

An abstract extraction method combining a page analysis rule and NLP text vectorization
A text vector and extraction method technology, applied in the field of abstract extraction combining page parsing rules and NLP text vectorization, can solve problems such as high computational complexity
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0022] The present invention will be further described in detail below in conjunction with the accompanying drawings.
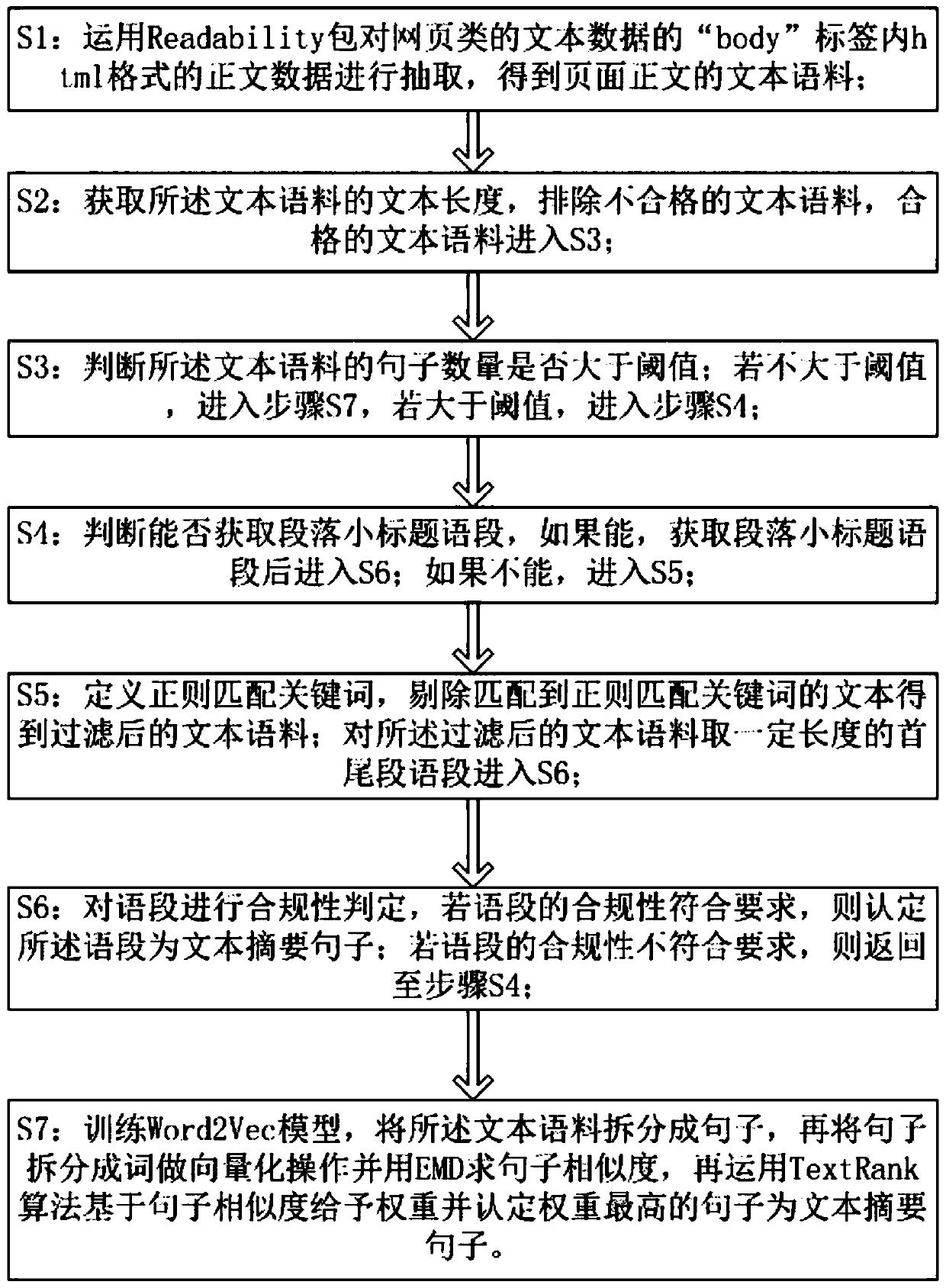
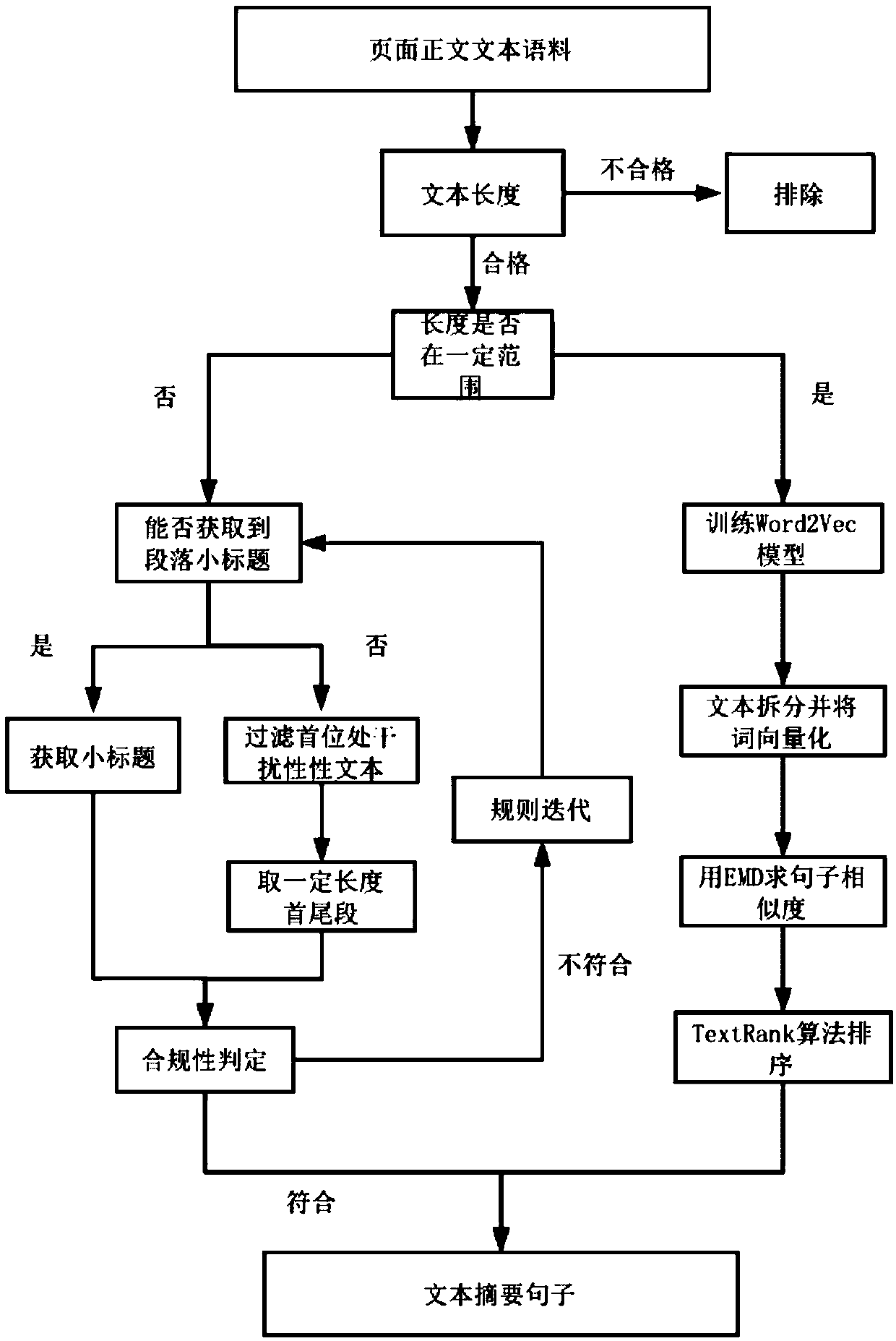
[0023] A method for extracting summaries combining page parsing rules and NLP text vectorization, comprising the following steps:
[0024] S1: Use the Readability package to extract the text data in html format in the "body" tag of the web page text data to obtain the text corpus of the page text.
[0025] For example the body that needs to be extracted:
[0026] from readability.readability import Document
[0027] from scrapy.selector import HtmlXPathSelector
[0028] from scrapy.http import HtmlResponse
[0029] import urllib
[0030] html = urllib.urlopen(url).read()
[0031] content_t = html.split('')[-1].strip().split(' [0032] content_t = ' '+content_t [0033] readable_article = Document(content_t).summary() [0034] response=HtmlResponse(url=", body=readable_article, encoding='utf8') ...PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More