

Sparse representation based short-voice speaker recognition method
A technology of speaker recognition and sparse representation, which is applied in the field of short speech speaker recognition based on sparse representation, and can solve the problems that the speaker model cannot effectively improve the recognition accuracy and semantic information mismatch.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
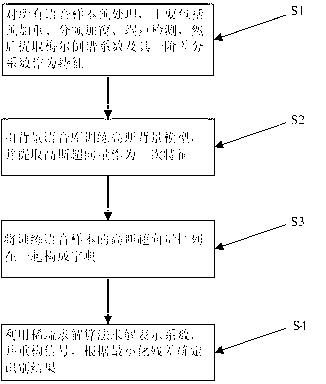
[0052] Such as figure 1 As shown, a short speech speaker recognition method based on sparse representation includes the following steps:
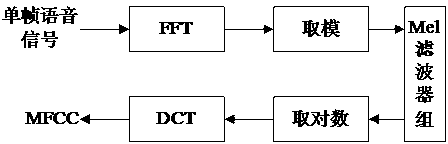
[0053] Step 1: Pre-processing all voice samples, mainly including pre-emphasis, frame windowing, endpoint detection, and then extract MFCC and its first-order difference coefficients as features;
[0054] Step 2: Train the Gaussian background model from the background speech database, and extract the Gaussian supervector as the secondary feature;
[0055] Step 3: Arrange the Gaussian supervectors of the training speech samples together to form a dictionary;
[0056] Step 4: Use the sparse solution algorithm to solve the representation coefficient, reconstruct the signal, and determine the recognition result according to the minimized residual.
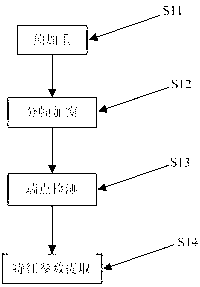
[0057] In such figure 2 As shown, the first step includes steps S11, S12, S13, and S14, which are specifically described as follows:
[0058] S11: Pre-emphasis, high-frequency speech signal is an indispensab...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More