

Image text cross-modal retrieval method based on category information alignment
A category information and text technology, applied in the field of image-text cross-modal retrieval based on category information alignment, can solve the problem of insufficient retrieval accuracy of cross-modal retrieval methods
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

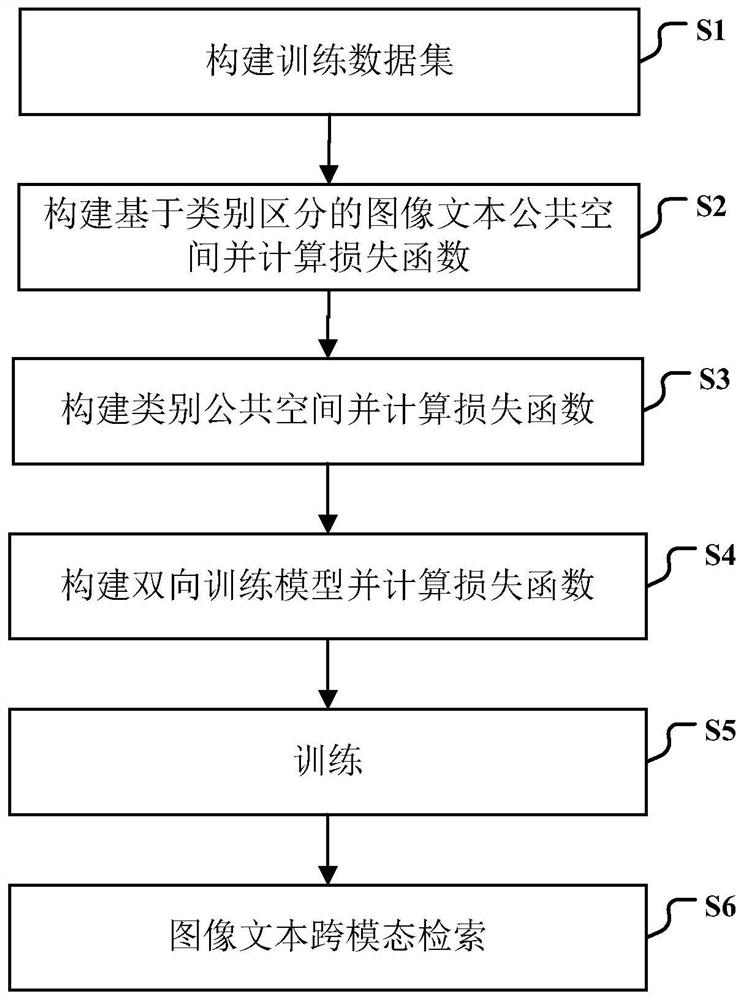
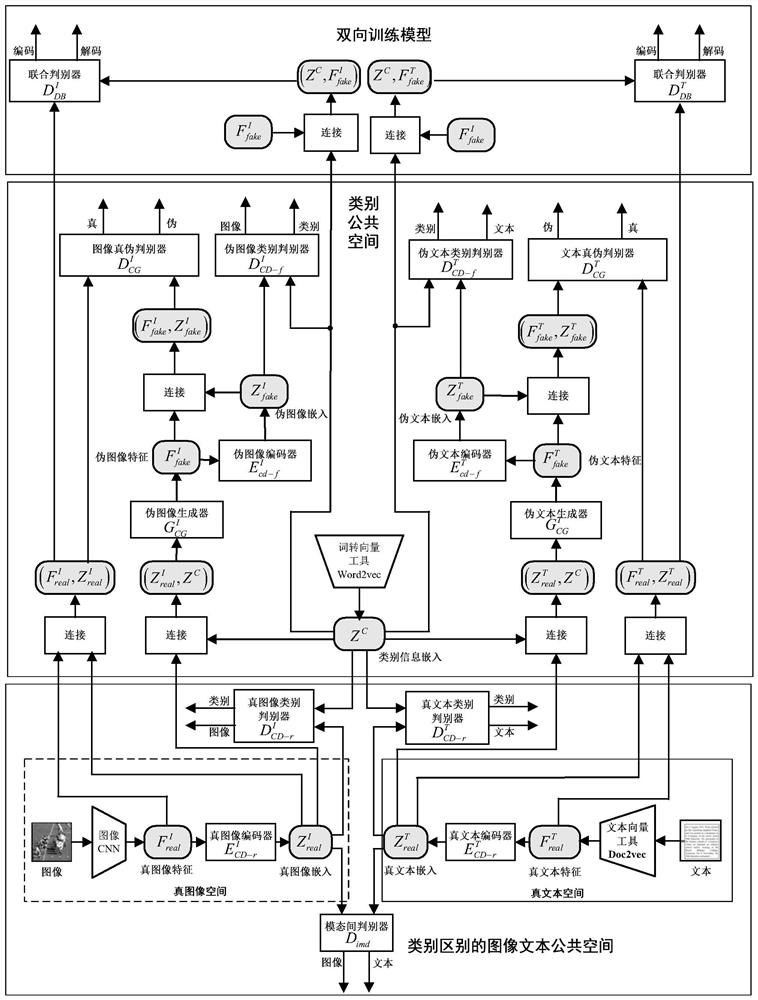
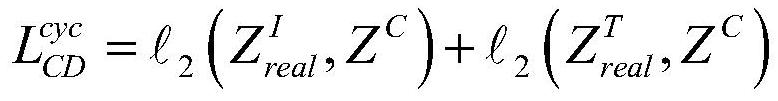
Examples
Embodiment Construction
[0065] Specific embodiments of the present invention will be described below in conjunction with the accompanying drawings, so that those skilled in the art can better understand the present invention. It should be noted that in the following description, when detailed descriptions of known functions and designs may dilute the main content of the present invention, these descriptions will be omitted here.
[0066] In the cross-modal retrieval based on deep learning, the most commonly used cross-modal retrieval is image and text. In the present invention, the image I, the corresponding text T, and the category information C are stored as an image-text pair instance in the training data set, so that N image-text pair instances constitute the training data set. The corresponding real image features (referred to as true image features) and real text features (referred to as true text features) can be expressed as In this embodiment, the true image features In order to utilize ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More