

Massive document distribution searching duplication removing system and method
A distributed and document technology, applied in the field of information processing, can solve the problems of low efficiency and large amount of calculation of massive document sorting technology, and achieve the effect of reducing the amount of calculation, large semantic contribution, and high word frequency in document sorting and sorting.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
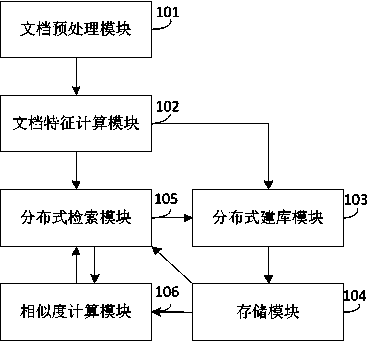
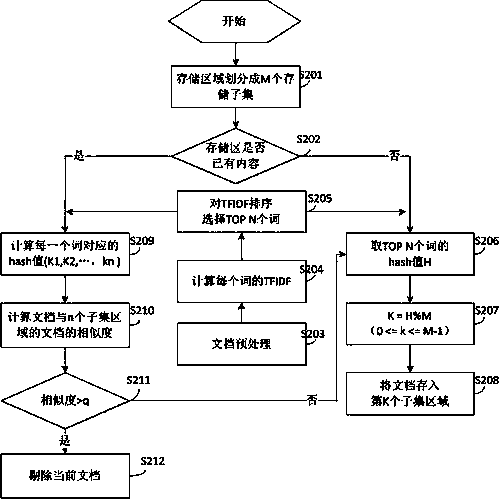
[0020] In order to adapt to the development of the big data era and solve the problems existing in the existing technology, the distributed retrieval and deduplication system and method for massive documents provided by the embodiment of the present invention, with the help of the distributed system idea, uses the fingerprint hash value to evenly distribute the massive documents to Several subset storage areas allow the document similarity calculation to run on one or several subsets, which greatly reduces the amount of computation and meets the efficiency requirements of massive document deduplication.
[0021] In order to make the purpose, technical method, and advantages of the embodiments of the present invention clearer, the technical solutions provided by the embodiments of the present invention will be described in detail below in conjunction with the accompanying drawings.
[0022] Such as figure 1 Shown is a module diagram of the distributed retrieval and ranking syst...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More