

An Efficient Method for Discovering Citation Relationships
A technique for discovering methods, relationships, applied in the field of discovery
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

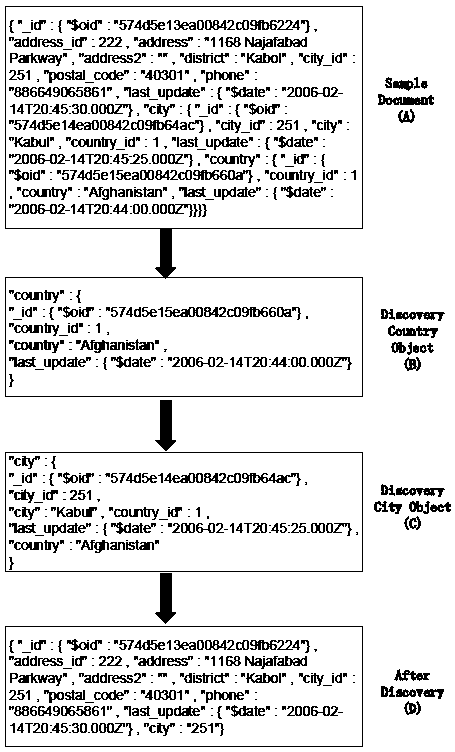
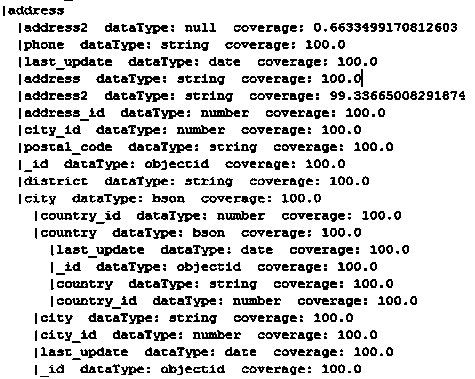
Examples
Embodiment 1
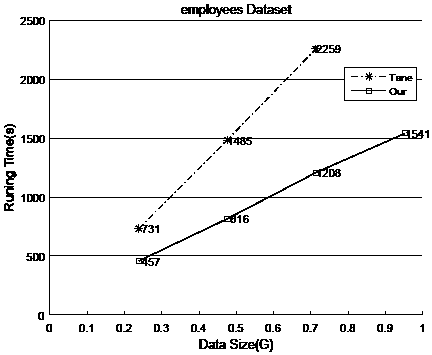
[0032] Example 1: First, we generate the employees data set in MySQL. The employees data set is the official example data set of MySQL. It contains 6 tables and some primary and foreign key relationships. Then, we migrated the data to MongoDB. Based on the primary and foreign key relationship, we embed the employees table into the salaries table.
[0033] Such as figure 2 As shown, in the experiment, we migrated the data to MongoDB one by one. The data volume is 0.238G, 0.476G, 0.714G and 0.953G respectively. 0.238G is a quarter of the total data; 0.476G is half of the total data; 0.714G is three quarters of the total data; 0.953G is the total data. We test these 4 sets of data in a memory environment.
[0034] To sum up, the present invention uses data model information and data type distribution to improve the Tane algorithm, making it more efficient, more suitable for document data sets, and can be used for tasks such as document data set standardization and data cleaning. ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More