

Lightweight distraction judging method based on deep learning face recognition
A facial recognition and deep learning technology, applied in the field of deep learning image recognition and analysis, can solve the problems of lack of model performance, scarcity of data set network models, and inapplicability to business scenarios, achieving strong practical effects, taking into account real-time and accuracy. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0062] The following will clearly and completely describe the technical solutions in the embodiments of the present invention with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only some, not all, embodiments of the present invention. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
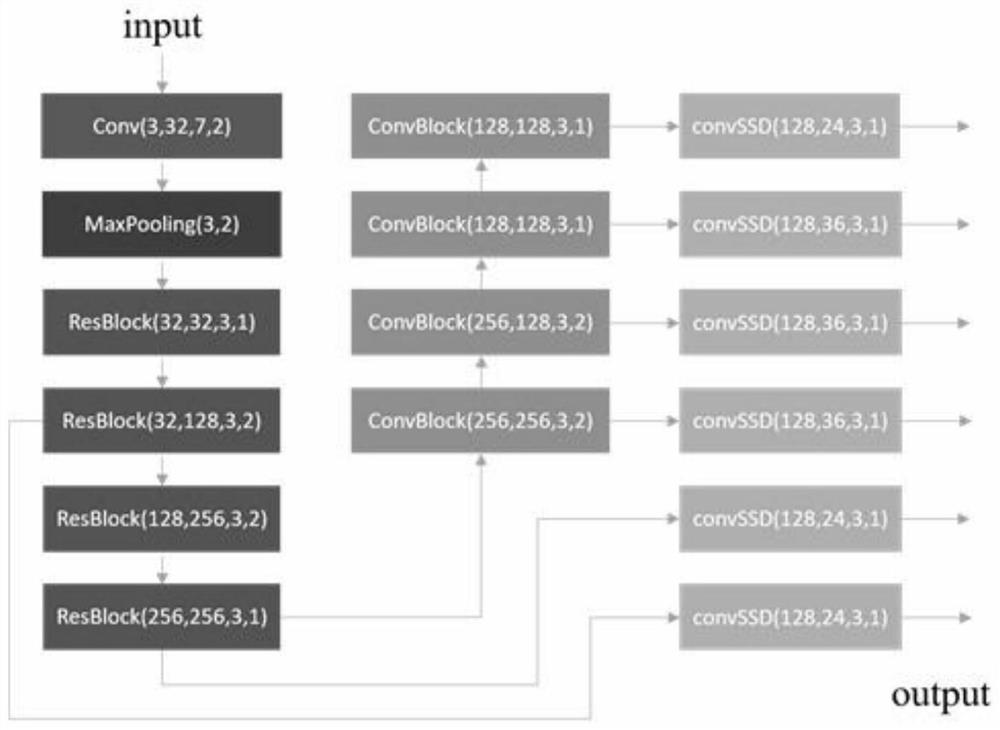
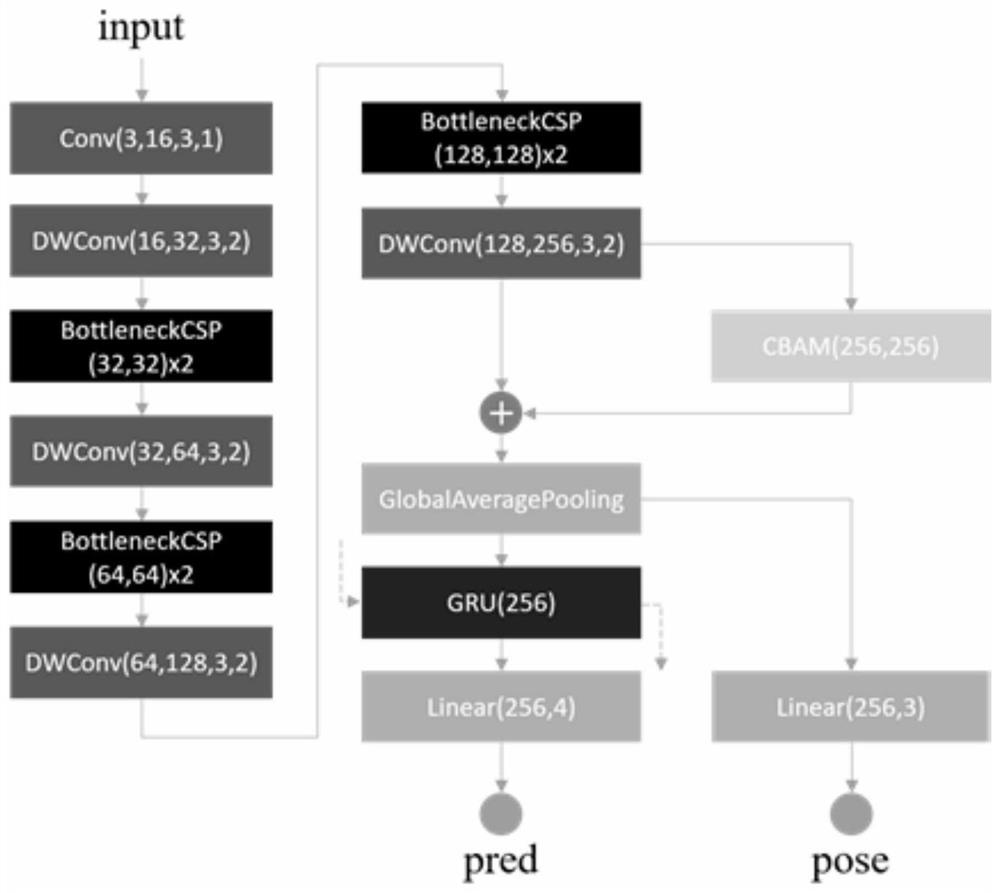
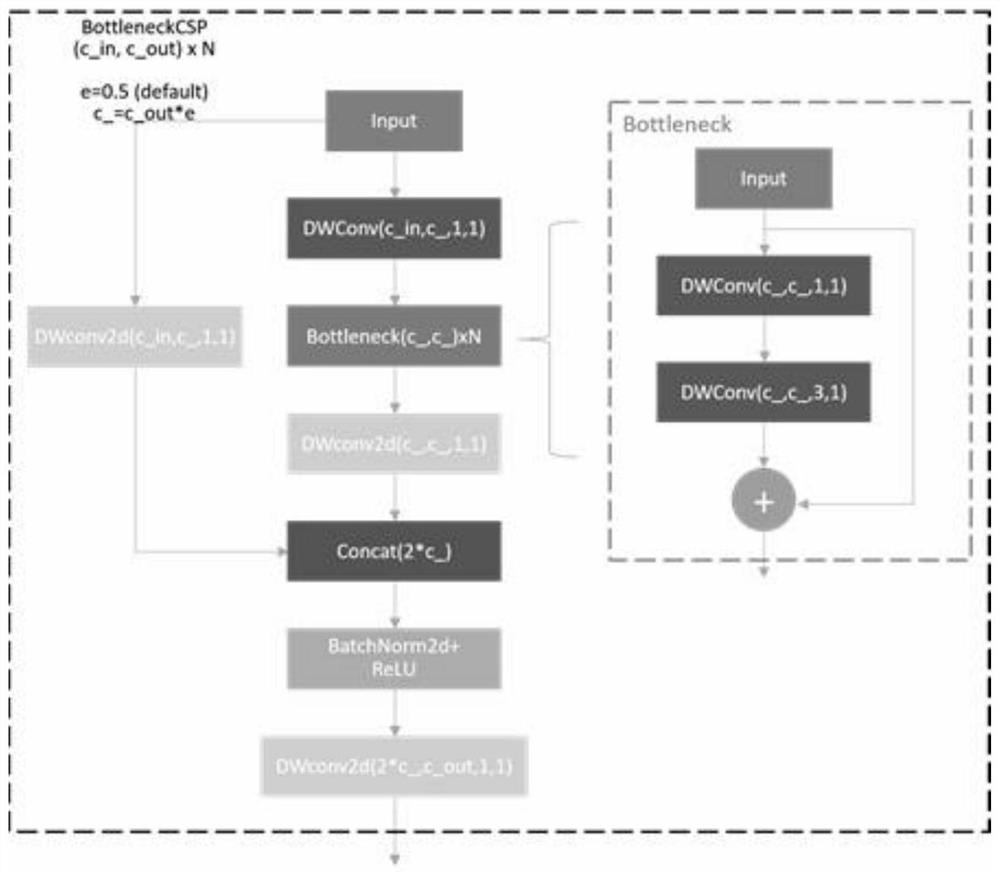
[0063] see Figure 1-8 , the present invention provides the following technical solutions:
[0064] A lightweight mind-wandering discrimination method based on deep learning facial recognition, comprising the following steps:
[0065] S1: Use the face detection algorithm based on ResNet10-SSD to perform face detection on the key frames in the video stream. The face detection module selects ResNet10 as the skeleton, extracts the depth features of the input im...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More