

Construction method, system, device and storage medium of named entity recognition corpus
A technology for named entity recognition and named entities, which is applied in the creation of semantic tools, natural language data processing, and unstructured text data retrieval. To achieve the effect of wide coverage, wide coverage and wide application
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0041] The following will clearly and completely describe the technical solutions in the embodiments of the present invention in conjunction with the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only some of the embodiments of the present invention, not all of them. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
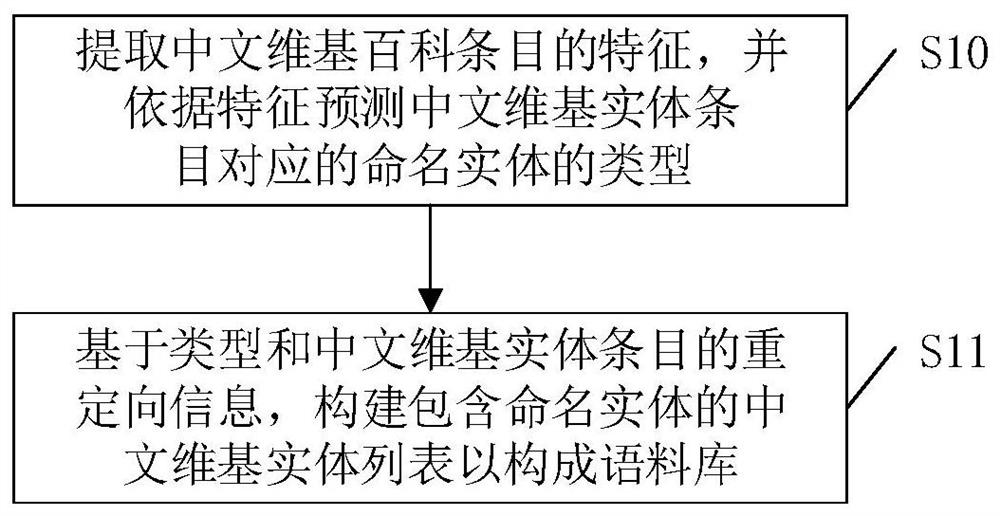
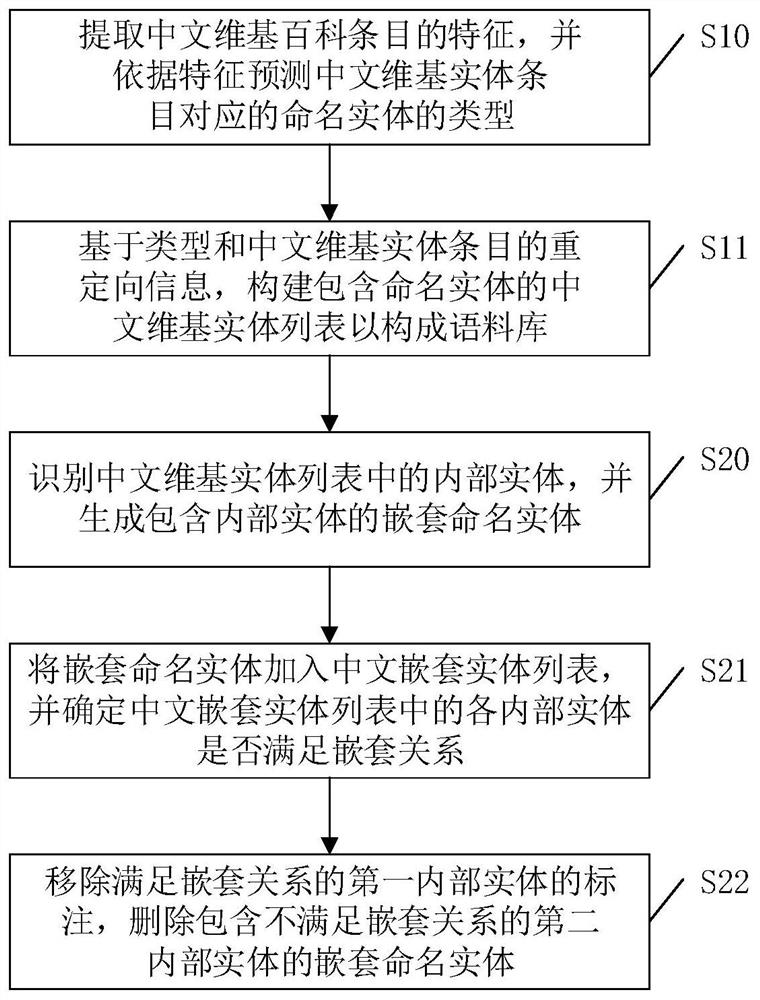
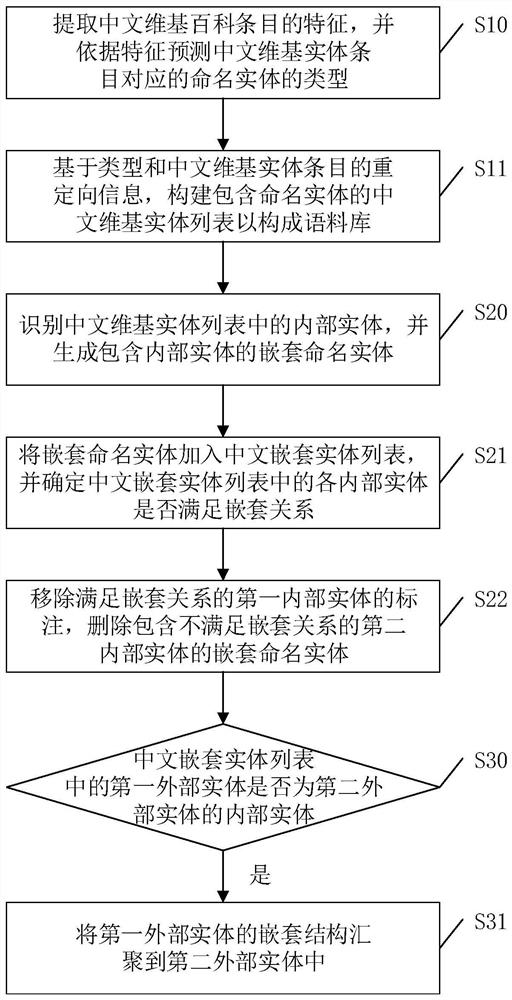
[0042] The purpose of the present invention is to provide a named entity recognition corpus construction method, system, equipment and storage medium, which can automatically construct a Chinese named entity recognition corpus with the advantages of rich content and wide application fields.
[0043] In order to enable those skilled in the art to better understand the technical solution of the present invention, the present invention will be furt...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More