

Webpage extraction method based on attribute reproduction and labeled path
A technology of labeling paths and attributes, applied in special data processing applications, instruments, electrical digital data processing, etc., can solve problems such as insufficient reproducible entities and insufficient template abstraction.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
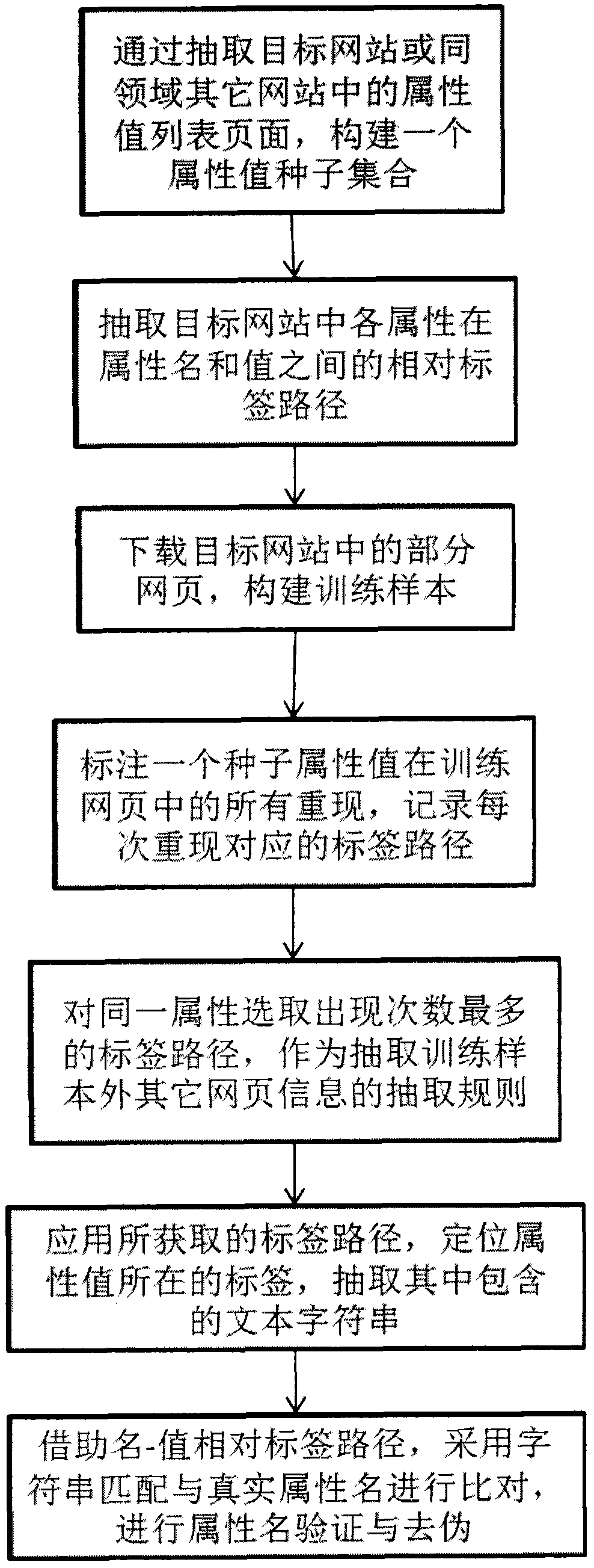
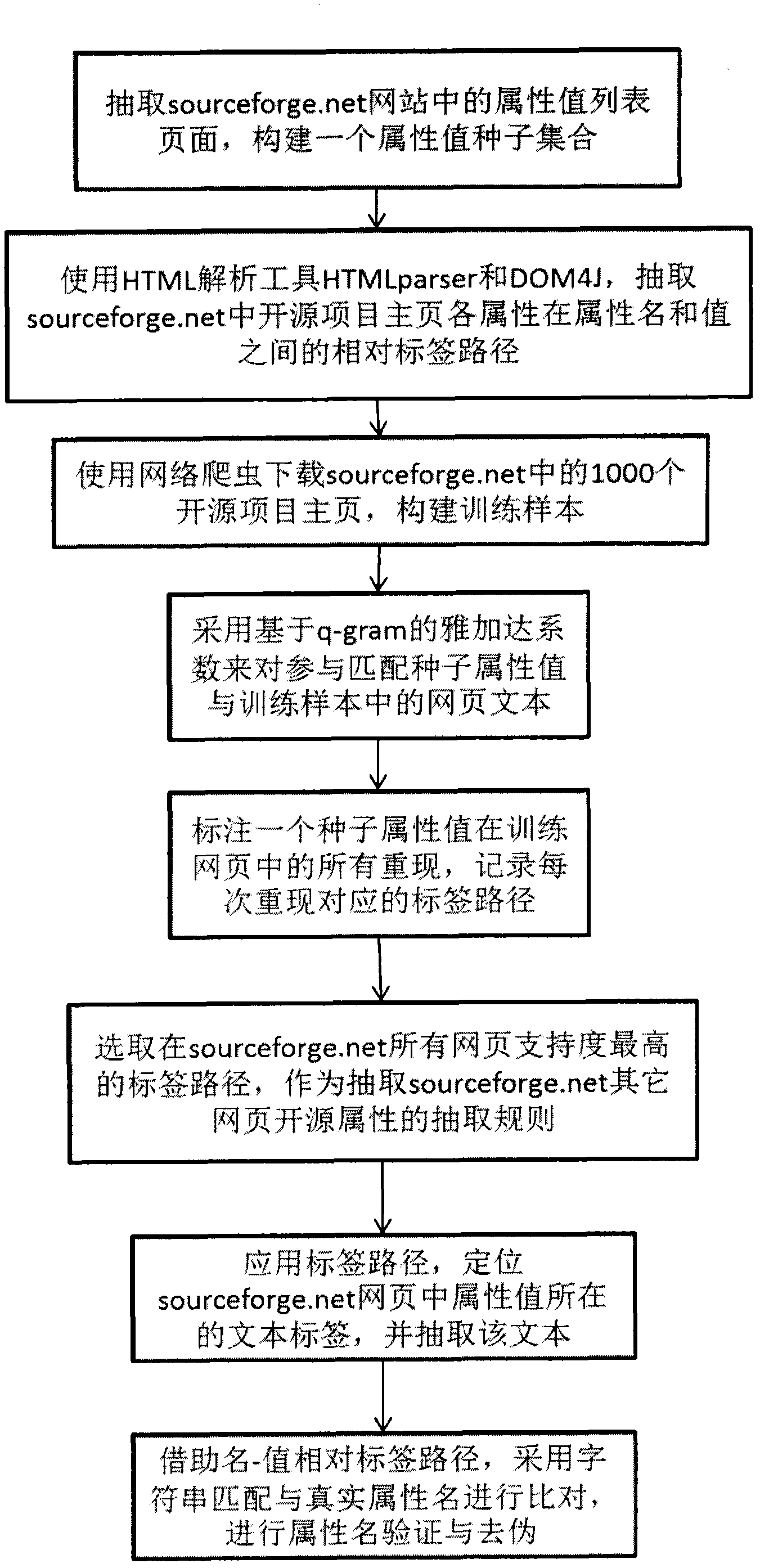
[0022] Such as figure 1 As shown, it is a flowchart of the realization of the open source software acquisition and search system and method, and specifically implements the following steps:
[0023] Step 1. Build a seed collection. By extracting the attribute value list pages of the target website or other websites in the same field, an attribute value seed set is constructed, which contains some values of the target attribute.
[0024] More and more websites support exploratory search, which combines query and browsing in the process of searching on the web. Compared with typical keyword search, exploratory search provides users with a hierarchical and multi-dimensional browsing option, especially for users who do not have a clear search goal, exploratory search provides a way to search while specifying needs The way. On the exploratory search page, the attributes of the searched entity are usually displayed in a list of hyperlinks, such as figure 1 As shown, the attrib...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More