

Method for searching for approximate sequence of given time sequence from time sequence database
A time series, given time technology, applied in the direction of electrical digital data processing, special data processing applications, instruments, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
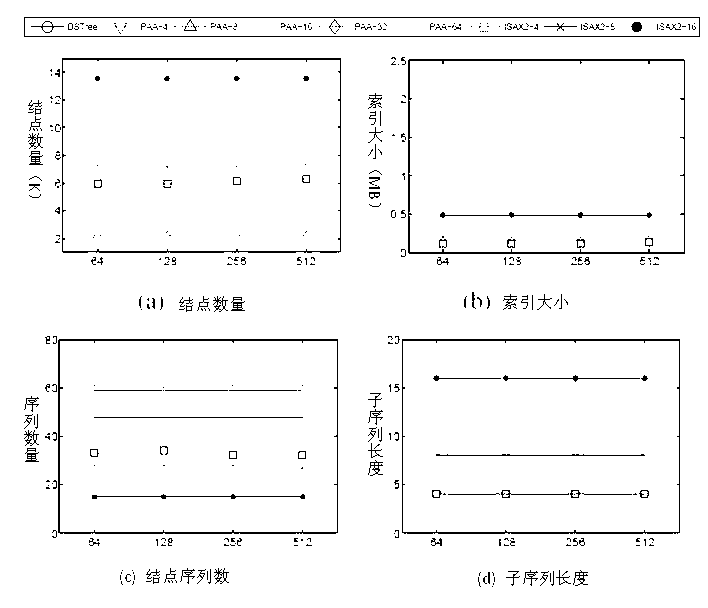
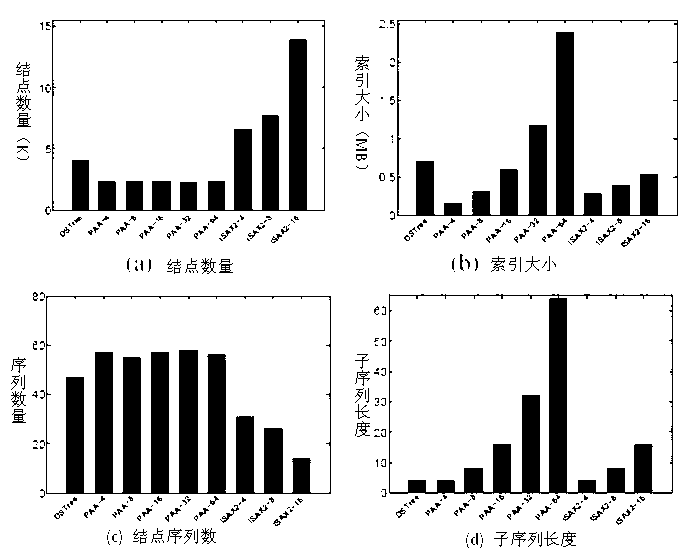
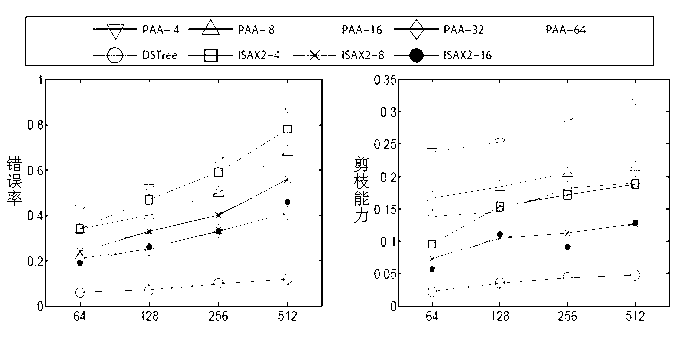
[0042] Next, take the sequence set {(3,3,3,3), (2,2,2,2), (3,3,4,4)} as an example to illustrate the index construction process, assuming that the node threshold is 2. The index building process is as follows:
[0043] 1. Establish the root node root;
[0044] 2. Insert the first piece of data (3,3,3,3), the root is empty, put it in the root, the average value field of root is updated to [3,3], and the standard deviation value field is updated to [0,0 ];
[0045] 3. Insert the second piece of data (2,2,2,2), the root has two pieces of data, which do not exceed the threshold, the average value range is updated to [2,3], and the standard deviation value range is updated to [0,0] ;
[0046] 4. Insert the third piece of data (3,3,4,4), update the root average value to [2,3.5], update the standard deviation to [0,0.5], the number of sequences in the node exceeds the threshold, Consider node splitting, =2.5;
[0047] 5. Consider the case of splitting according to the average ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More