

A Chinese word segmentation method based on deep learning
A technology of deep learning and Chinese word segmentation, applied in instruments, biological neural network models, calculations, etc., can solve problems such as gradient disappearance, inability to handle long-distance historical memory, and recurrent neural network gradient explosion
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
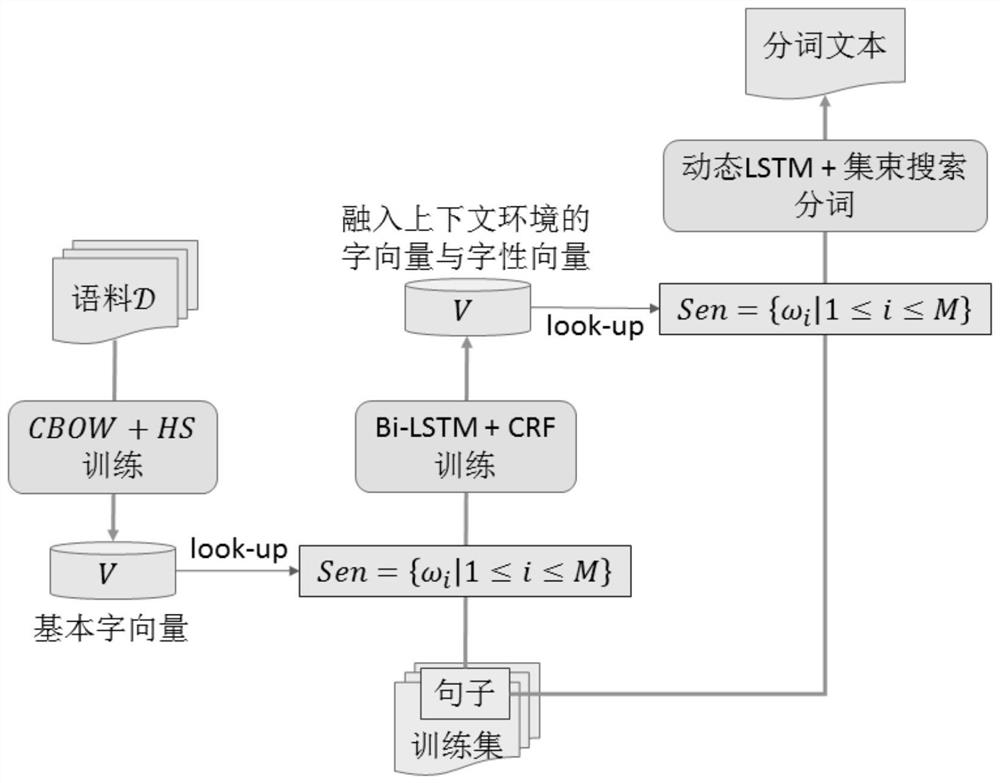
[0252] A Chinese word segmentation method based on deep learning, comprising the following steps:
[0253] Step 1: Perform literal word frequency statistics on the large-scale corpus D. Based on the CBOW model and the HS training method, each word in the corpus D is initialized as a basic distributed font vector, and the obtained font vectors are indexed by index. Save to dictionary V.
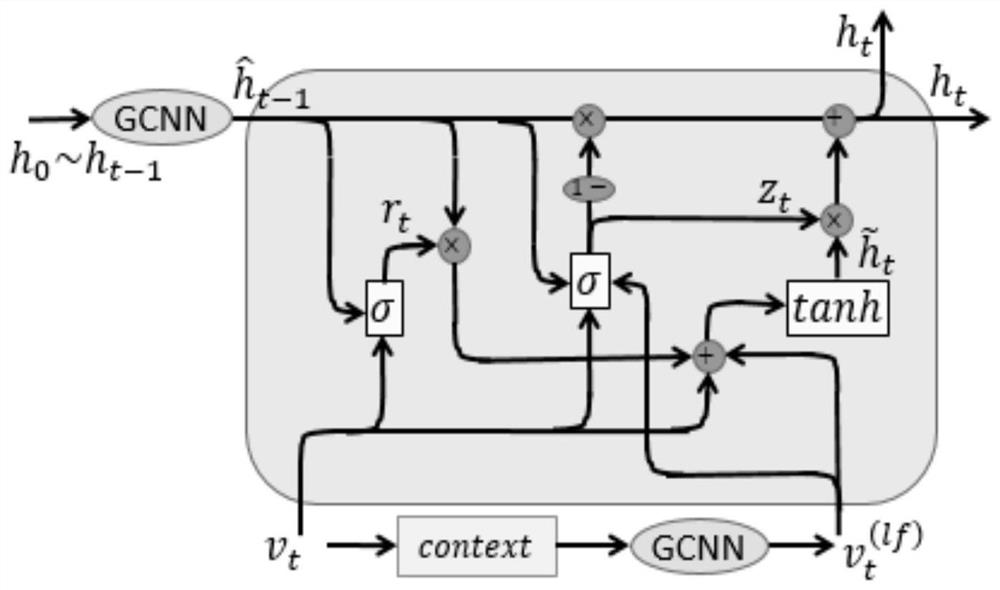
[0254] Step 2: Convert the training corpus into a fixed-length vector sentence by sentence, and send it into the improved bidirectional LSTM model. By training the parameters in the bidirectional LSTM model, the character-level literal vector in the dictionary V is refined and updated to obtain A feature vector carrying contextual semantics and a vector containing word features.
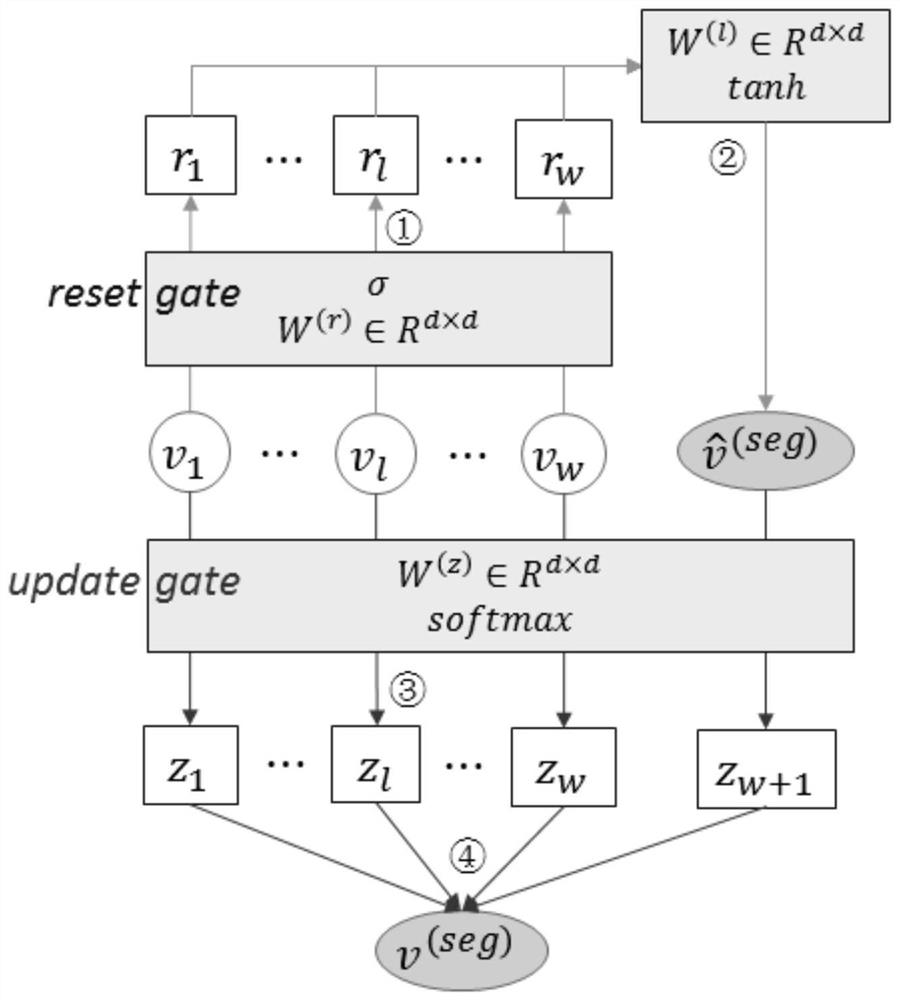
[0255] Step 3: For each training sentence, when training word by word, use the idea of full segmentation to segment all candidate words ending with the current word within the maximum word length range, and fuse t...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More