Document similarity measurement method and system based on keyword sequence structure
What is AI technical title?
AI technical title is built by Patsnap AI team. It summarizes the technical point description of the patent document.
A technology of keyword sequence and document similarity, applied in unstructured text data retrieval, text database query, special data processing applications, etc. question
Active Publication Date: 2019-08-27
ZHENJIANG COLLEGE
View PDF5 Cites 1 Cited by
Summary
Abstract
Description
Claims
Application Information
AI Technical Summary
This helps you quickly interpret patents by identifying the three key elements:
Problems solved by technology
Method used
Benefits of technology
Problems solved by technology
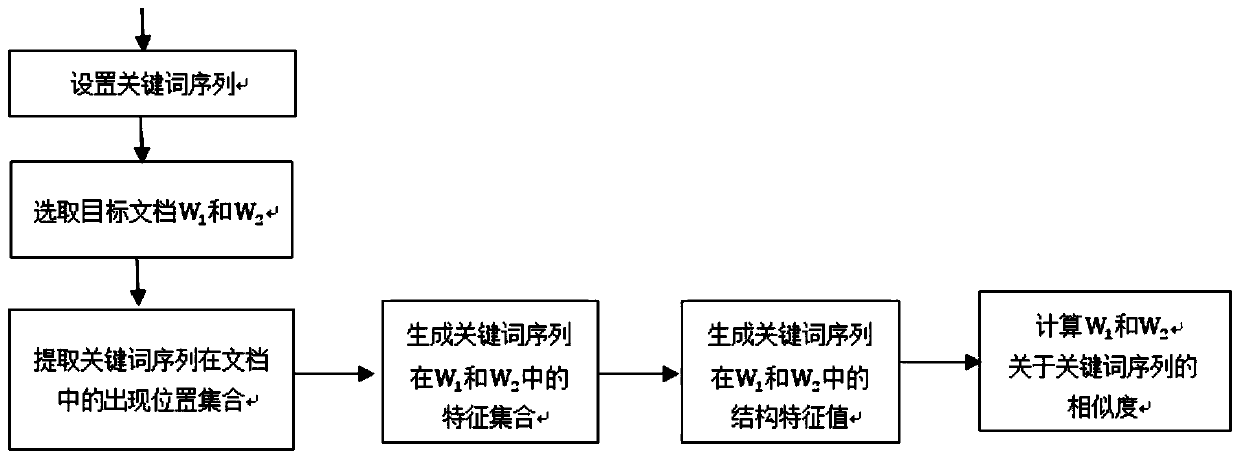
[0003] Purpose of the invention: In order to overcome the deficiencies in the prior art, the present invention provides a method for measuring document similarity based on keyword sequence structure, which can solve the semantics of document words and sentences The problem of the deviation of angle measurement similarity; also can avoid existing method when measuring similarity from keyword angle, to the insufficient problem that keyword is extracted in document full-text distribution structural feature, the present invention also provides a kind of based on keyword sequence structure document similarity measurement system
Method used
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
View more
Image
Smart Image Click on the blue labels to locate them in the text.
Viewing Examples
Smart Image
Click on the blue label to locate the original text in one second.
Reading with bidirectional positioning of images and text.
Smart Image
Examples
Experimental program
Comparison scheme
Effect test
Embodiment 1
[0037] The present invention provides a method for measuring document similarity based on keyword position structure distribution, the method comprising:
[0038] S1 stores two documents W 1 with W 2 , the document W 1 with W 2 Both have multiple natural segments, the two stored documents W 1 with W 2 Separate word segmentation and stop word processing.
[0039] S2 sets the keyword sequence, in the document W 1 with W 2 Search for the set of positions where all keywords in the keyword sequence appear in the keyword sequence;
[0040] keyword sequence S in W 1 An occurrence in means that m keywords in sequence S appear in document W 1 appears once in sequence. In the document W 1 Search for a certain occurrence of the keyword sequence S in , which can be recorded as: get the occurrence positions of m keywords Ponit={p 1 ,p 2 ,...,p m}, all occurrences form the set of occurrences of S in the document, where p i for keywords i In the document W 1 A certain occurr...
Embodiment 2
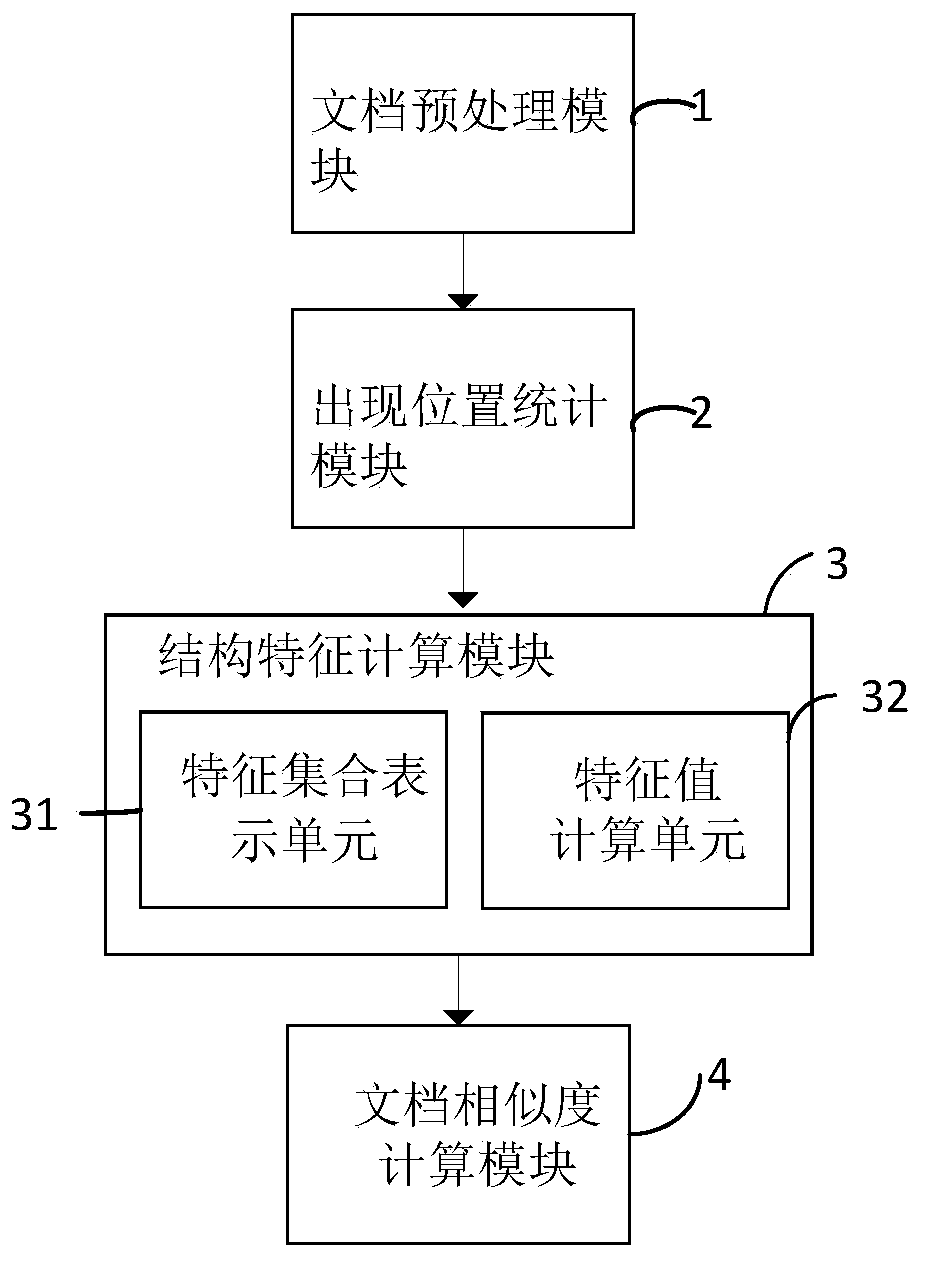
[0054] The present invention also provides a document similarity measurement system based on keyword sequence structure, comprising:
[0055] Document preprocessing module 1, used to store two documents W 1 with W 2 , the document W 1 with W 2 Both have multiple natural segments, the two stored documents W 1 with W 2 Separate word segmentation and stop word processing;
[0056] Appearance location statistics module 2, used to set the keyword sequence, and in the document W 1 with W 2 Search for the set of positions where all keywords in the keyword sequence appear in the keyword sequence;
[0057] keyword sequence S in W 1 An occurrence in means that m keywords in sequence S appear in document W 1 appears once in sequence. In document W 1 Find a certain occurrence of the keyword sequence S in , and obtain the occurrence positions of m keywords Ponit={p 1 ,p 2 ,...,p m}, all occurrences form the set of occurrences of S in the document, where p i for keywords i I...
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More
PUM
Login to View More
Abstract
The invention discloses a document similarity measurement method based on a keyword sequence structure, and the method comprises the steps of storing a document W1 and a document W2, setting a keywordsequence, and searching a position set where all keywords in the keyword sequence appear in the document W1 and the document W2; generating the feature sets of the keyword sequences in the documentsW1 and W2 according to the positions where the keywords appear so as to obtain the structural feature values of the keyword sequences in the documents W1 and W2; and calculating the similarity of thedocuments W1 and W2 with respect to the keyword sequence according to the structural characteristic values of the keyword sequence in W1 and W2. The method is beneficial to avoiding the deviation of the semantic angle measurement similarity of the words and sentences of the document, can avoid the defect that the causal relationship before and after a group of keywords is ignored in document distribution structure feature extraction when the similarity is measured from the angle of the keywords in an existing method, and is stronger in practicability and higher in accuracy.
Description
technical field [0001] The invention relates to the technical field of document similarity measurement, in particular to a method and system for document similarity measurement based on a keyword sequence structure. Background technique [0002] The similarity analysis and calculation between documents has a wide range of applications in information retrieval, data mining, machine translation, document duplication detection and other fields. A brief introduction to common document similarity calculation methods is as follows: cosine similarity, which converts documents into vector models based on keywords, and measures them by calculating the cosine similarity of documents; simple shared lexical method, which calculates the total number of characters of words shared by two documents Divide by the longest document character count to evaluate document similarity. Edit distance, also known as Levenshtein distance, is measured by the minimum number of editing operations require...
Claims
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More
Application Information
Patent Timeline
Application Date:The date an application was filed.
Publication Date:The date a patent or application was officially published.
First Publication Date:The earliest publication date of a patent with the same application number.
Issue Date:Publication date of the patent grant document.
PCT Entry Date:The Entry date of PCT National Phase.
Estimated Expiry Date:The statutory expiry date of a patent right according to the Patent Law, and it is the longest term of protection that the patent right can achieve without the termination of the patent right due to other reasons(Term extension factor has been taken into account ).
Invalid Date:Actual expiry date is based on effective date or publication date of legal transaction data of invalid patent.



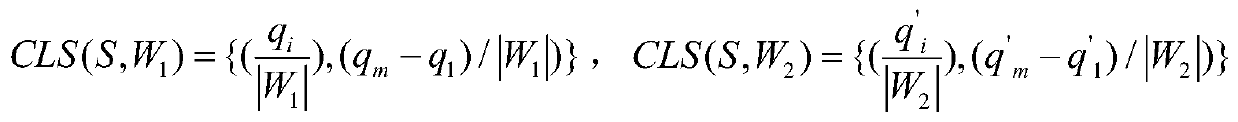
 Login to View More
Login to View More  Login to View More
Login to View More