

Face-to-face view and sound multi-view emotion discrimination method and system
A discriminant method and multi-view technology, applied in the field of multi-view learning, can solve the problem of insufficient discrimination accuracy of single-view data
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

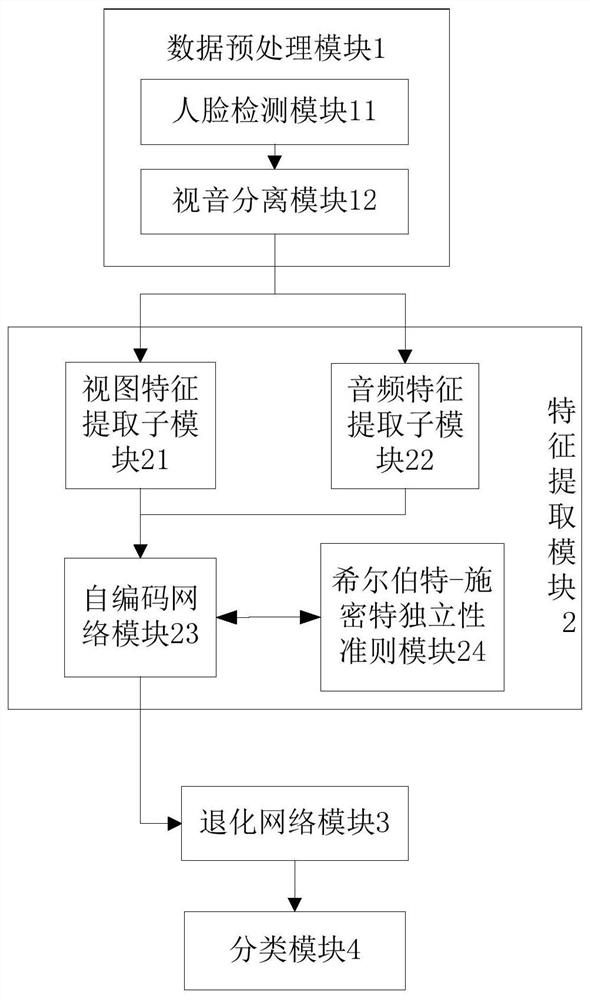
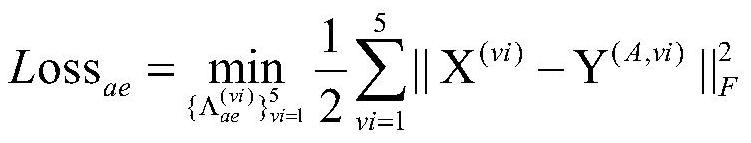
Examples
Embodiment 1
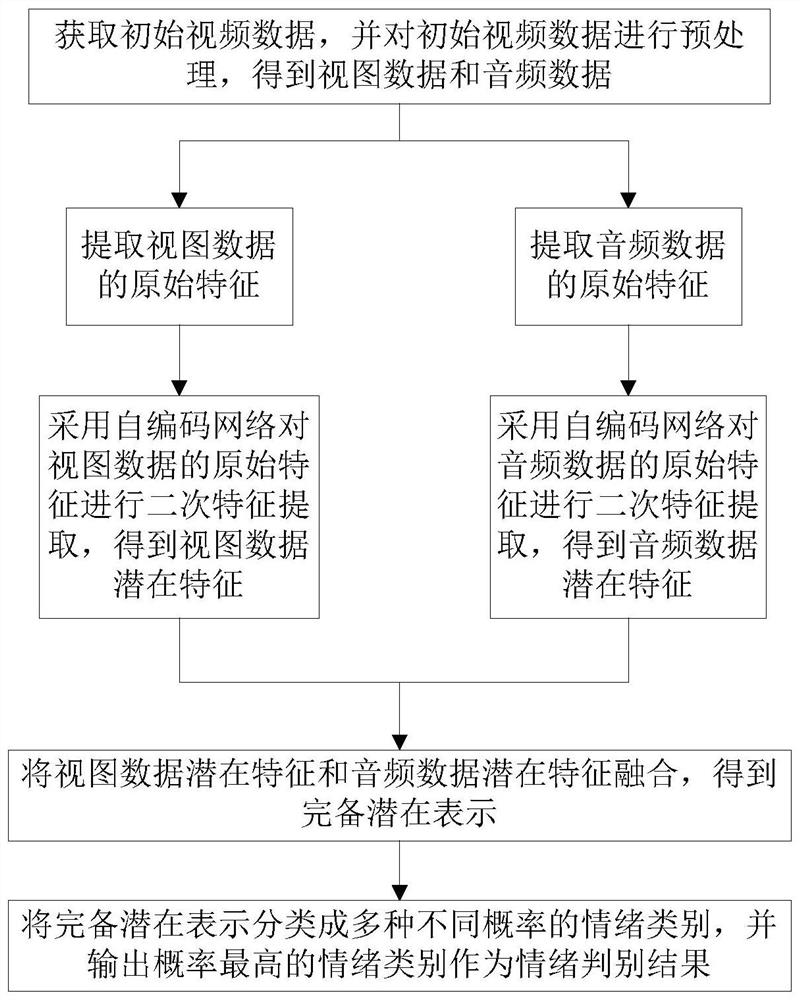
[0059] Such as figure 1 As shown, a face-to-face audio-visual multi-view emotion discrimination method includes the following steps:
[0060] S1: Obtain initial video data, and preprocess the initial video data to obtain view data and audio data;
[0061] S2: Extracting the original features of the view data and the audio data respectively;
[0062] S3: The self-encoding network is used to perform secondary feature extraction on the original features of the view data and audio data, respectively, to obtain the potential features of the view data and the latent features of the audio data;
[0063] S4: Fusion of latent features of view data and latent features of audio data to obtain a complete latent representation;
[0064] S5: Classify the complete latent representation into a variety of emotion categories with different probabilities, and output the emotion category with the highest probability as the emotion discrimination result.
[0065] In the specific implementation ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More