

Adaptive information extraction method for webpage characteristics
A technology of information extraction and web page features, applied in special data processing applications, instruments, calculations, etc., can solve the problem that extraction tasks cannot achieve high accuracy, and achieve high accuracy, strong scalability, and simple expansion process Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
example
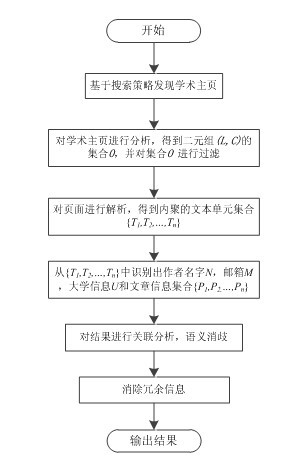
[0089] Take from the academic home page http: / / www.cs.uiuc.edu / ~hanj / Take the process of extracting information from . According to the judgment of the search engine, select the first search result to be the academic homepage of the author.
[0090] Use an HTML parser to parse the page, obtain the sub-links, and select the following sub-pages for further analysis according to the link keywords and context:
[0091] http: / / www.cs.uiuc.edu / homes / hanj / pubs / index.htm
[0092] https: / / agora.cs.illinois.edu / display / cs591han / Research+Publications+-+Data+Mining+Research+Group+at+CS%2C+UIUC
[0093] Divide each page to be analyzed into text units. Taking the home page as an example, the following results are obtained:
[0094]
[0095]
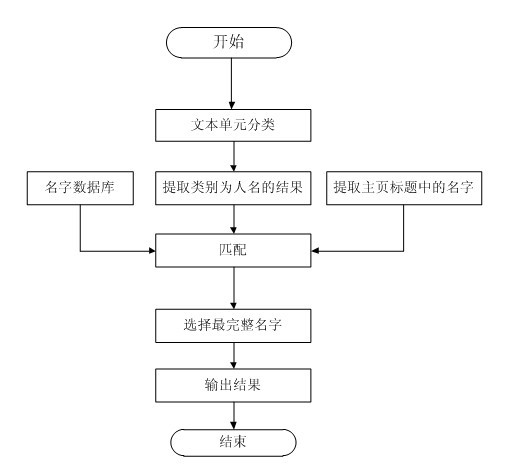
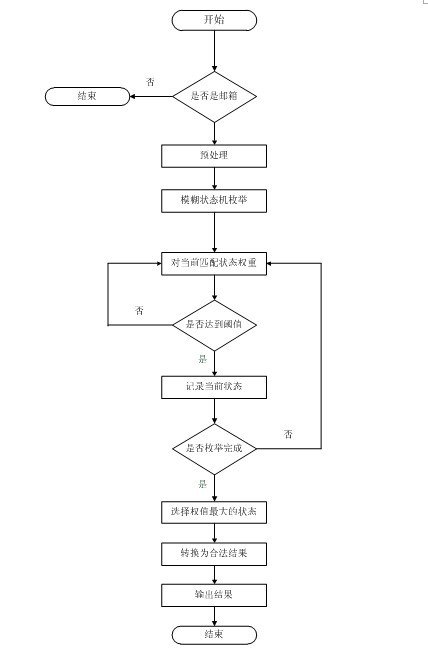
[0096] Use the support vector machine to classify the above text units, and determine them as the author's name, irrelevant data, university information, email address, and article information. According to the determined category, further ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More