

Document similarity measurement method and system based on keyword position structure distribution
A similarity measurement and keyword technology, which is applied in unstructured text data retrieval, text database query, special data processing applications, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

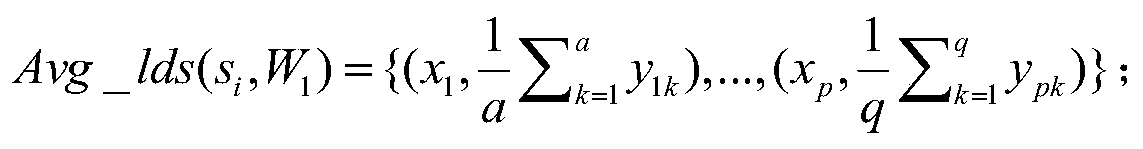
Examples
Embodiment 1
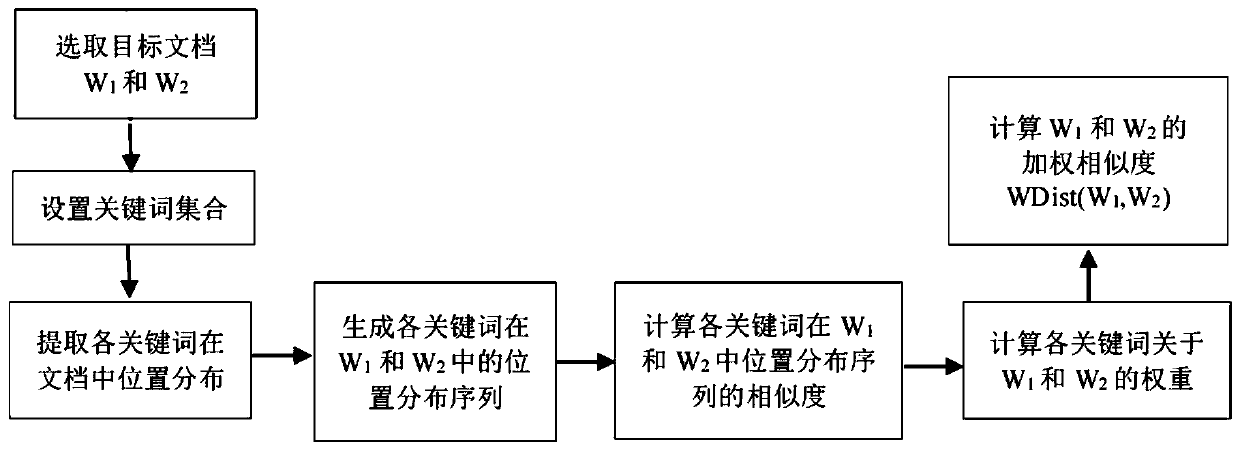
[0057] The present invention provides a method for measuring document similarity based on keyword position structure distribution, the method comprising:
[0058] S1 stores two documents W 1 with W 2 , the document W 1 with W 2 Both have multiple natural segments, the two stored documents W 1 with W 2 Word segmentation and stop word processing are performed separately, and segmentation marks are preserved.
[0059] S2 sets any target keyword set, in document W 1 with W 2 Find all the paragraph numbers and position information where each keyword appears, and mark them with triplets.
[0060] Given target keyword set S={s 1 ,s 2 ,...,s i ,...,s n}, n>1 is an integer, where, s i is a keyword, 1≤i≤n, for each keyword s in S i , in document W 1 Find occurrences of s in i All the paragraphs and positions of , for each occurrence position, extract its paragraph and position information, and mark the triplets in the following form (x, y, s i ), where x is the keyword s...
Embodiment 2
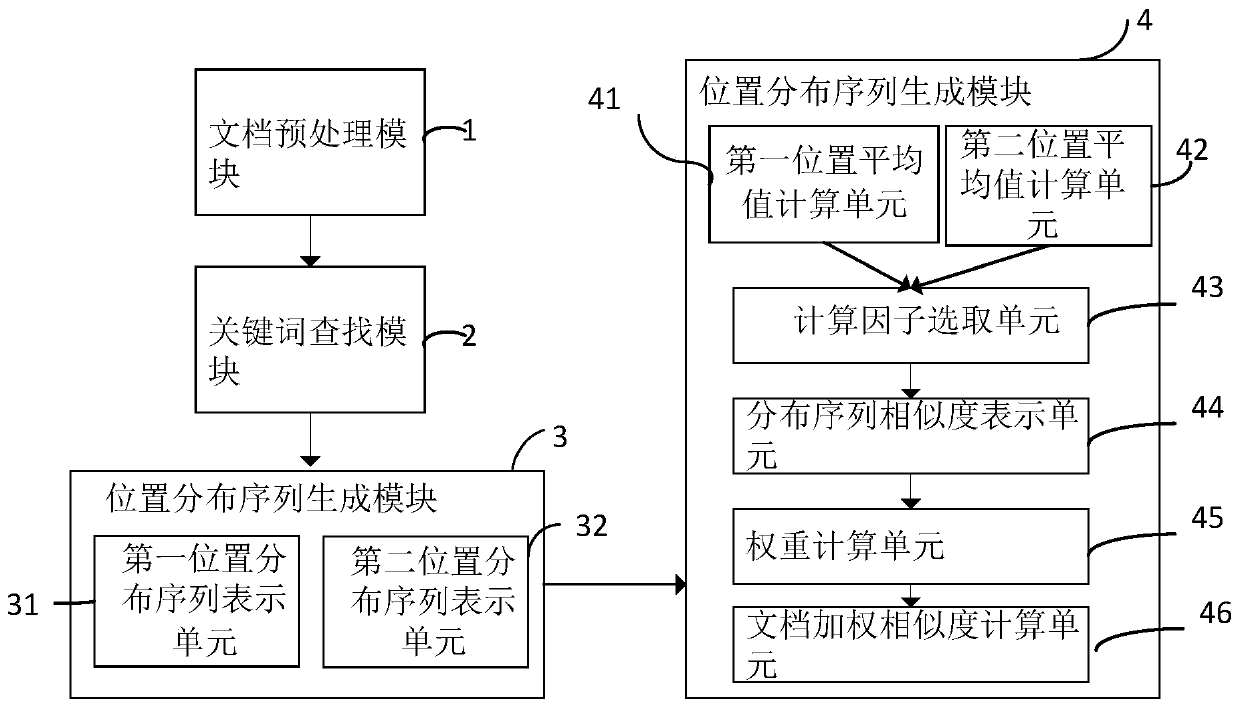
[0087] The present invention also provides a document similarity measurement system based on keyword position structure distribution, including:
[0088] Document preprocessing module 1, used to store two documents W 1 with W 2 , the document W 1 with W 2 Both have multiple natural segments, the two stored documents W 1 with W 2 Word segmentation and stop word processing are performed separately, and segmentation marks are retained;
[0089] keyword search module 2, used to set any target keyword set, in the document W 1 with W 2 Find all the paragraph numbers and position information where each keyword appears, and mark them with triplets;
[0090] The keyword search module also includes a position calculation unit 21 for calculating the keyword s i The position information in the natural segment, specifically: if the keyword s i The total number of words in a natural paragraph is sum; the keyword s in the natural paragraph i The previous word count is recorded as p...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More