

Clockwork hierarchical variational encoder
A hierarchical and hierarchical technology, applied in the field of clock-based hierarchical variational encoders, can solve problems such as invalidity and lack of expressiveness of synthesized speech.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
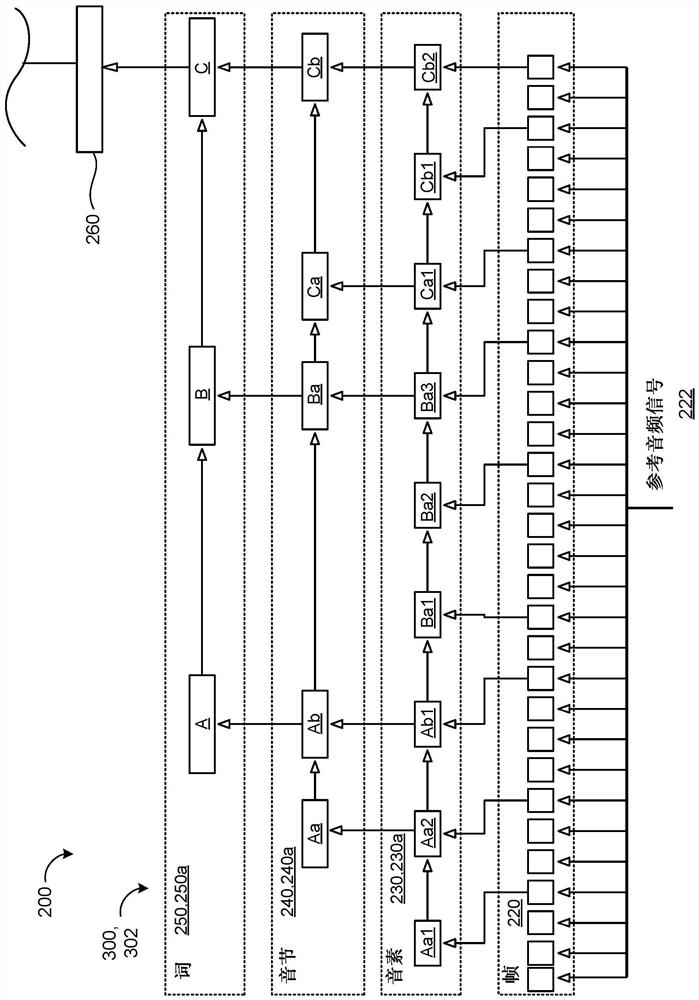
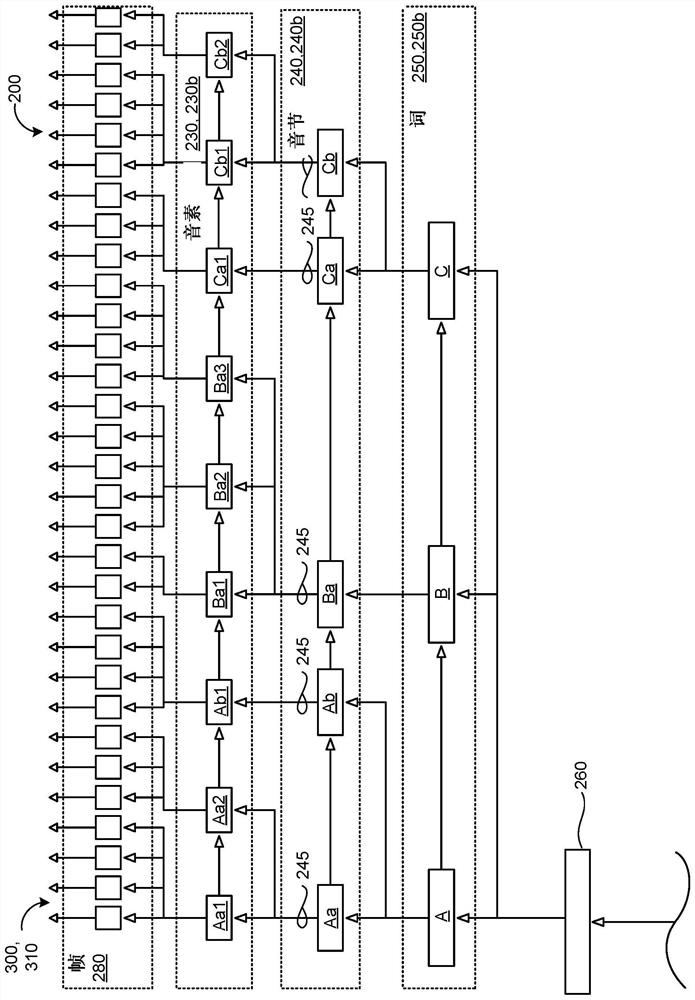
[0025] Text-to-speech (TTS) models commonly used by speech synthesis systems are generally given only a textual input at runtime without any reference acoustic representation, and must impute many linguistic factors not provided by the textual input in order to produce a listening It sounds like real synthetic speech. A subset of these linguistic factors is collectively called prosody, and can include intonation (pitch change), stress (stressed versus unstressed syllables), sound duration, volume, pitch, rhythm, and style of speech. Prosody may indicate the emotional state of speech, the form of speech (eg, statement, question, command, etc.), the presence of speech sarcasm or sarcasm, uncertainty in knowledge of speech, or other language element. Thus, a given textual input associated with high prosody changes can produce a synthesized speech with local changes in pitch and utterance duration to convey different semantic meanings, and also with global changes in the overall ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More