

Self-service terminal based on microphone array voice interaction
A self-service terminal and microphone array technology, applied in speech analysis, speech recognition, instruments, etc., can solve problems such as difficult operation and poor speech understanding, and achieve the effect of suppressing collection, convenient and simple operation, and good use effect.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0024] In order to illustrate the technical solutions of the present invention more clearly, the technical solutions of the various embodiments of the present invention will be described in detail below in conjunction with the accompanying drawings.
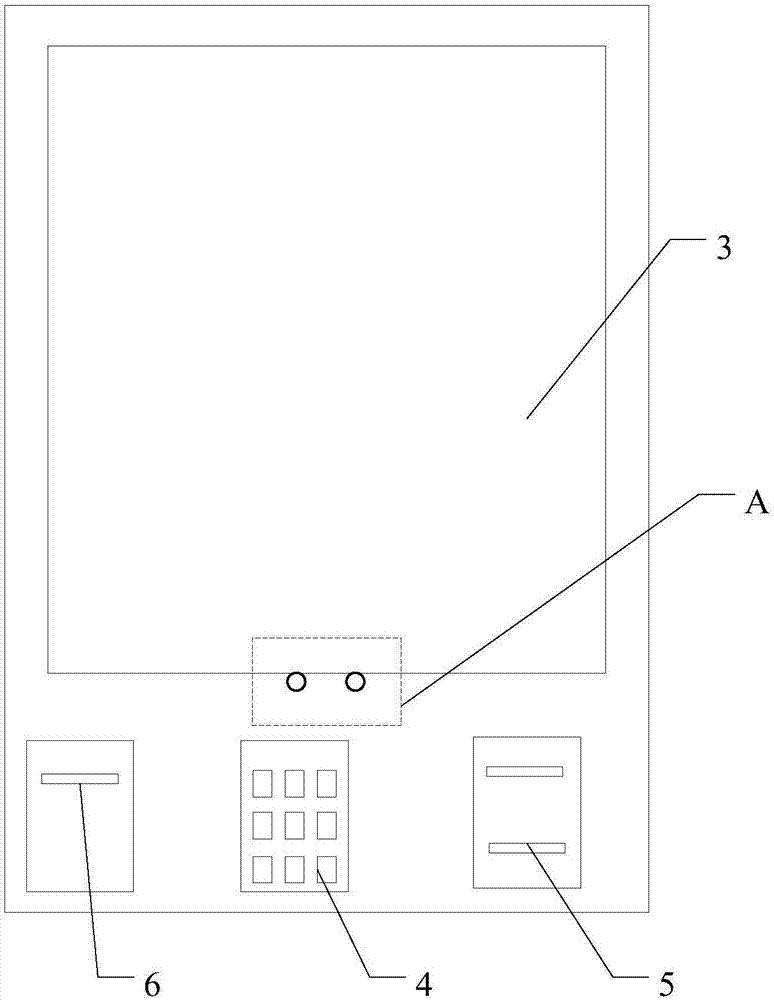
[0025] The present invention proposes a self-service terminal based on microphone 11 array voice interaction, such as figure 1 As shown, the self-service terminal includes: a voice interaction system 1, which is used to collect user voice and convert it into instructions;
[0026] The control module 2 is configured to receive the instruction, and output the service required by the user according to the instruction;
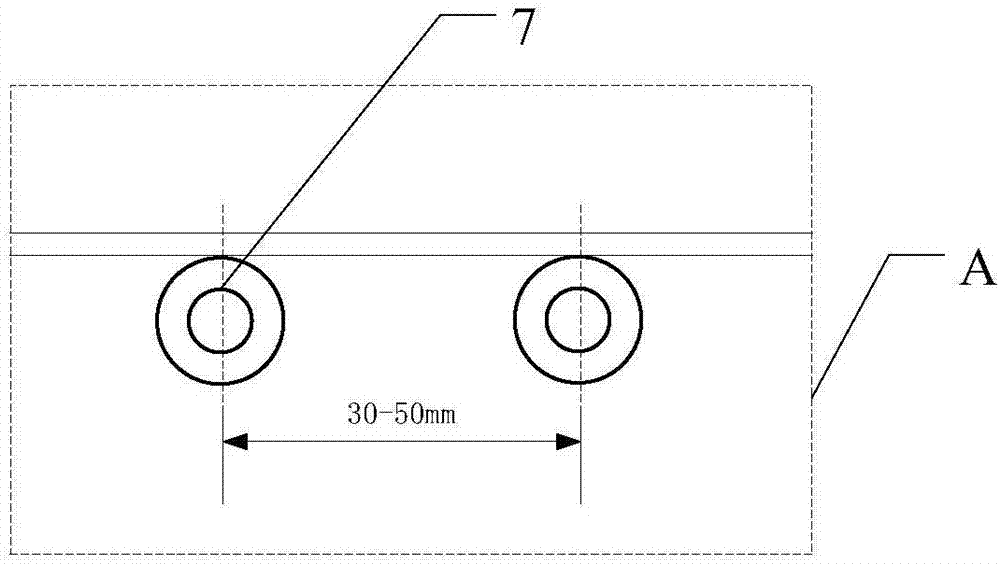
[0027] The voice interaction system 1 includes a microphone 11 array composed of at least two microphones 11 for collecting user voice.
[0028] In this embodiment, the self-service terminal refers to a device that is used in industries such as communication, finance, government, transportation, medical care, indust...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More