

Method for selecting reward function in adversarial imitation learning
A reward function and function technology, applied in the field of reward function selection in adversarial imitation learning, can solve problems such as not being able to achieve optimality
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
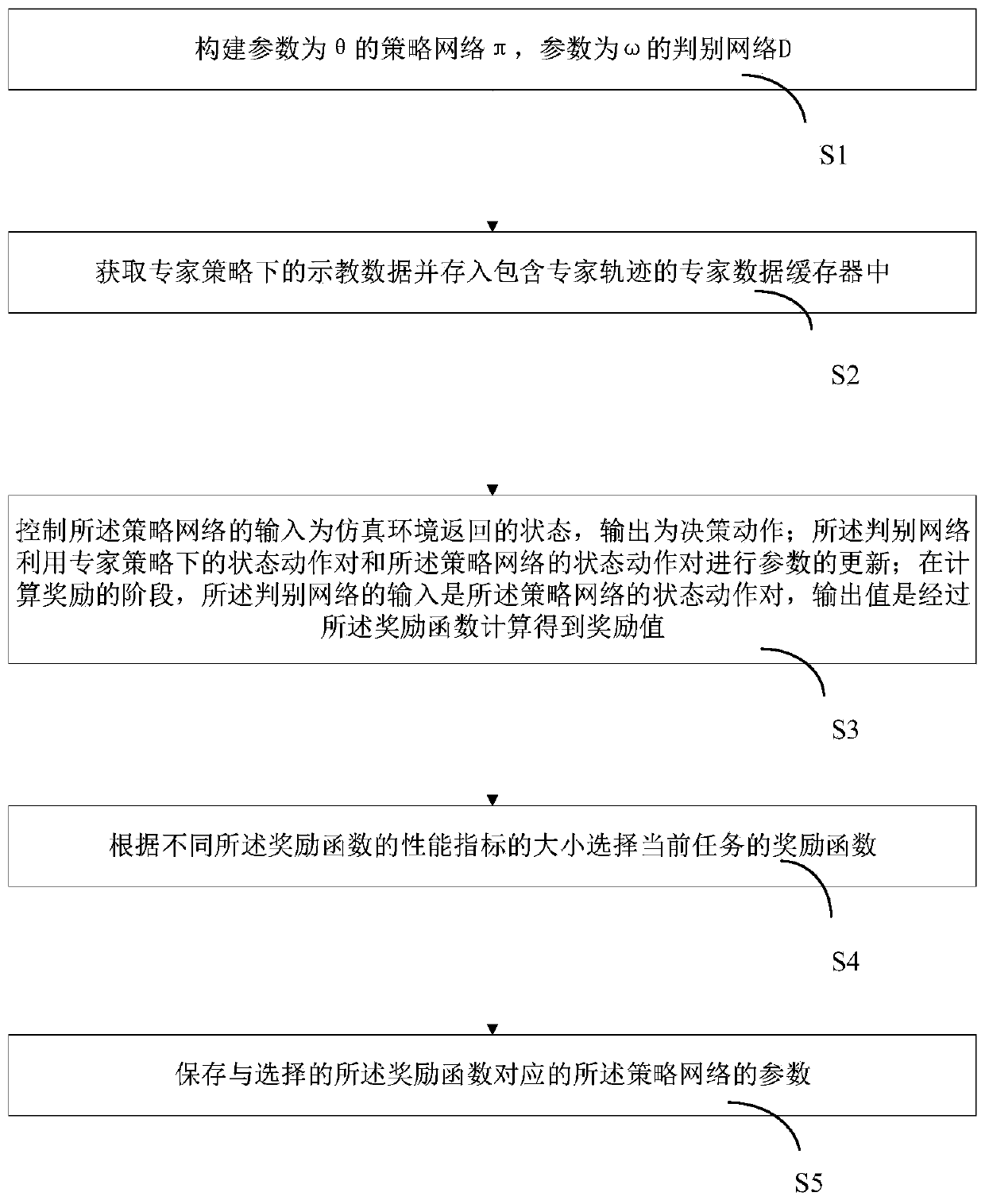
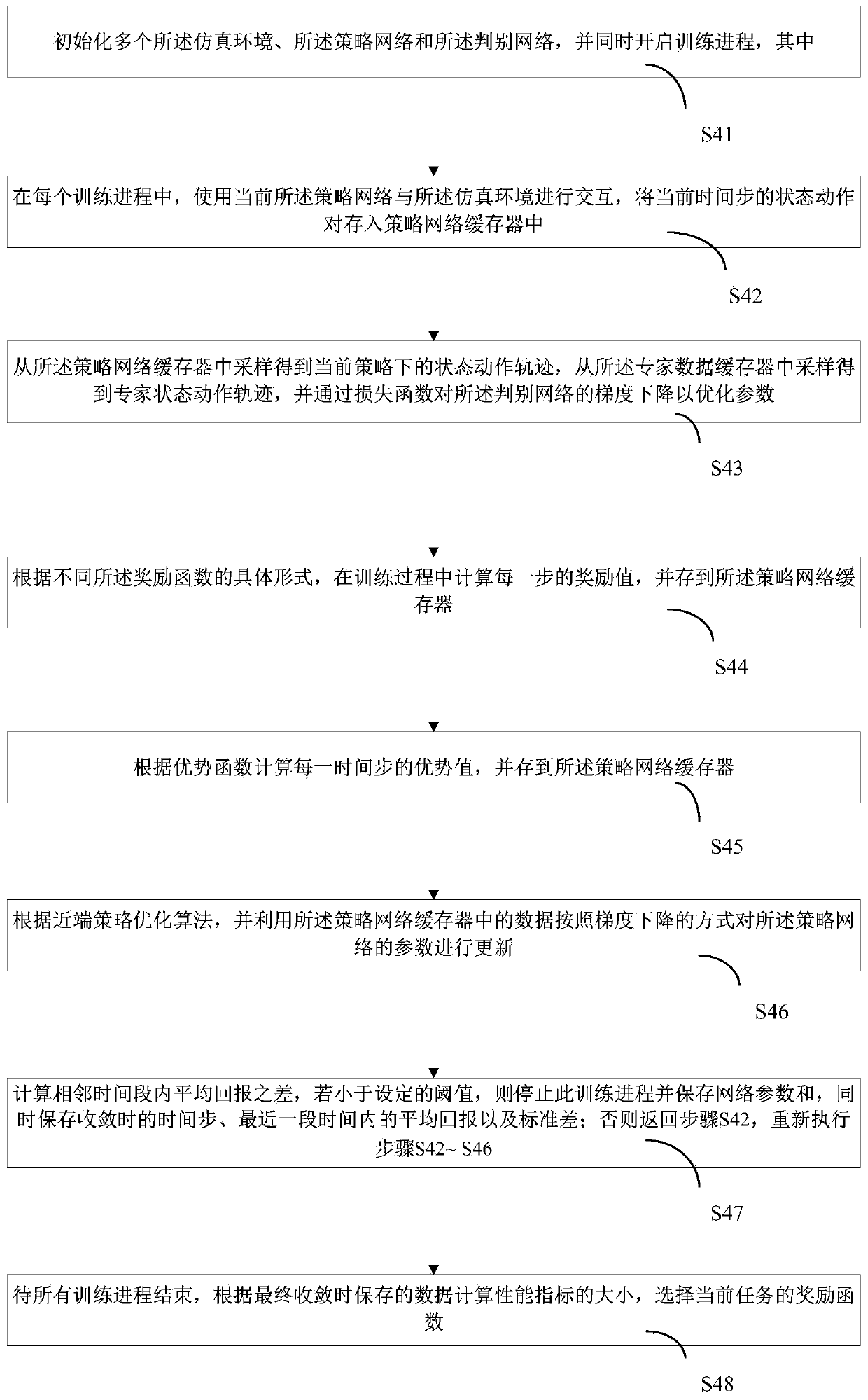
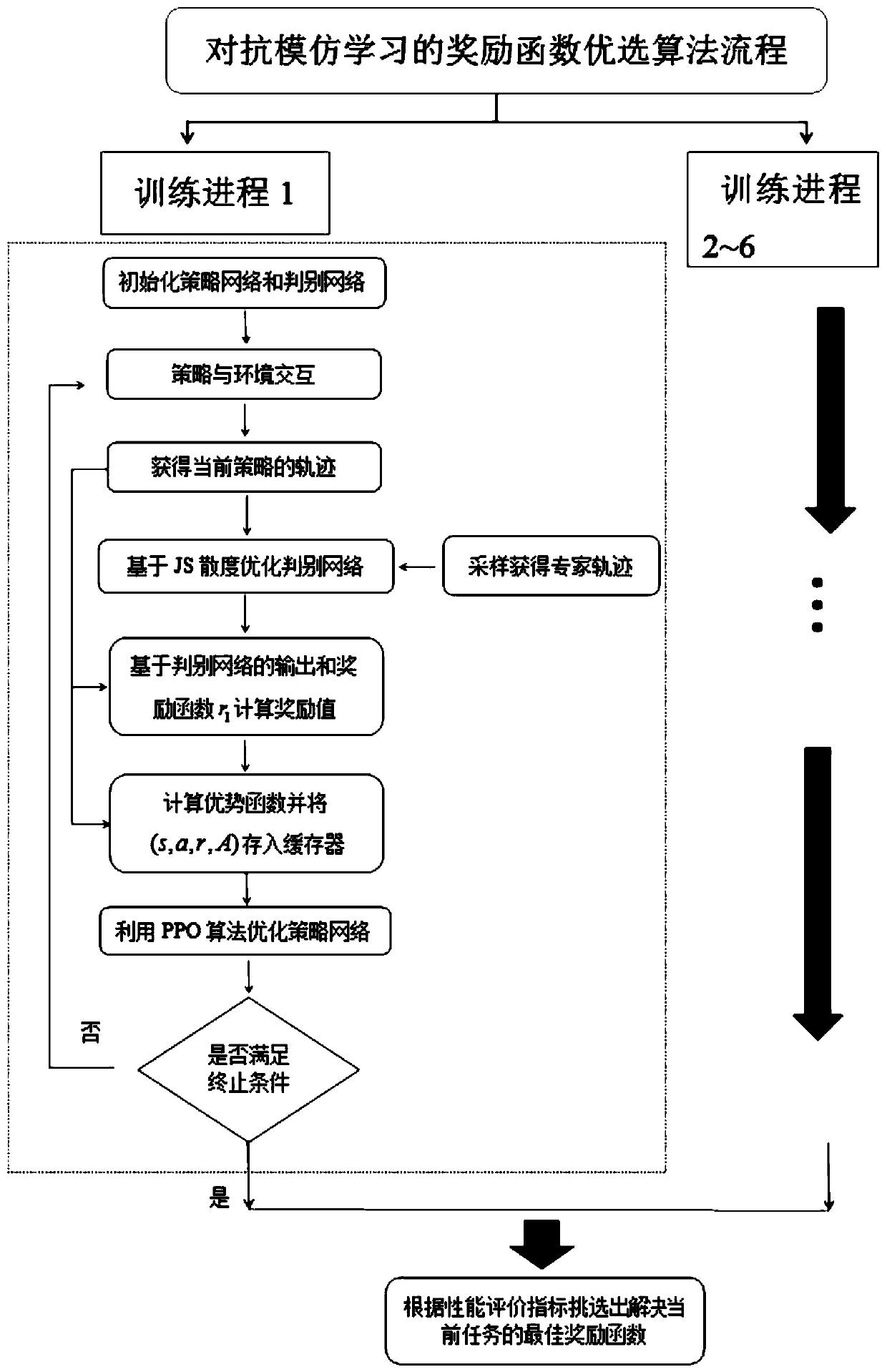
[0047] In order to make the technical problems, technical solutions and beneficial effects to be solved by the embodiments of the present invention clearer, the present invention will be further described in detail below in conjunction with the accompanying drawings and embodiments. It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the present invention.
[0048] It should be noted that when an element is referred to as being “fixed” or “disposed on” another element, it may be directly on the other element or be indirectly on the other element. When an element is referred to as being "connected to" another element, it can be directly connected to the other element or indirectly connected to the other element. In addition, the connection can be used for both fixing function and circuit communication function.
[0049] It is to be understood that the terms "length", "width", "top", "bottom", "front"...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More