Image recognition and neural network model training method, device and system
A neural network model and image recognition technology, applied in the field of image processing, can solve the problem of unbalanced performance of traditional models, and achieve the effect of balancing image recognition performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0047] In order to make the purpose, technical solution and advantages of the present application clearer, the present application will be further described in detail below in conjunction with the accompanying drawings and embodiments. It should be understood that the specific embodiments described here are only used to explain the present application, and are not intended to limit the present application.
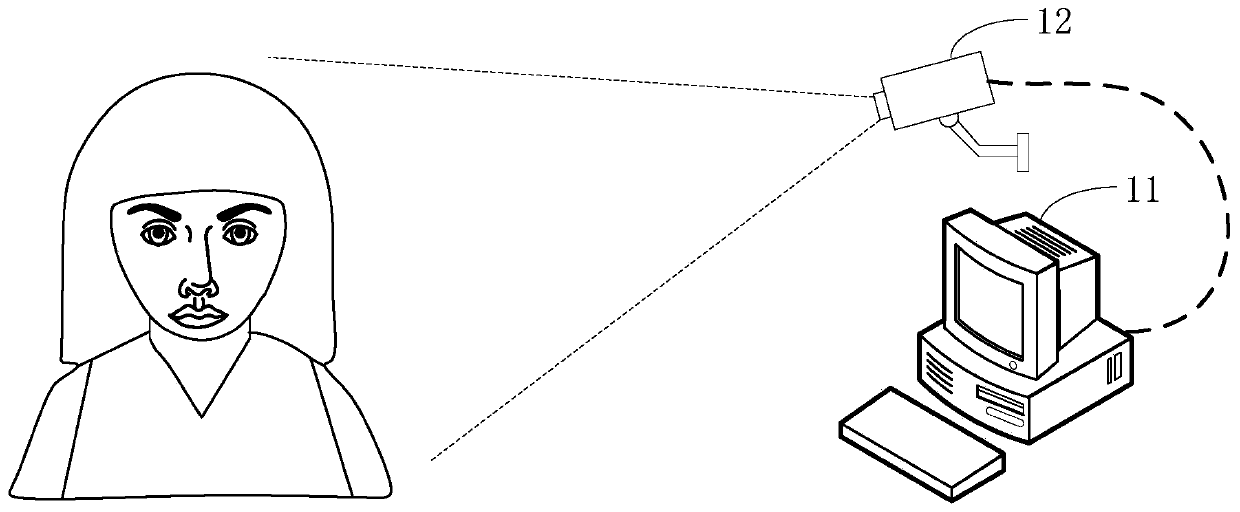
[0048] The image recognition method provided by this application can be applied, but not limited to, such as figure 1 shown in the application environment. Wherein, the photographing device 12 can obtain the image to be recognized of the object to be recognized, and send the image to be recognized to the computer device 11; the computer device 11 can extract the target image feature from the image to be recognized, and perform image processing according to the target image feature. Image recognition processing such as verification, image search, image clustering, etc. Wh...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



