A News Classification Method Based on Semantic Analysis and Multiple Cosine Theorem
A technology of cosine theorem and semantic analysis, applied in the field of information processing, can solve the problems of increasing the accuracy of news classification, error-prone classification, and poor flexibility.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
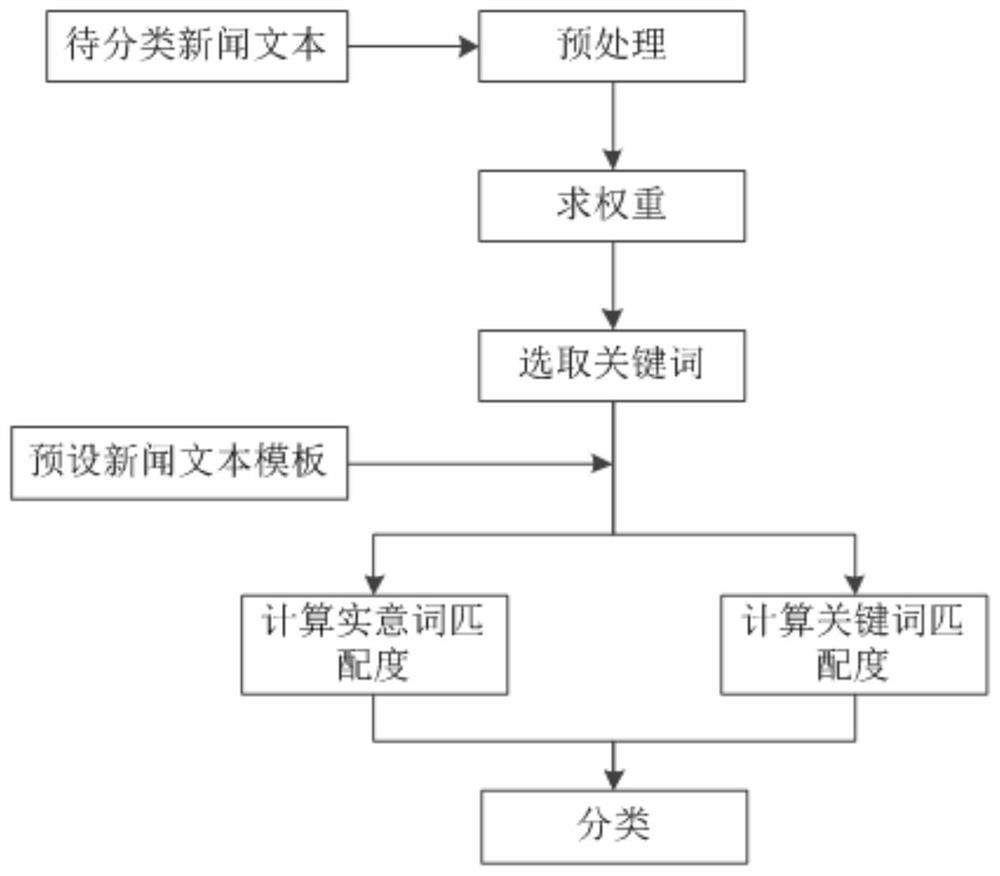
[0042] Embodiment 1: as Figure 1-4 As shown, a news classification method based on semantic analysis and multiple cosine theorem, the specific steps are:
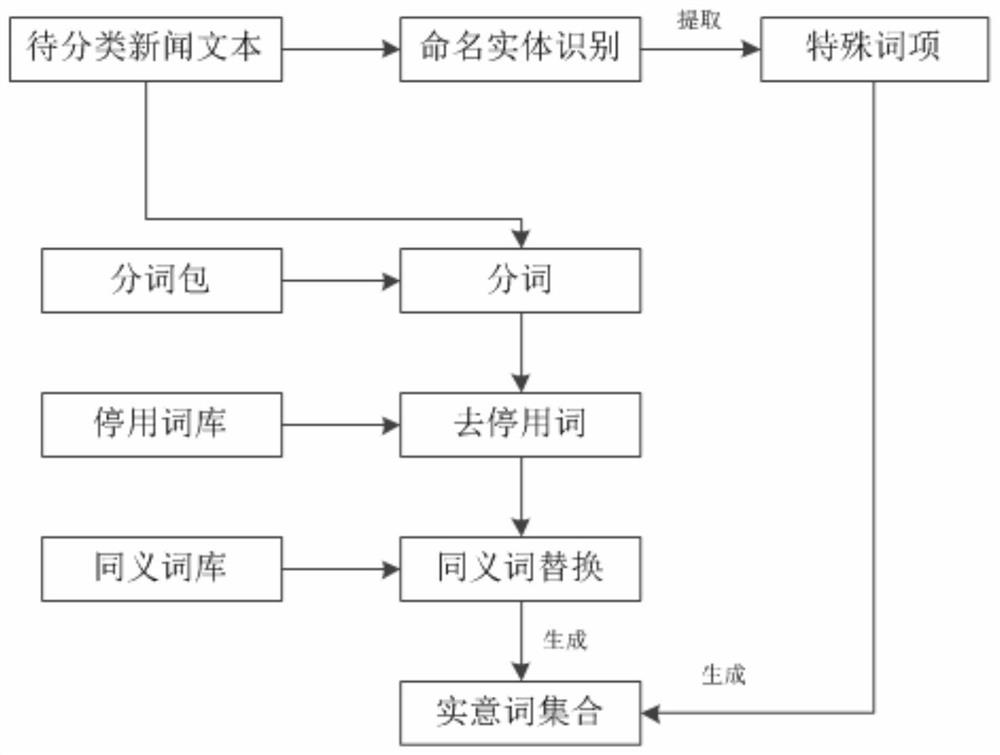
[0043] Step1: Obtain the news text X to be classified, and preprocess the news text X to be classified: first use the named entity recognition technology to select special words in the news text X to be classified, and perform word segmentation, stop words and synonyms on the remaining text Substitution and other operations to generate the substantive word set X of the news text X to be classified:{x 1 ,x 2 … x m}, where, the substantive word set X:{x 1 ,x 2 … x m} contains special terms;
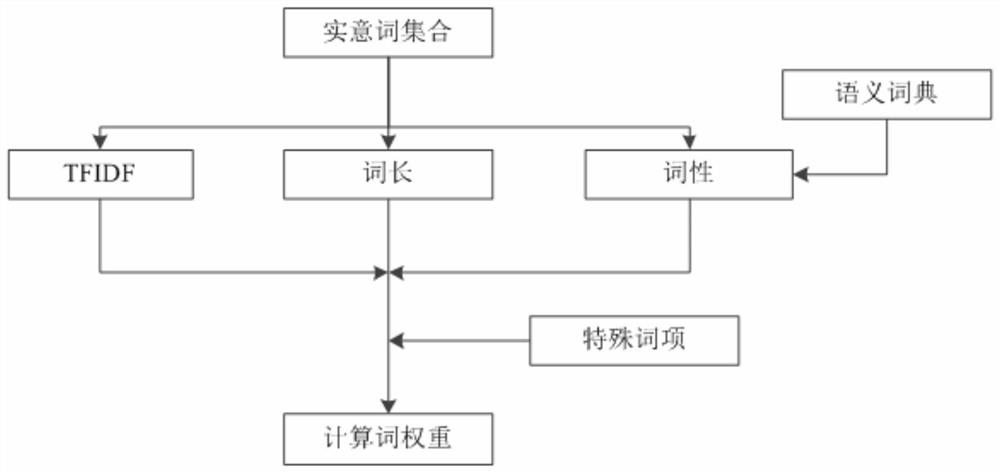
[0044] Step2: Calculating the weight: mainly based on the TFIDF value, supplemented by part of speech and word length, traverse the substantive word set X of the news text X to be classified obtained in Step1:{x 1 ,x 2 … x m}, for each substantive word x i ,i∈[1,m] to find its weight, and generate a weight set Y of substantive...
Embodiment 2
[0076] Embodiment 2: as Figure 1-4 As shown, on the basis of Example 1, for most text similarity measurement methods, some special terms such as personal names, place names, organization names, professional terms, etc. will be ignored, because these special terms do not provide valid information. But the present invention thinks that these special terms such as person's name, place name, organizational structure name, professional term are the important index that weighs what category a news text belongs to. For example, if words such as the names of national leaders often appear in a news text, it can be basically determined that the news text should belong to the political category without browsing the full text. For another example, if some vocabulary such as the names of athletes often appear in a news text, it can be basically determined that the news text should belong to the sports category without browsing the full text. This is also the reason why the present invent...
Embodiment 3
[0077] Embodiment 3: as Figure 1-4 As shown, on the basis of Embodiment 1, the present invention also uses word length as an indicator for weighing word weight. According to research, the length of Chinese words obeys the χ under certain conditions 2 Distribution, that is to say, the longer the vocabulary, the less likely it is to appear in the text, which also determines that the longer the vocabulary has a good class discrimination ability. For example, if words such as "People's Republic of China" appear in a news text, you can basically confirm that the news text should belong to the category of international news without browsing the full text, because most domestic news uses the abbreviation "China" instead of "People's Republic of China" .
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com