

Electronic official document entity extraction method
An entity extraction, electronic document technology, applied in electronic digital data processing, unstructured text data retrieval, special data processing applications, etc., can solve problems such as overfitting and inability to achieve generalization capabilities.
Pending Publication Date: 2019-10-01
CETC BIGDATA RES INST CO LTD
View PDF9 Cites 27 Cited by
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
However, deep learning methods generally require a large amount of labeled corpus, otherwise it is very easy to overfit and fail to achieve the expected generalization ability
Method used
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
View moreImage
Smart Image Click on the blue labels to locate them in the text.
Smart ImageViewing Examples

Examples
Experimental program
Comparison scheme
Effect test
Embodiment 1
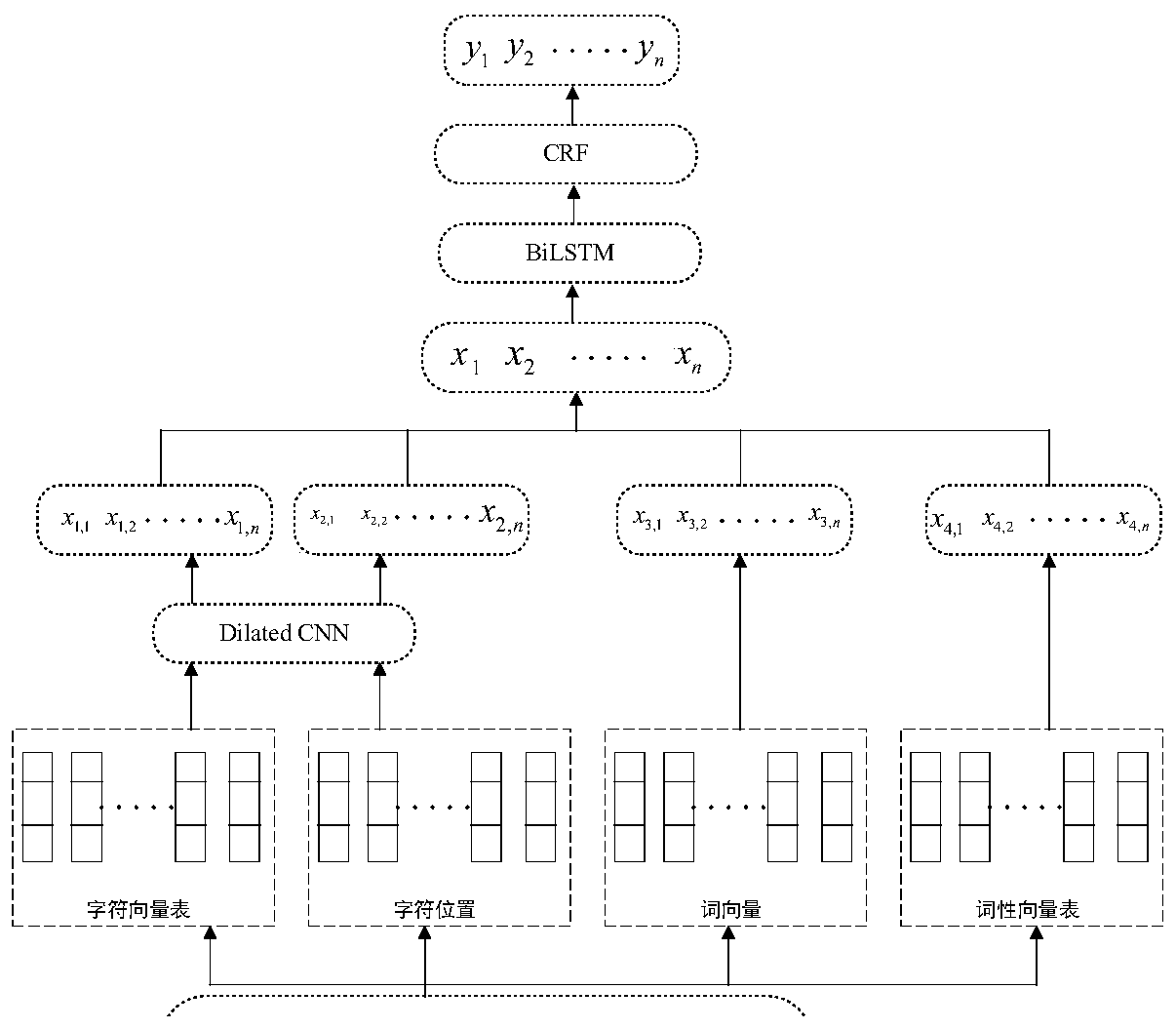
[0070] Using the above scheme as the Dilated CNN-BiLSTM-CRF algorithm scheme, and comparing the schemes using the three algorithms of LSTM, BiLSTM, and BiLSTM-CRF, the electronic document entity extraction is performed, and the results shown in Table 1 are obtained:
[0071] Table 1 Comparison result table
[0072] Model Accuracy / % Recall / % F value / % LSTMs 81.65 80.17 80.90 BiLSTM 83.22 82.59 82.90 BiLSTM-CRF 86.57 85.23 85.89 Dilated CNN-BiLSTM-CRF 91.59 91.08 91.33
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More PUM
 Login to View More
Login to View More Abstract
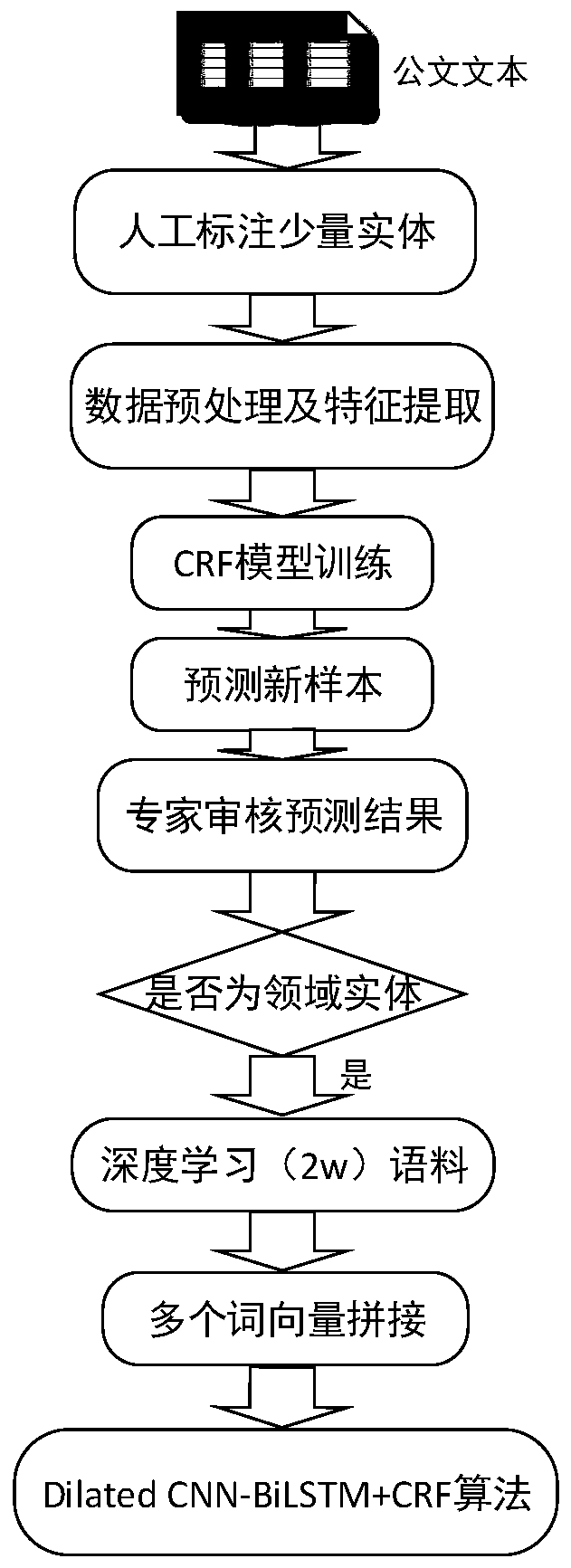
The invention provides an electronic official document entity extraction method. The electronic official document entity extraction method comprises the following steps: A, preprocessing; B, constructing features; C, training an entity extraction model; D, obtaining a corpus; E, obtaining a word vector; F, training an algorithm model. According to the method, a traditional sequence labeling algorithm and a deep learning algorithm are combined, the advantage that a traditional sequence algorithm needs less corpus labeling is utilized, a semi-supervised method is adopted to expand corpuses, andthe problem that time and labor are wasted when a large number of corpuses need to be manually labeled in the deep learning algorithm is solved. Maximum forward and reverse dictionaries, syntax and semantic features are added into the CRF model, and front and rear boundary word features of entity words are fully considered, so that the algorithm has generalization ability. A dilated CNN and BiLSTM-CRF are combined, the dilated CNN takes a character-level vector and a character-level position feature as external features, and the external features and a part-of-speech vector are spliced into aword vector, so that more semantics and up-and-down related information can be expressed to a certain extent.
Description
technical field [0001] The invention relates to an electronic document entity extraction method, in particular to an electronic document entity extraction method based on a semi-supervised dilatedCNN-BiLSTM-CRF. Background technique [0002] Official documents are written by specific departments and agencies, which not only have legal effect as evidence of policy activities, but also contain a large amount of professional policy knowledge, which contains a large amount of entity information, such as: name of person, place name, issuing agency, organization name, name of scientific research project, time , events, etc., as long as they are special text fragments required by the business, they can be called entities. Extracting these entities or concepts is the premise of official document word segmentation, dependency syntax analysis, and grammatical analysis. work plays an important role. Therefore, how to more accurately identify entities from official documents has become...
Claims
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More Application Information
Patent Timeline
 Login to View More
Login to View More Patent Type & AuthorityApplications(China)
IPC IPC(8): G06F16/36G06F17/27G06N3/04
CPCG06F16/367G06F16/374G06N3/049G06F40/216G06F40/211G06F40/30
Inventor陈达纲李泽源李泽松刘昆南宋亚军王鹏
OwnerCETC BIGDATA RES INST CO LTD