

Classification method and device
A classification method and target classification technology, applied in the computer field, can solve the problems of non-representation and low accuracy of classification results, and achieve the effect of high reference value
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

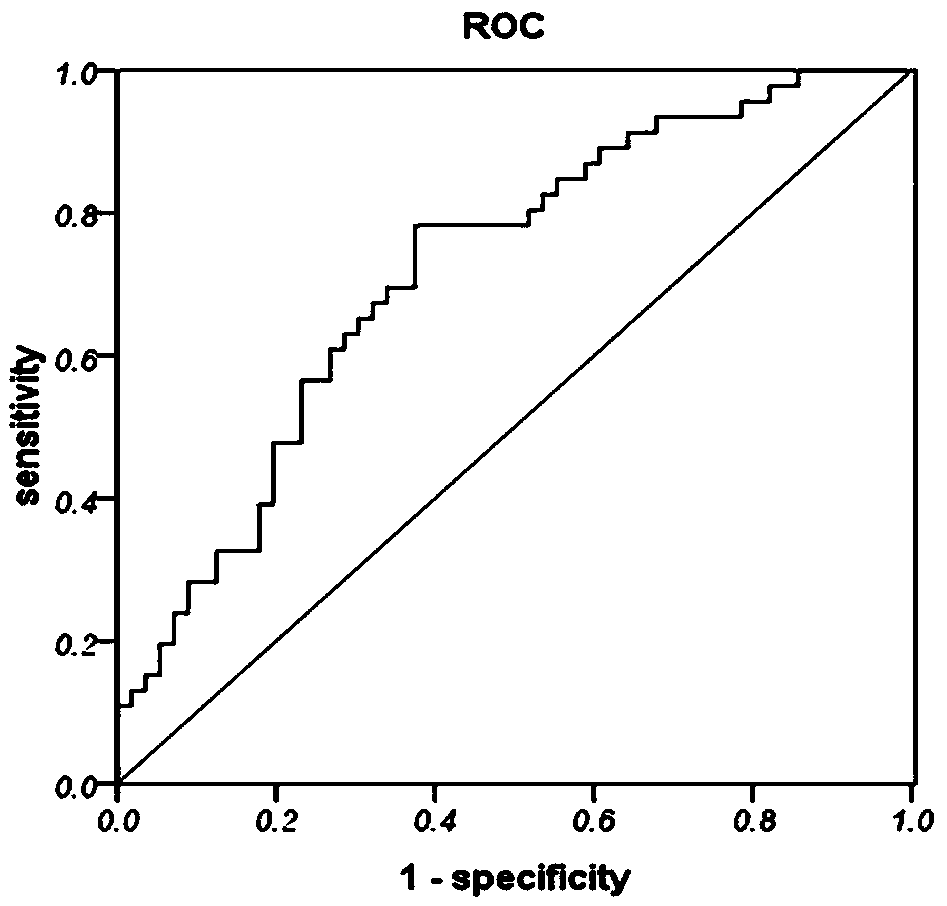

Examples
Embodiment Construction
[0071] In order to enable those skilled in the art to better understand the solutions of the present application, the technical solutions in the embodiments of the present application will be clearly and completely described below in conjunction with the drawings in the embodiments of the present application.
[0072] Some processes described in the specification, claims, and above-mentioned drawings of the present application contain multiple operations appearing in a specific order, and these operations may not be executed in the order in which they appear herein or executed in parallel. The serial numbers of the operations, such as 101, 102, etc., are only used to distinguish different operations, and the serial numbers themselves do not represent any execution order. Additionally, these processes can include more or fewer operations, and these operations can be performed sequentially or in parallel. It should be noted that the descriptions of "first" and "second" in this a...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More