

Speech recognition model training method, speech recognition method and related devices
A speech recognition model and training method technology, applied in the computer field, can solve the problems of small amount of data, poor training of the model, poor generalization, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
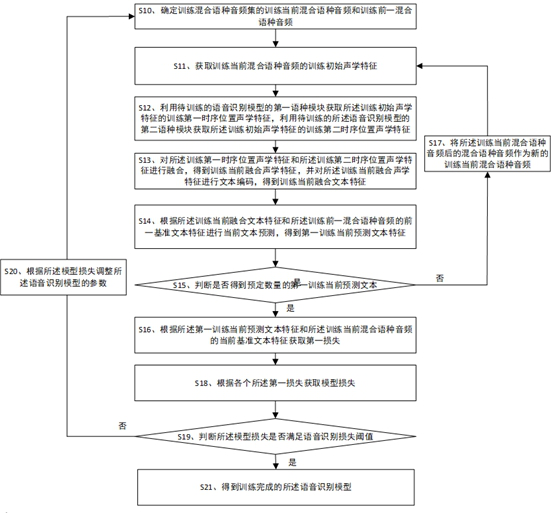
[0036] In the prior art, when speech recognition is performed on text, the accuracy is relatively low.
[0037] In order to improve the accuracy of text speech recognition, an embodiment of the present invention provides a speech recognition model training method, including:
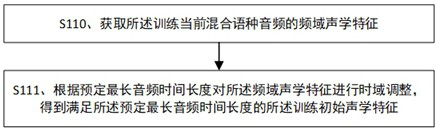
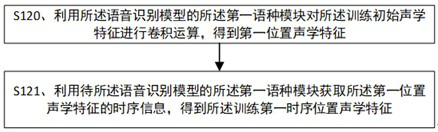
[0038] Determine the training current mixed language audio and the training previous mixed language audio of the training mixed language audio set, obtain the training initial acoustic features of the current mixed language audio, and use the first language module of the speech recognition model to be trained to obtain the training initial acoustic Acoustic features of the first time-series position for feature training, using the second language module of the speech recognition model to be trained to obtain the second time-series position acoustic feature of the training initial acoustic feature, wherein the training current mixed language audio and The mixed language audio before the training includes ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More