Neural network design and optimization method based on software and hardware joint learning
A neural network and optimization method technology, applied in the field of neural network architecture search, can solve the problems of increased parameters, low efficiency, difficult design, etc., to achieve the effect of precision and speed balance, high precision and speed
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0027] The specific implementation manner and working principle of the present invention will be further described in detail below in conjunction with the accompanying drawings.
[0028] Aiming at the three major problems of the neural network structure search, the search space is too large, the time cost and calculation consumption of the search are huge, and the software and hardware design separation caused by the lack of FPGA information, a neural network design and optimization method based on software and hardware joint learning is proposed. This method uses the method of joint learning of software and hardware to search and optimize the neural network, and specifically includes the following steps:
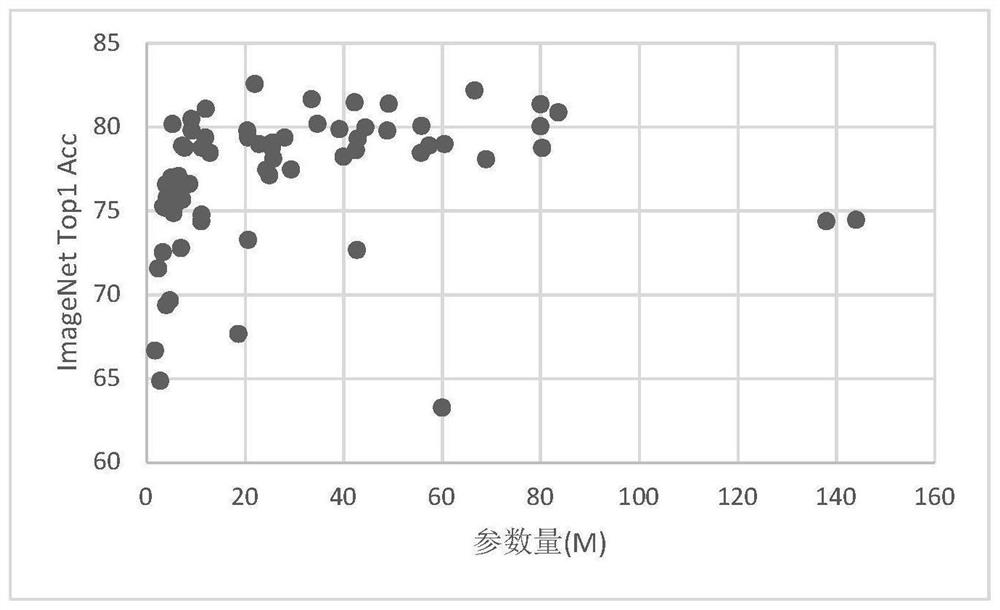
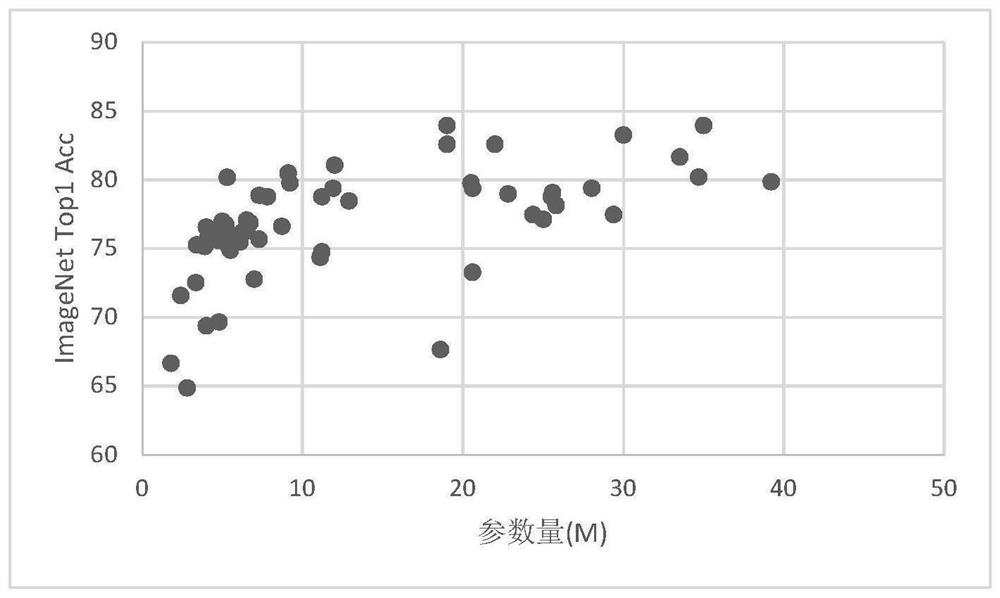
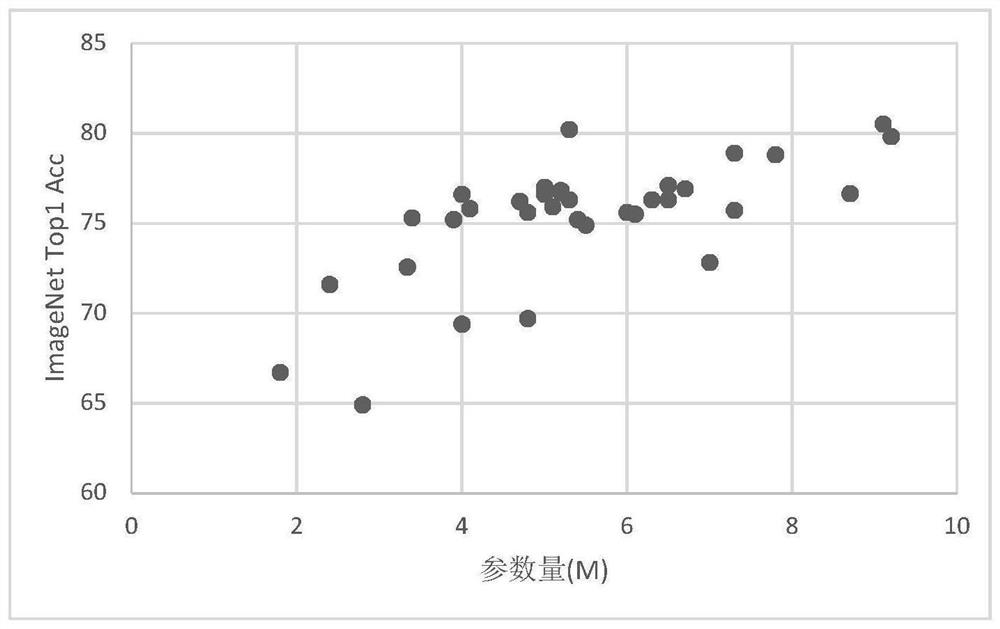
[0029] S1) Statistics on neural network structure rules: Discuss the relationship between the number of nodes, the number of structural blocks, the number of channels, the resolution of input images, the amount of parameters, etc. Regularity of resolution and width.
[003...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



