Method for estimating speech speed of multiple speakers based on segmentation and clustering of speakers
A speaker and human language technology, applied in speech analysis, instruments, etc., can solve the problems of not getting multi-speaker speech rate estimation results, unfavorable real-time processing, slow speed, etc., and achieve the effect of saving computing time
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0036] A detailed description will be given below in conjunction with specific embodiments and accompanying drawings.
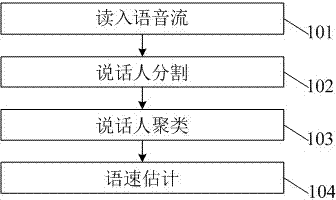
[0037] figure 1 is a flowchart of a method for estimating speech rates of multiple speakers according to an embodiment of the present invention. Such as figure 1 As shown, first in step 101, the voice stream is read. The voice stream is voice data that records the voices of multiple speakers, and can be files in various formats, such as WAV, RAM, MP3, VOX, etc.
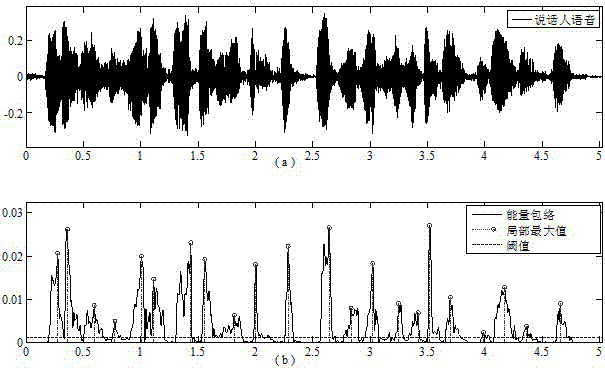
[0038] Then, in step 102, use the silence detection method based on the threshold judgment to find out the silence segment and the speech segment in the speech stream, splice the above speech segments into a long speech segment in order, and extract audio features from the long speech segment, using The audio features extracted above, according to the Bayesian information criterion, judge the similarity between adjacent data windows in the long speech segment to detect the speaker change point; fi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com