

Method for discovering compound words in specific field based on statistics and rules
A field-specific compound word technology, applied in the field of computer natural language processing, can solve problems such as compound word recognition that cannot be solved well, and achieve the effect of reducing depth search, improving accuracy, and reducing CPU and memory space-time overhead
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
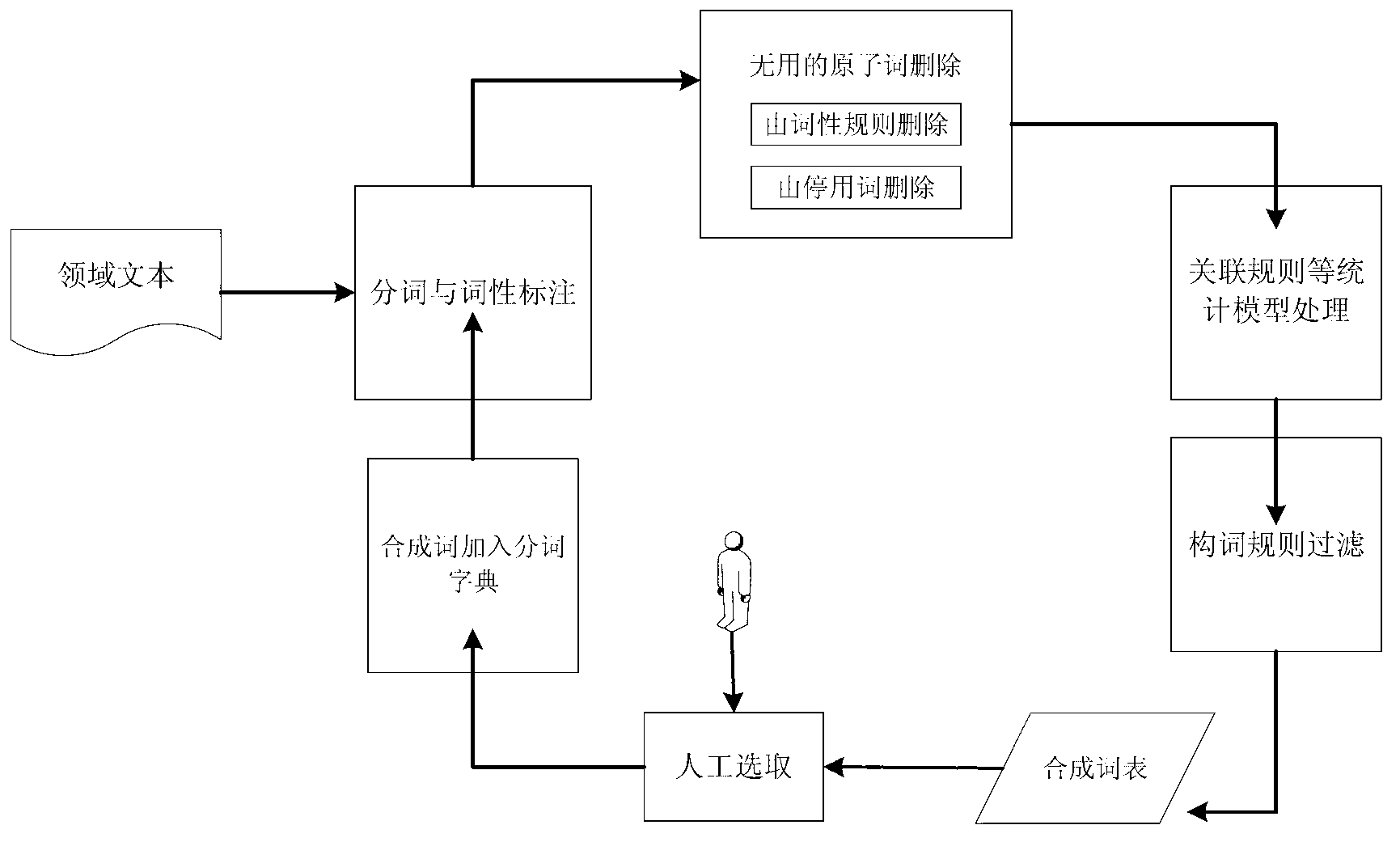
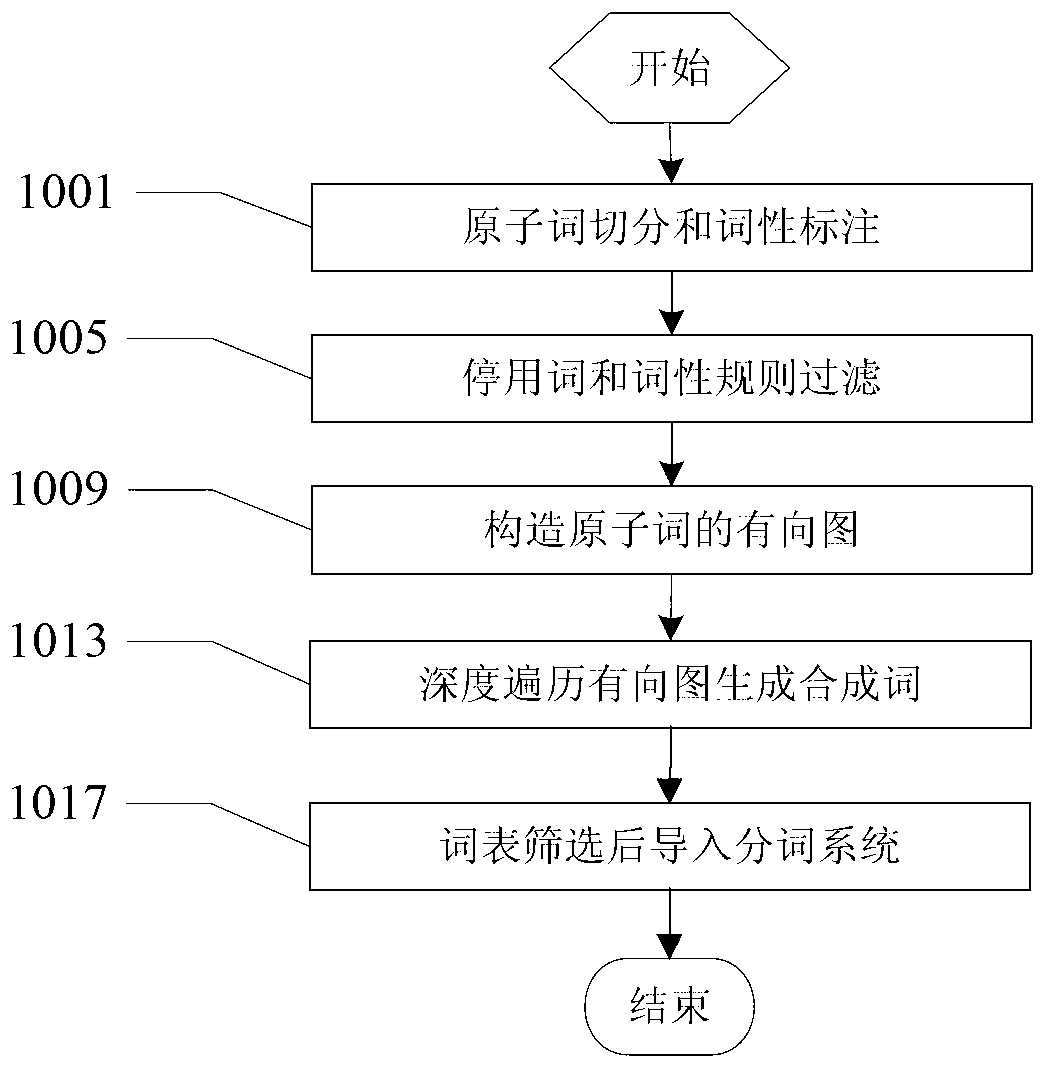
[0047] as attached figure 1 Shown is a structural diagram of the present invention, a compound word discovery method based on statistics and rules in a specific field, and its steps are:
[0048] A. Use the existing word segmentation system to perform atomic word segmentation and part-of-speech tagging on domain texts;
[0049] B. Use stop words and word formation rules to filter and delete atomic words that cannot form compound words;
[0050] C. Forward traversing the processed atomic words, constructing a directed graph containing the atomic word combination relationship, the directed graph is marked as G: , where V refers to the atomic word set in the text, and E corresponds to V The set of atomic words adjacent to the atomic word of ;
[0051] D. Use the deep traversal algorithm to search the directed graph to find all possible combinations of compound words, and at the same time use statistical indicators and word formation rules to judge the conditions of word formati...
Embodiment 2
[0055] The difference from Embodiment 1 above is that furthermore, the word segmentation system described in step A uses the ICTCLAS4J version, which can be directly deployed on a computer or perform word segmentation operations through a compiler call interface. as attached image 3 shown, which is attached figure 2 The processing flowchart of the middle block 1001 illustrates an embodiment of calling the ICTCLAS4J word segmentation system for initial word segmentation. The process starts at block 2001, selecting and importing domain texts, and the domain texts are centrally placed in a folder on the hard disk. In block 2005, the interface of the word segmentation system is invoked to segment and part-of-speech tag the domain text. In block 2009, the word segmentation result is saved in memory.
Embodiment 3
[0057] What is different from the above-mentioned embodiment 1 is that, furthermore, the stop words described in step B come from a stop word table composed of a plurality of Chinese characters, and this table is stored as a txt file on the hard disk memory of the computer, and can be read directly during use. call into memory.
[0058] The word formation rules described in step B include: Rule 1: numerals, pronouns, prepositions, auxiliary words, function words, conjunctions and other parts of speech do not form compound words; Rule 2: single-character words or nouns followed by numerals do not form compound words ;Rule 3: Words that already have complete meanings cannot form compound words; Rule 4: Some words can only be used as prefixes; Rule 5: Some words can only be used as suffixes; Rule 6: Compound words must contain at least one verb, noun or nominal components; Rule 7: The last word of a compound word is a verb, noun or nominal component.
[0059] Figure 4 for fi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More