

Unmanned ship environment intelligent sensing method based on deep learning
A technology of intelligent perception and deep learning, which is applied in the field of environmental perception of unmanned ships, can solve the problems such as the inability to achieve feasible channel segmentation, and achieve the effect of taking into account real-time and accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

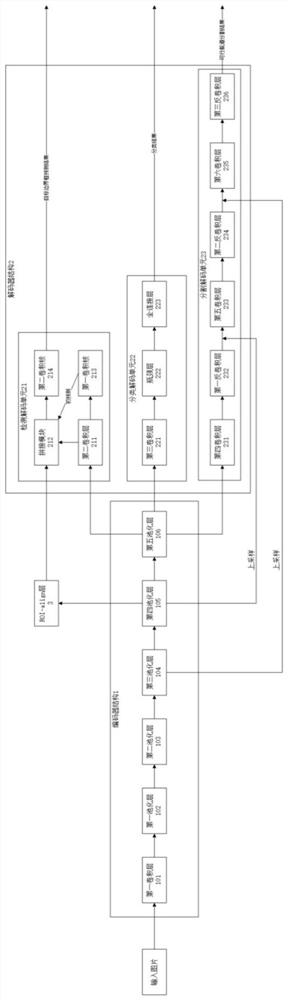
Examples
Embodiment Construction
[0039] The following will clearly and completely describe the technical solutions in the embodiments of the present invention with reference to the drawings in the embodiments of the present invention. Obviously, the described embodiments are part of the embodiments of the present invention, not all of them. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts shall fall within the protection scope of the present invention.
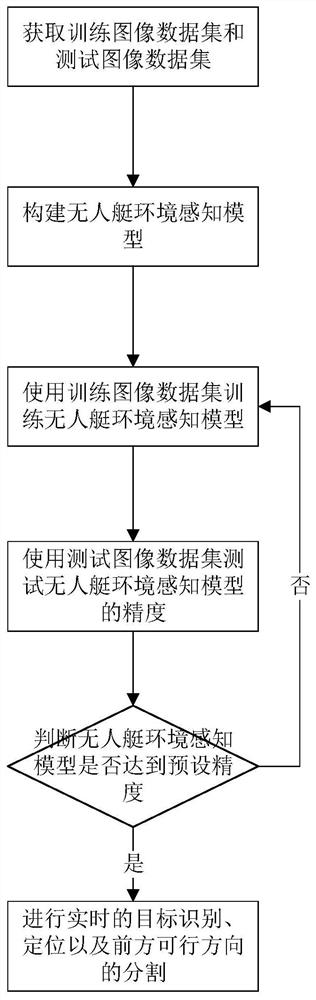
[0040] A deep learning-based intelligent perception method for the environment of unmanned boats, the process of which is as follows figure 1 shown, including:
[0041] Step 1: Obtain training image dataset and test image dataset;
[0042] Step 2: Construct the environment perception model of the unmanned vehicle;
[0043] Step 3: Use the training image data set to train the UAV environment perception model;
[0044] Step 4: Use the test image data set ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More