

A method and system for detecting voice endpoints
An endpoint and voice technology, applied in the computer field, can solve problems such as poor performance of detection technology
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
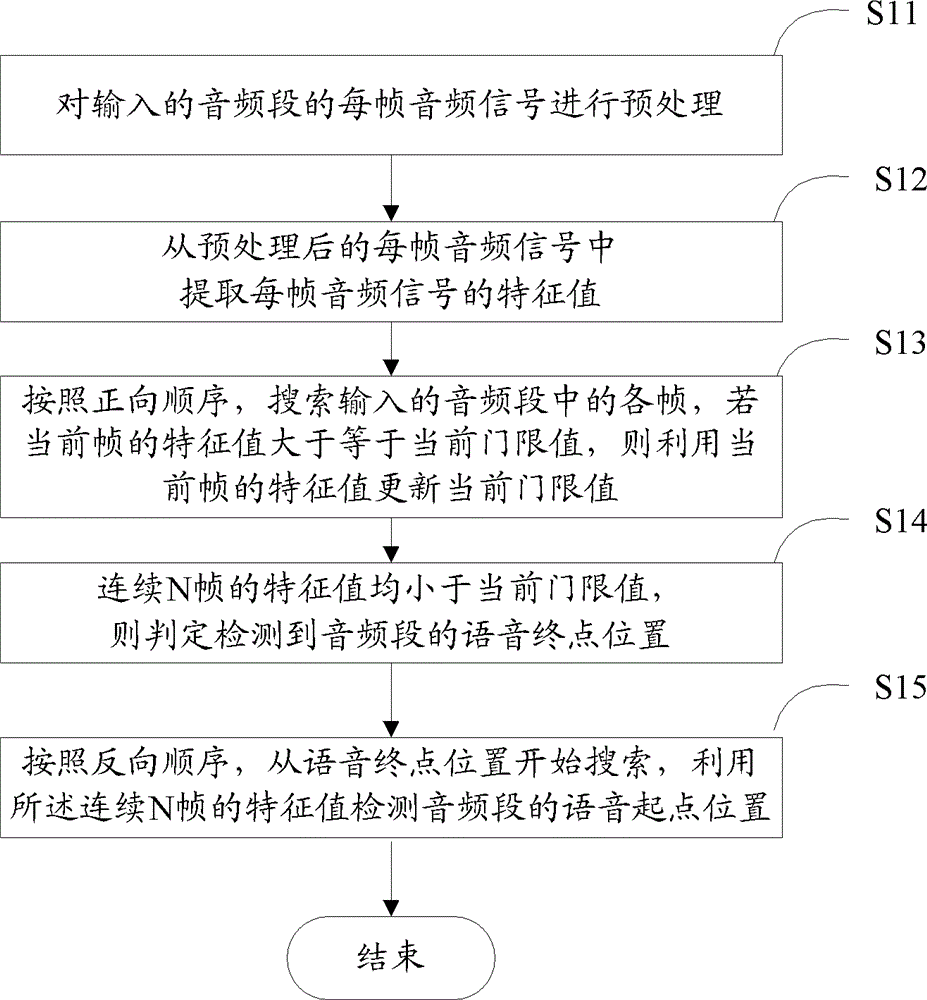
[0081] Embodiment 1. This embodiment provides a method for detecting voice endpoints, see figure 1 shown, including the following steps:
[0082] S11. Preprocess the audio signal of each frame of the input audio segment.
[0083] The specific audio signal preprocessing includes, but is not limited to, one or any combination of the following preprocessing: pre-emphasis of each frame of audio signal (ie, power boosting of high-frequency parts), fast Fourier transform (FFT), and sub-band division, etc. .
[0084] S12. Extract the feature value of each frame of audio signal from the preprocessed audio signal of each frame.
[0085] The purpose of feature extraction is to extract one or several features for each frame of audio signal to distinguish speech / non-speech frames. Specifically extracted feature values include, but are not limited to, one or any combination of the following: subband spectral entropy, energy, zero-crossing rate, correlation, and the like. In this embo...
Embodiment 2
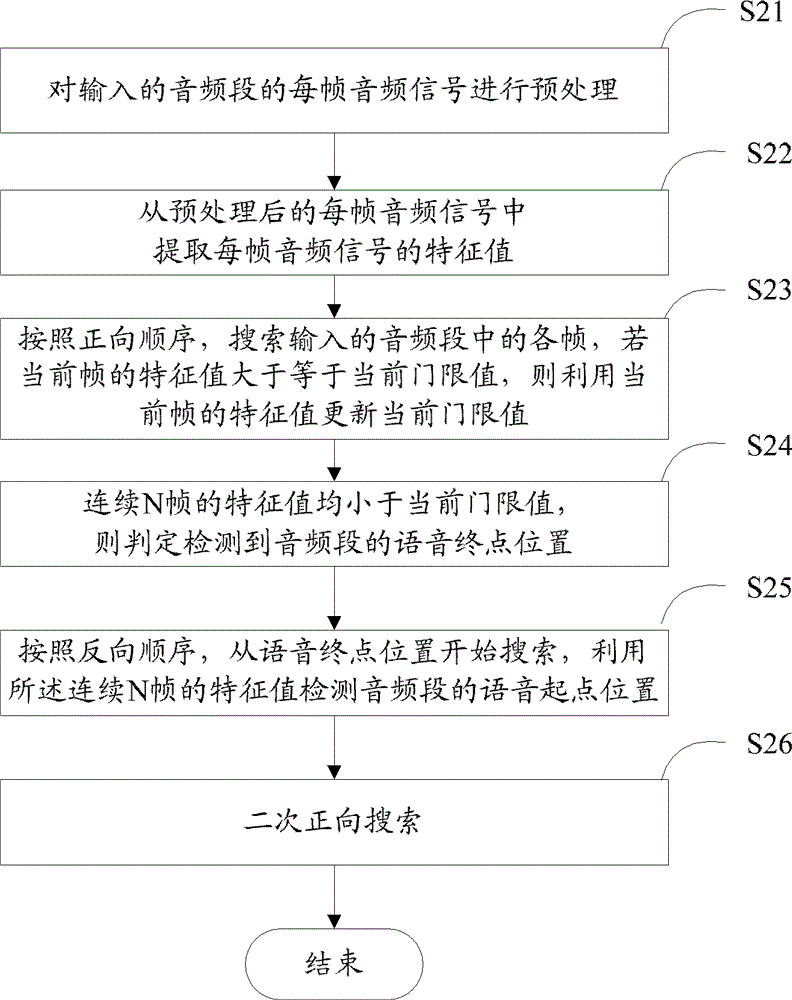
[0119] Embodiment 2. This embodiment provides a method for detecting voice endpoints, see figure 2 shown, including the following steps:
[0120] S21. Preprocess the audio signal of each frame of the input audio segment.
[0121] The specific description is consistent with that of S11 and will not be repeated here.
[0122] S22. Extract the feature value of each frame of audio signal from the preprocessed audio signal of each frame.
[0123] The specific description is consistent with that of S12, and will not be repeated here.
[0124] S23. Search each frame in the input audio segment in a forward sequence, and if the feature value of the current frame is greater than or equal to the current threshold value, update the current threshold value by using the feature value of the current frame.
[0125] In this embodiment, it is assumed that in the forward search process of the previous audio segment, the last frame of the previous audio segment is searched, and there is no s...
Embodiment 3
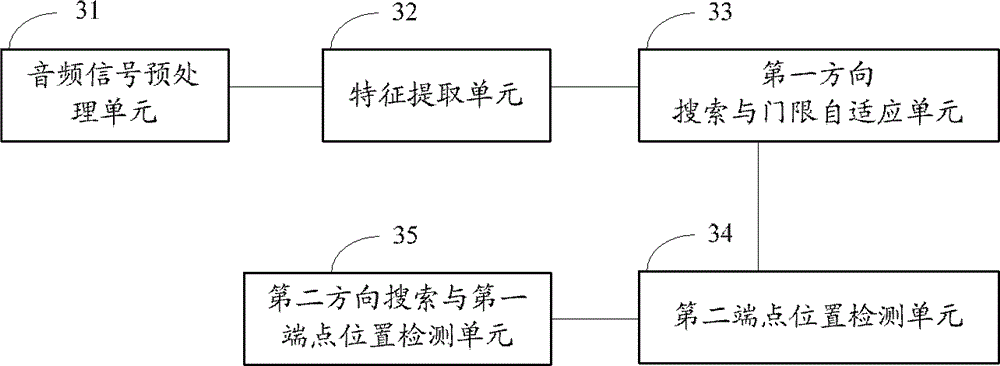
[0150] Embodiment 3. This embodiment provides a system for detecting voice endpoints, see image 3 As shown, it includes: audio signal preprocessing unit 31 , feature extraction unit 32 , first direction search and threshold adaptation unit 33 , second end point position detection unit 34 and second direction search and first end point position detection unit 35 .
[0151] The audio signal preprocessing unit 31 is configured to preprocess the audio signal of each frame of the audio segment. Specifically, the audio signal preprocessed by the audio signal preprocessing unit 31 includes, but is not limited to, one or any combination of the following preprocessing: pre-emphasis, fast Fourier transform (FFT), and sub-band division of each frame of audio signal.
[0152] The feature extraction unit 32 is configured to extract the feature value of each frame of audio signal from the preprocessed audio signal of each frame. Specifically, the purpose of feature extraction performed by...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More