] For example, let historical figures and static pictures complete specific actions such as singing and saying holiday wishes, such as importing the question corpus in advance, the system of virtual video customer service robot can be applied to campus welcome robots, psychological counseling robots, etc., which can enable students and robots to achieve face-to-face Real communication, to achieve better human-computer interaction.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More