

Method and device for generating psychoacoustic model
A psychoacoustic model and computing module technology, applied in speech analysis, instruments, etc., can solve the problems of high hardware implementation cost, difficult implementation, high power consumption, etc., and achieve the effects of easy hardware implementation, improved quantization efficiency, and reduced complexity
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
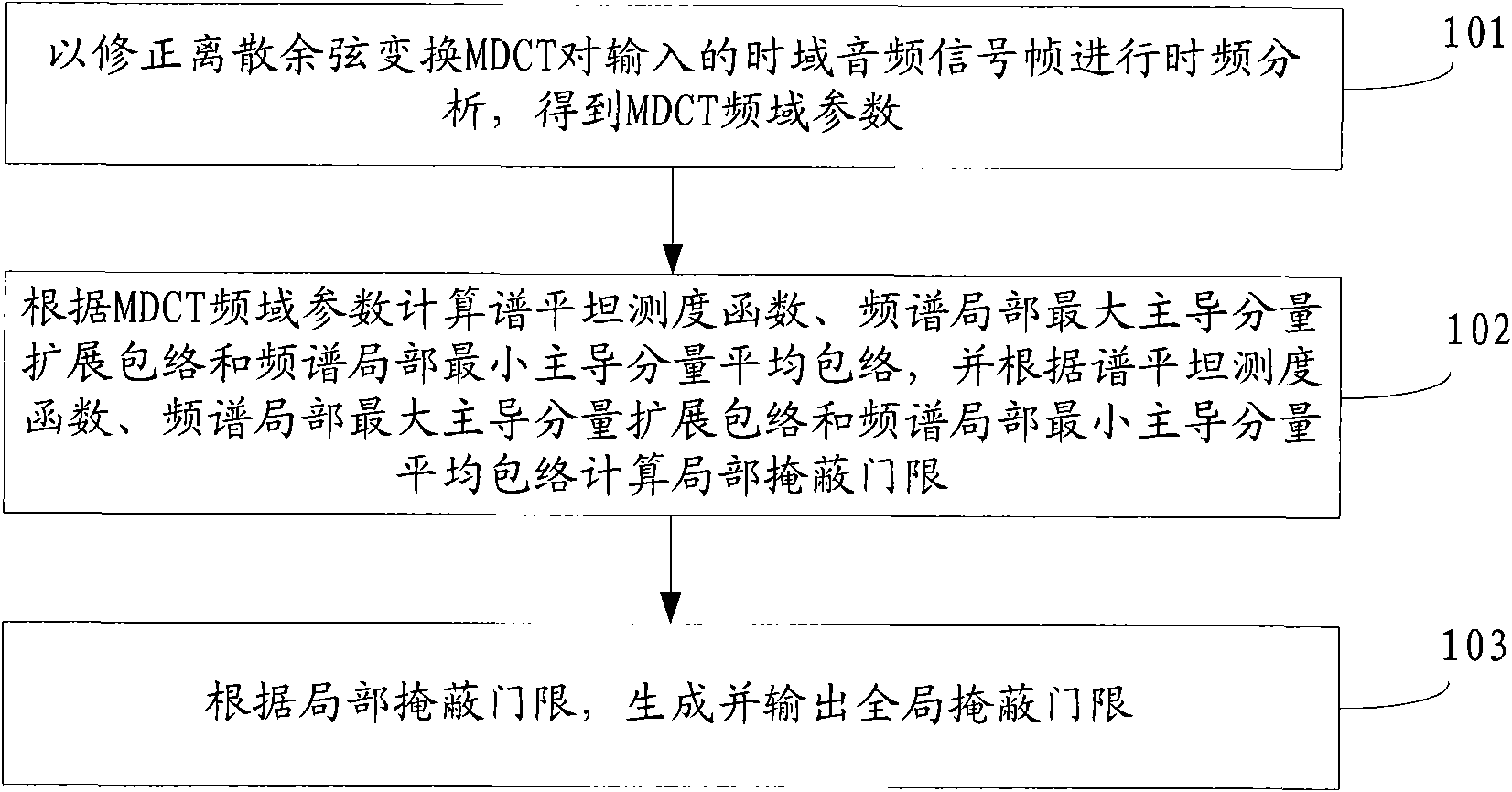
[0049] see figure 1 , this embodiment provides a method for generating a psychoacoustic model, and the process of the method is specifically as follows:
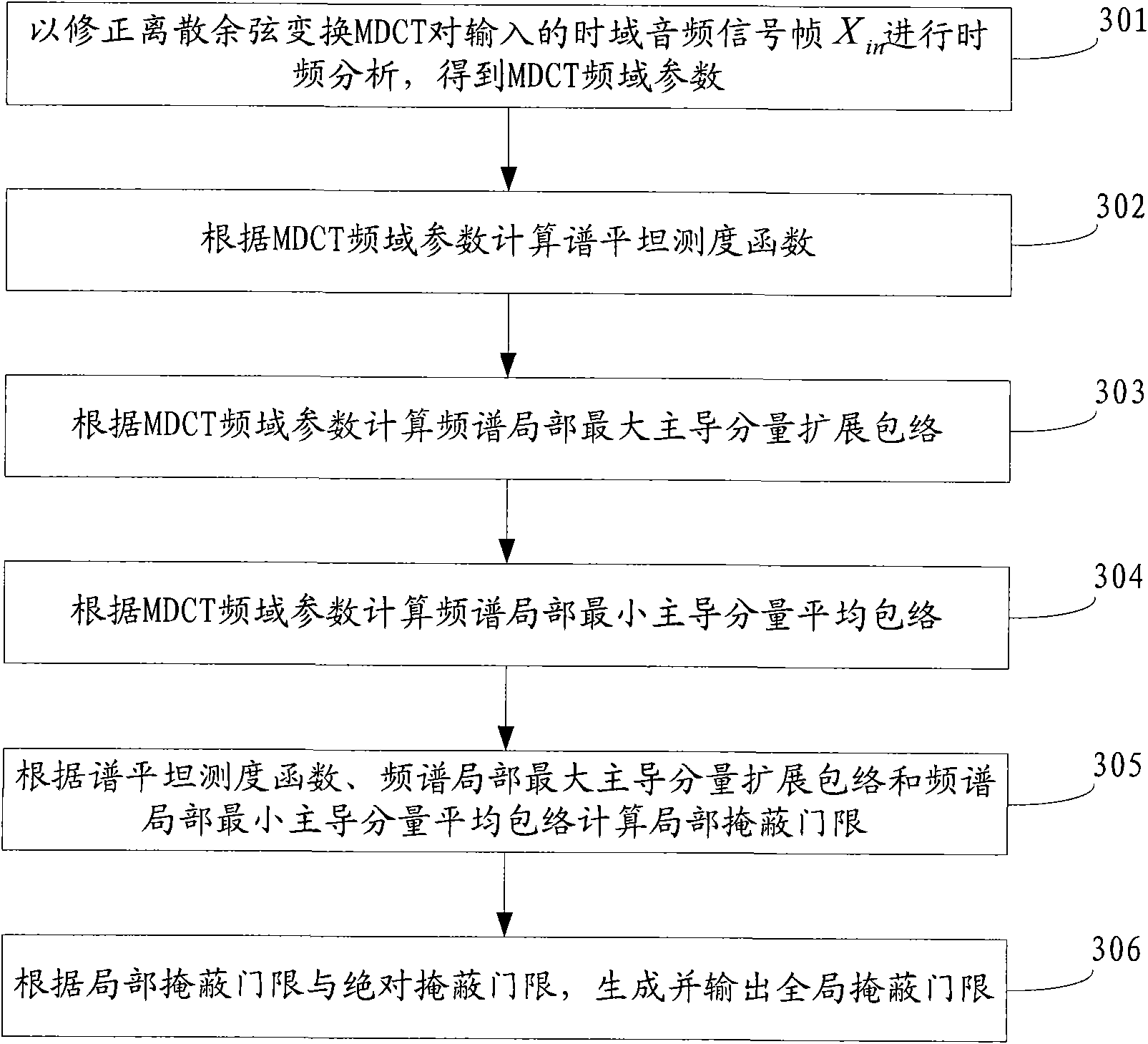
[0050] 101: Perform time-frequency analysis on the input time-domain audio signal frame by Modified Discrete Cosine Transform MDCT to obtain MDCT frequency-domain parameters;
[0051] 102: Calculate the spectrum flatness measure function, the spectrum local maximum dominant component extended envelope and the spectrum local minimum dominant component average envelope according to the MDCT frequency domain parameters, and according to the spectrum flatness measure function, the spectrum local maximum dominant component spread envelope and the spectrum local minimum Dominant component mean envelope calculation local masking threshold;
[0052] 103: Generate and output a global masking threshold according to the local masking threshold.
[0053] The method provided in this embodiment, by using the spectral flatness measure fu...
Embodiment 2
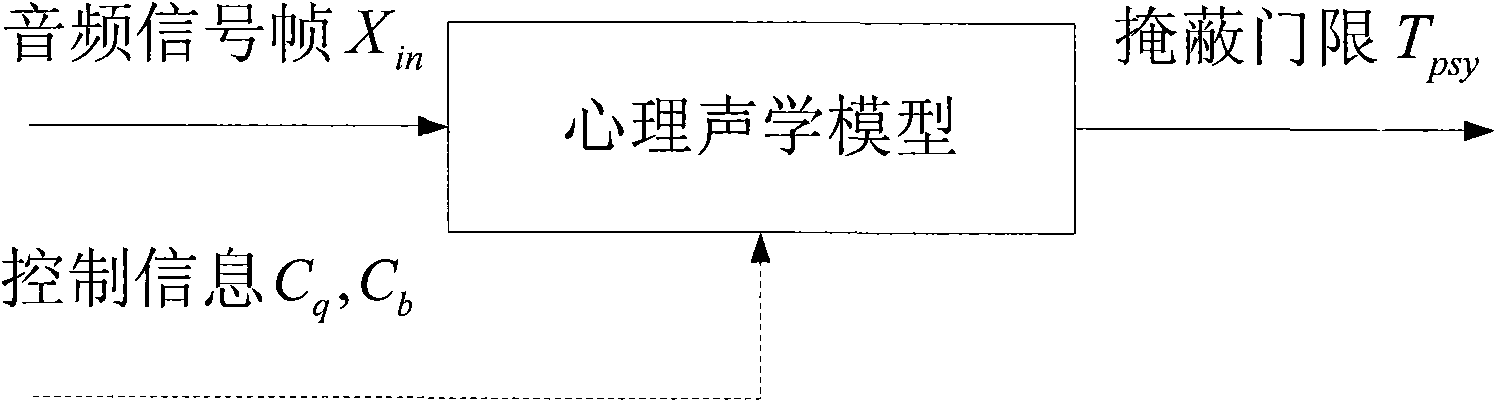
[0055]In order to solve the problems that the algorithm of the existing psychoacoustic model is too complicated and the audio analysis performance cannot meet the needs of audio processing, this embodiment provides a method for generating a psychoacoustic model, through which a method based on modified discrete A psychoacoustic model of cosine transform (MDCT) and spectral flatness measure function (SpectralFlatness Measure, SFM). The psychoacoustic model considers the characteristics of pitch masking and non-tone masking, so that the coding efficiency can be improved.
[0056] Among them, the input-output relationship of the psychoacoustic model can be as follows: figure 2 As shown, the input signal is the time-domain audio signal frame X to be processed or coded in , the audio signal can be a speech signal, an audio signal or a mixed signal of various sound signals that can be heard by the human ear, and the frequency bandwidth of the signal includes all frequency ranges th...
Embodiment 3
[0127] see Figure 22 , the present embodiment provides a device for generating a psychoacoustic model, the device comprising:
[0128] The time-domain analysis module 2201 is used to perform time-frequency analysis on the input time-domain audio signal frame with Modified Discrete Cosine Transform MDCT to obtain MDCT frequency-domain parameters;
[0129] The first calculation module 2202 is used to calculate the spectral flatness measure function according to the MDCT frequency domain parameters obtained by the time domain analysis module 2201;
[0130] The second calculation module 2203 is used to calculate the local maximum dominant component extended envelope of the spectrum according to the MDCT frequency domain parameters obtained by the time domain analysis module 2201;
[0131] The third calculation module 2204 is used to calculate the average envelope of the local minimum dominant component of the frequency spectrum according to the MDCT frequency domain parameters o...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More