

Modeling and controlling method for synchronizing voice and mouth shape of virtual character
A virtual character and modeling method technology, applied in the field of speech synthesis, can solve the problems of relying on data volume and labeling, and achieve the effects of small labeling workload, strong interpretability, and clear physical meaning of the model
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0039] Embodiments of the invention will be described below, but it should be appreciated that the invention is not limited to the described embodiments and that various modifications of the invention are possible without departing from the basic idea. The scope of the invention is therefore to be determined only by the appended claims.
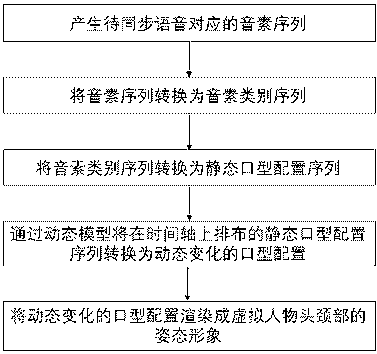
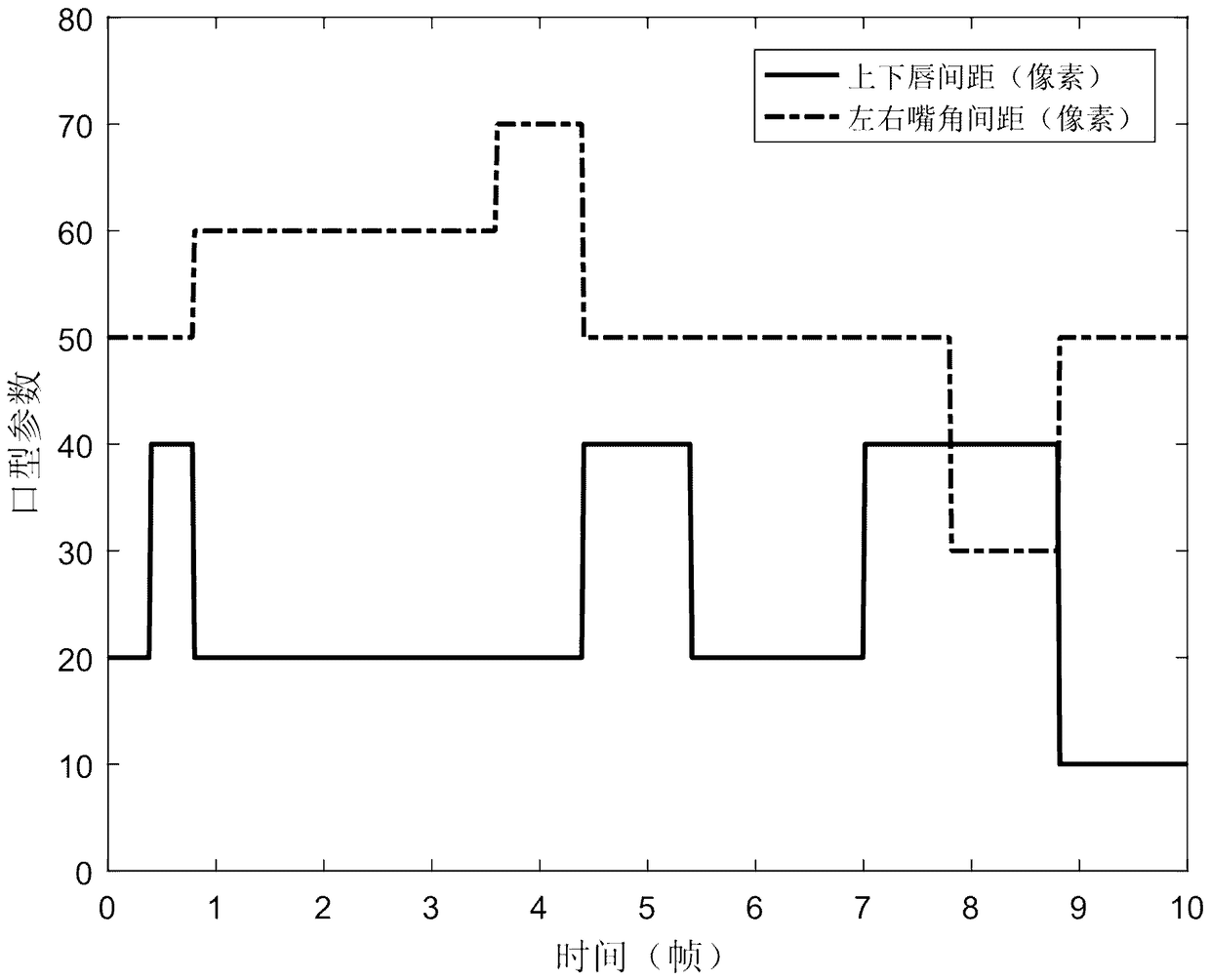
[0040] Such as figure 1 As shown, a mouth shape modeling method includes the following steps:
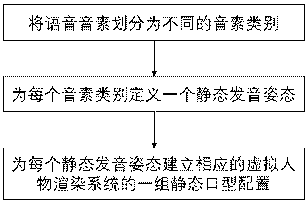
[0041] Step 1: Divide the speech phonemes into different phoneme categories.
[0042] Generally, phonemes can be divided into vowel phonemes and consonant phonemes; for vowel phonemes, vowel phonemes are divided into several vowel phoneme categories according to opening degree and lip shape; for consonant phonemes, consonant phonemes are divided into several consonant phoneme categories according to the articulation position phoneme category. The method classifies phonemes based on their pronunciation features, which are attributes that are univ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More