

Acoustic model combination method and device, and voice identification method and system
An acoustic model and speech recognition technology, applied in speech recognition, speech analysis, instruments, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
no. 1 example
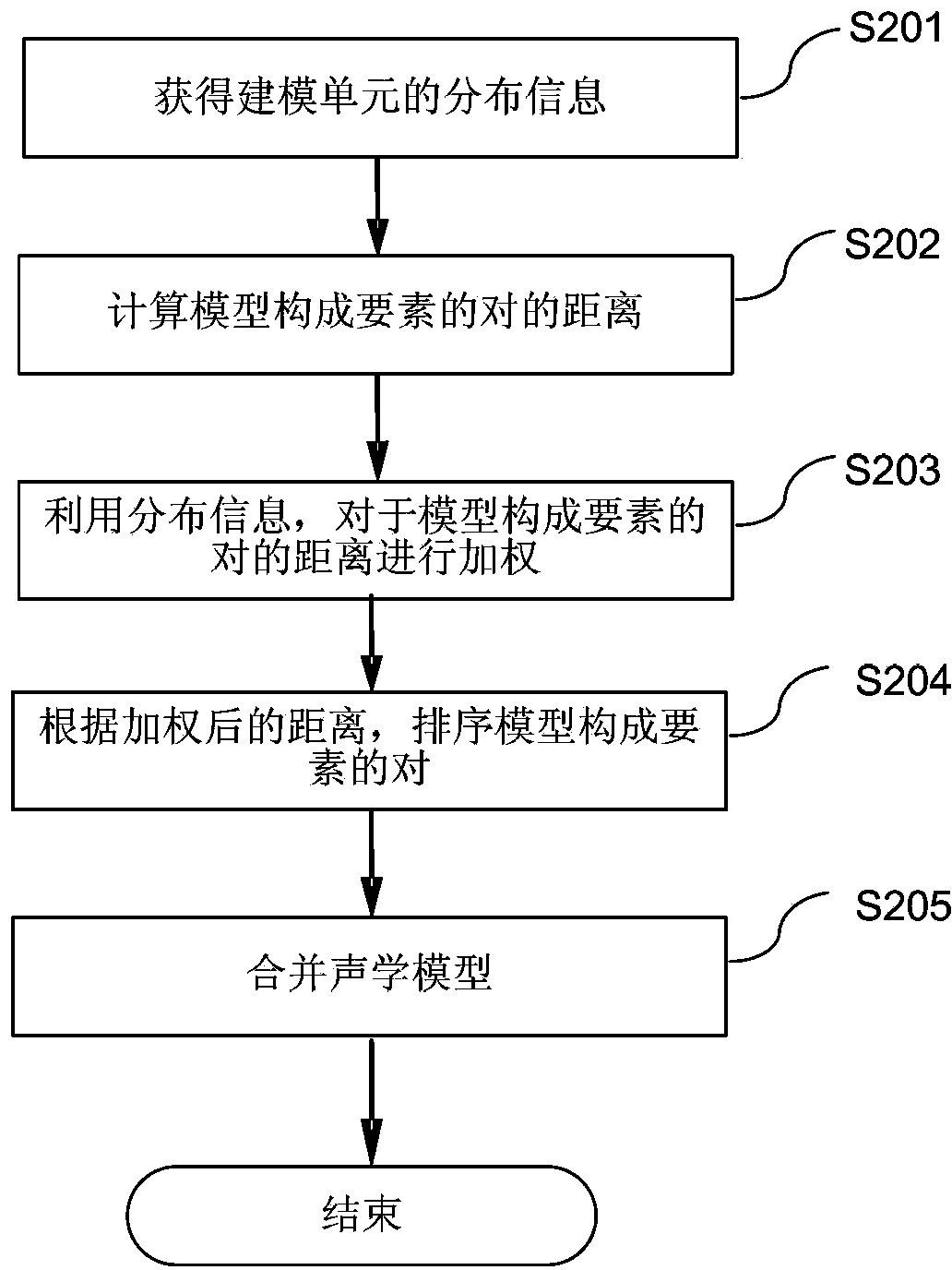
[0059] Below, will refer to figure 2 A first embodiment of the present invention will be described in detail.
[0060] figure 2 A flow chart of an acoustic model merging method according to an embodiment of the present invention is exemplarily shown.
[0061] In this embodiment, the merging operation is performed on the first acoustic model and the second acoustic model. Among them, the first acoustic model and the second acoustic model are based on the speech data in the training library and use such as a training method based on the maximum likelihood rule (Maximum Likelihood, ML) or a discrimination training method (Discriminative Training, DT) and other methods for training. Here, the speech data in the training database is usually provided by one or more native speakers. For example, the first acoustic model (also called universal acoustic model UAM) that can be used as the main acoustic model can be configured to recognize speech input in multiple languages (for ...
no. 2 example
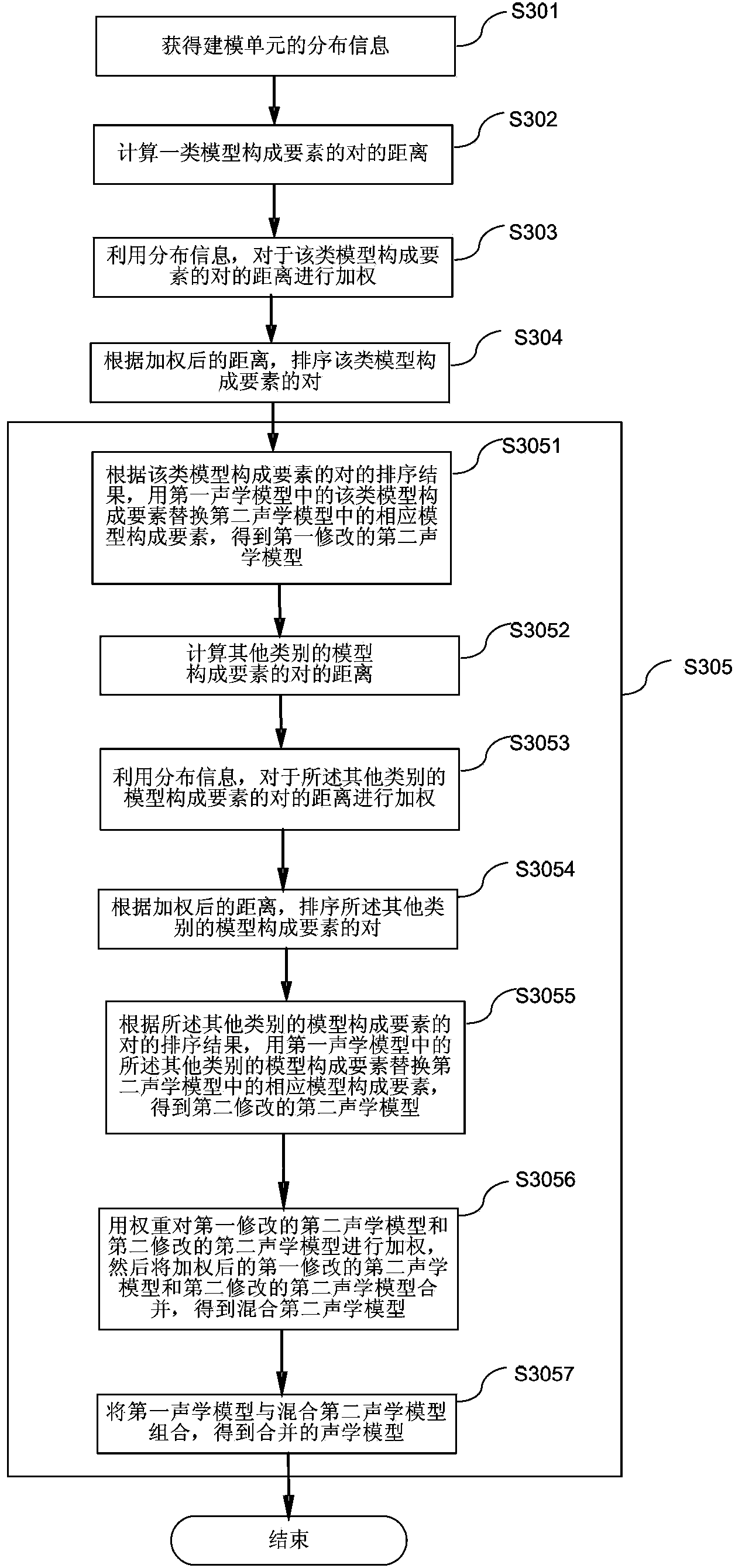
[0094] In the first embodiment, the distance of a pair of model constituent elements composed of one class of model constituent elements of an acoustic model is weighted using distribution information of modeling units, such as state occupancy probabilities, as a weight. The main difference between the second embodiment and the first embodiment is that the distances of pairs of model constituent elements respectively composed of at least two categories of model constituent elements of the acoustic model can be weighted using the distribution information of the modeling units as weights .
[0095] Below, will refer to image 3 A second embodiment of the present invention will be described in detail.
[0096] image 3 A flow chart of an acoustic model merging method according to the second embodiment of the present invention is exemplarily shown.
[0097] First, in step S301, similar to step S201 in the first embodiment, distribution information of modeling units is obtained....
no. 3 example
[0123] In the first and second embodiments, the first acoustic model is combined with the second acoustic model to obtain a bundled acoustic model. The main difference between the third embodiment and the first and second embodiments is that more than two acoustic models can be combined to obtain a bundled acoustic model.
[0124] Below, will refer to Figure 4 A third embodiment of the present invention will be described in detail.
[0125] Figure 4 A flow chart of an acoustic model merging method according to the third embodiment of the present invention is exemplarily shown.
[0126] Figure 4 Steps S401-S405 in the above may be similar to S201-S205 in the first embodiment, or may be similar to S301-S305 in the second embodiment.
[0127] In step S406, other acoustic models different from the first acoustic model and the second acoustic model can still be merged. The merging with the other acoustic models can adopt the method described above in the first embodiment or...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More