

Probability clustering method of cross-categorical data based on key word
A clustering method and entry technology, applied in the field of probabilistic clustering of cross-type data, can solve the problem of not considering the uncertainty of the clustering process, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

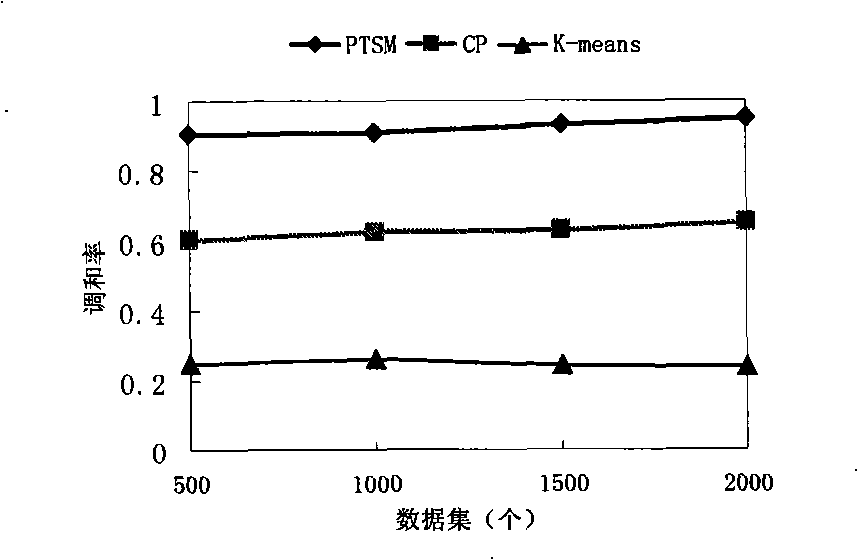
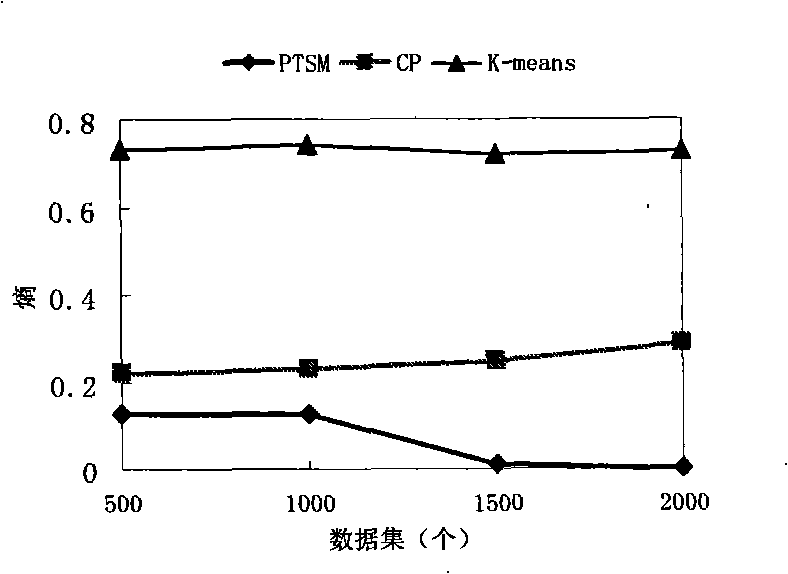
Examples
Embodiment Construction
[0080] An embodiment of the invention:
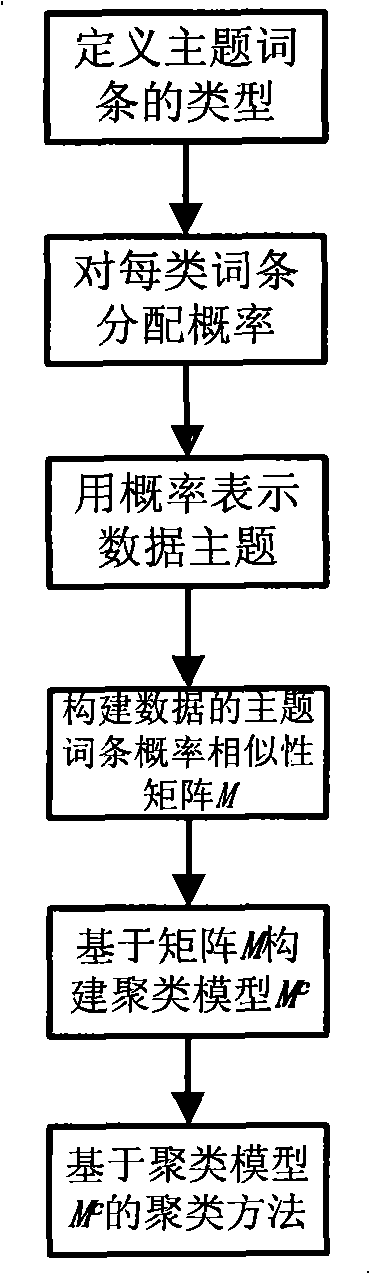
[0081] (1) Define the type of subject entry and rank the entries by weight
[0082] assuming d 1 and d 2 are two data in the data space, T(d 1 ) and T(d 2 ) respectively represent the entry items contained in each data, where T(d 1 ) = {data, index, search, precision, meeting, clustering, lookup, similarity, summary, contains, version}, T(d 2 ) = {data, search, accuracy, session, image, measure, indeterminate}. T(d 1 ) and T(d 2 ) Each entry in ) is given a weight value, and is sorted from high to low according to the weight value, such as Figure 7 (a) and (b) shown.
[0083] (2) Representing data subjects with probabilities
[0084] in d 1 Among them, "data", "index", "search" and "accuracy" are taken as topic-related entries, "meeting" and "clustering" are topic-related semi-related entries, and the rest are topic-irrelevant entries. The weights of "meeting" and "clustering" are 4 and 3 respectively, and d 1The maximum w...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More