Method of deriving a compressed acoustic model for speech recognition
An acoustic model and leading technology, applied in speech recognition, speech analysis, instruments, etc., can solve problems such as large amounts of memory
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
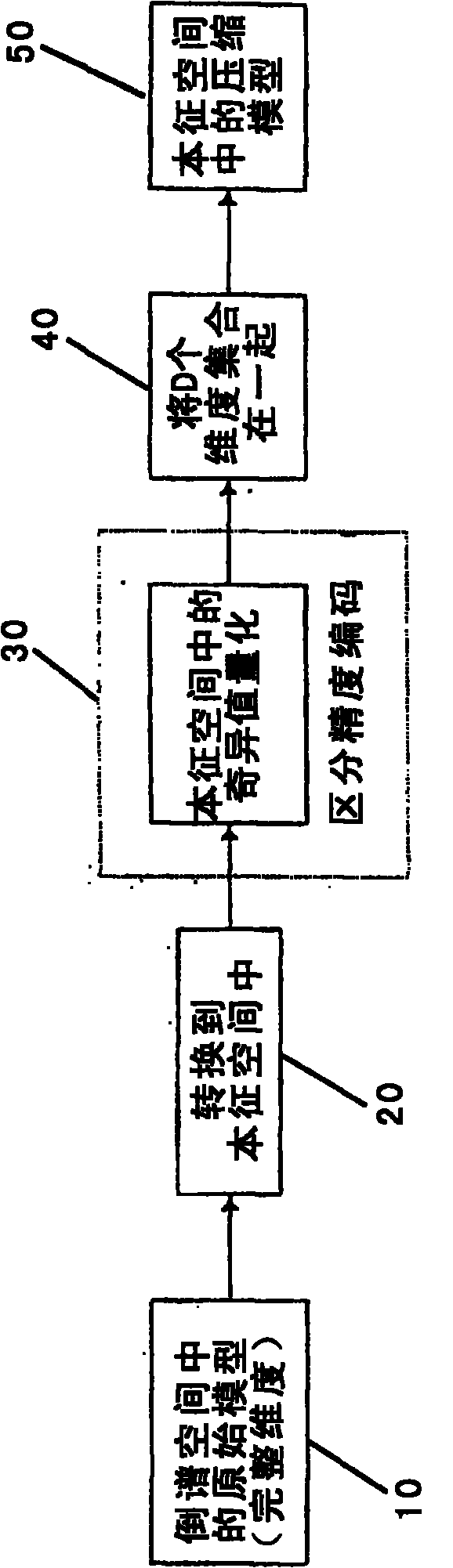
[0019] figure 1 is a block diagram showing a general overview of the preferred process of the present invention for deriving a compressed acoustic model. In step 10, the original uncompressed acoustic model is first transformed and represented in cepstrum space, and in step 20, the cepstrum acoustic model is transformed into eigenspace to determine which parameters of the cepstrum acoustic model are important / useful. In step 30, the parameters of the acoustic model are encoded based on importance / usefulness properties, and then the encoded acoustic features are assembled together in steps 40 and 50 as a compressed model in eigenspace.
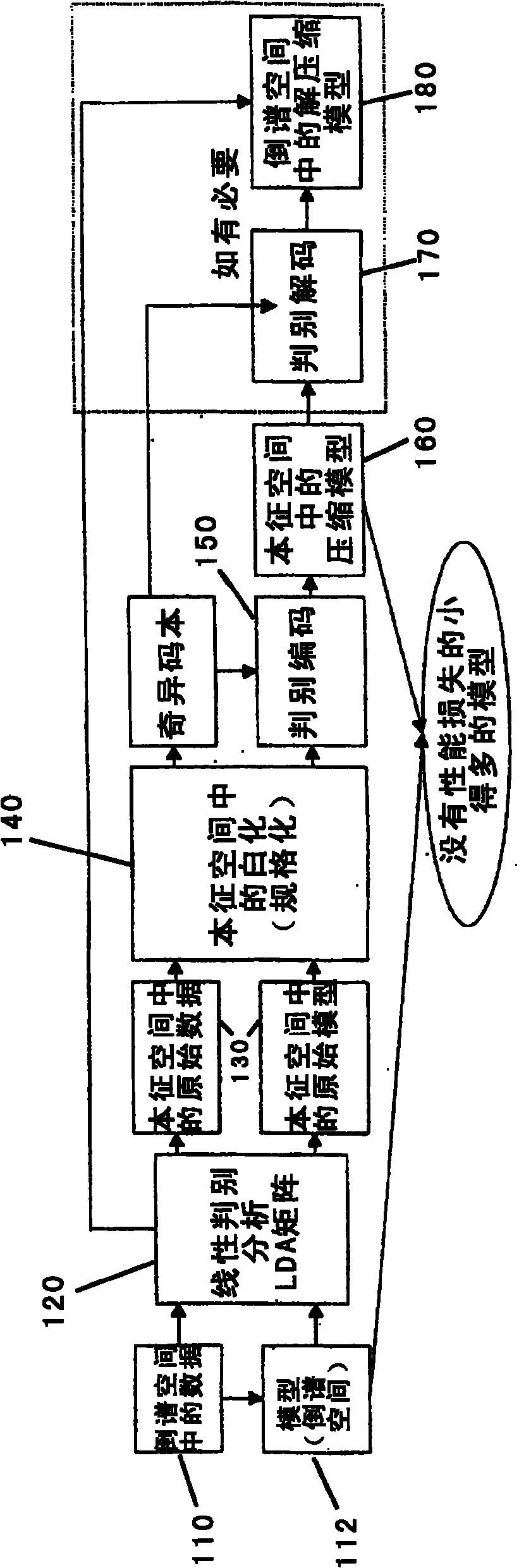
[0020] will now be passed by reference figure 2 to describe each of the above steps in more detail.
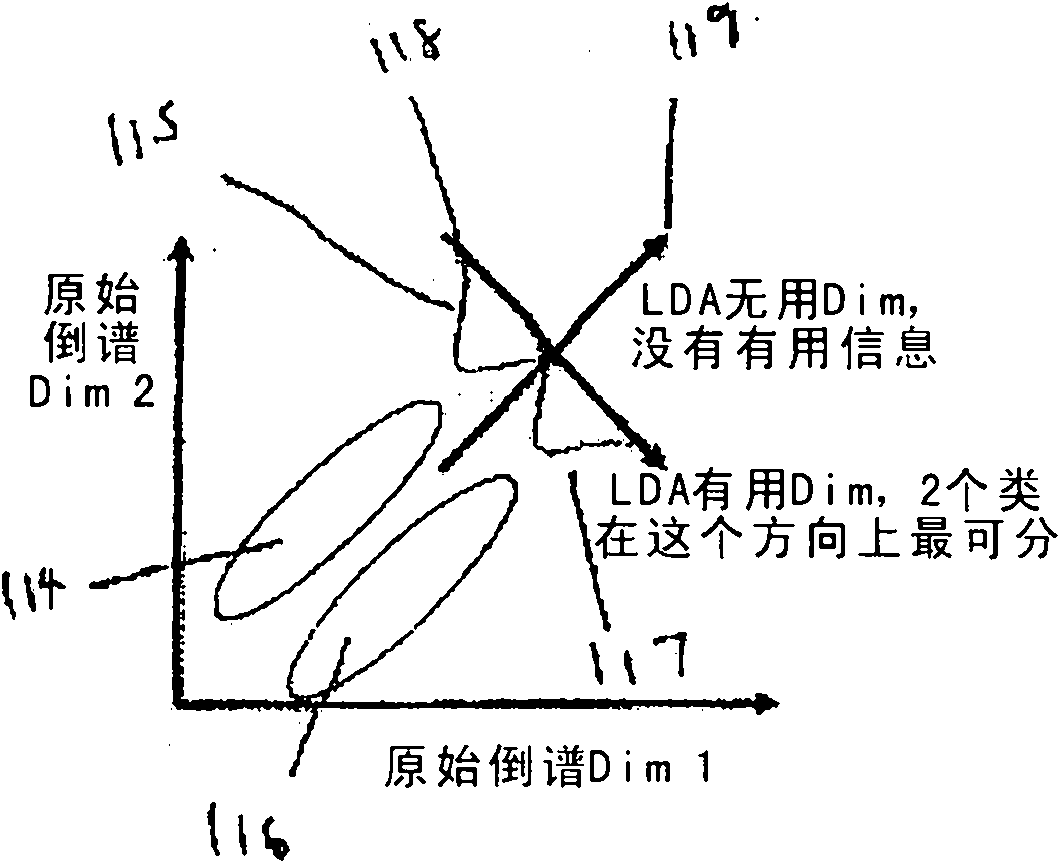
[0021] At step 110, an uncompressed model of the original signal, such as a speech input, is represented in cepstrum space. A sample of the uncompressed original signal model is taken to form the model 112 in cepstral space. The model 11...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com